People have an innate capacity to course of uncooked visible alerts from the retina and develop a structured understanding of their environment, figuring out objects and movement patterns. A significant purpose of machine studying is to uncover the underlying ideas that allow such unsupervised human studying. One key speculation, the predictive characteristic precept, means that representations of consecutive sensory inputs ought to be predictive of each other. Early strategies, together with sluggish characteristic evaluation and spectral methods, aimed to take care of temporal consistency whereas stopping illustration collapse. Newer approaches incorporate siamese networks, contrastive studying, and masked modeling to make sure significant illustration evolution over time. As a substitute of focusing solely on temporal invariance, fashionable methods practice predictor networks to map characteristic relationships throughout completely different time steps, utilizing frozen encoders or coaching each the encoder and predictor concurrently. This predictive framework has been efficiently utilized throughout modalities like photographs and audio, with fashions resembling JEPA leveraging joint-embedding architectures to foretell lacking feature-space info successfully.
Developments in self-supervised studying, significantly by imaginative and prescient transformers and joint-embedding architectures, have considerably improved masked modeling and illustration studying. Spatiotemporal masking has prolonged these enhancements to video information, enhancing the standard of discovered representations. Moreover, cross-attention-based pooling mechanisms have refined masked autoencoders, whereas strategies like BYOL mitigate illustration collapse with out counting on handcrafted augmentations. In comparison with pixel-space reconstruction, predicting in characteristic area permits fashions to filter out irrelevant particulars, resulting in environment friendly, adaptable representations that generalize effectively throughout duties. Current analysis highlights that this technique is computationally environment friendly and efficient throughout domains like photographs, audio, and textual content. This work extends these insights to video, showcasing how predictive characteristic studying enhances spatiotemporal illustration high quality.
Researchers from FAIR at Meta, Inria, École normale supérieure, CNRS, PSL Analysis College, Univ. Gustave Eiffel, Courant Institute, and New York College launched V-JEPA, a imaginative and prescient mannequin skilled solely on characteristic prediction for unsupervised video studying. In contrast to conventional approaches, V-JEPA doesn’t depend on pretrained encoders, detrimental samples, reconstruction, or textual supervision. Educated on two million public movies, it achieves sturdy efficiency on movement and appearance-based duties with out fine-tuning. Notably, V-JEPA outperforms different strategies on One thing-One thing-v2 and stays aggressive on Kinetics-400, demonstrating that characteristic prediction alone can produce environment friendly and adaptable visible representations with shorter coaching durations.
The methodology entails coaching a basis mannequin for object-centric studying utilizing video information. First, a neural community extracts object-centric representations from video frames, capturing movement and look cues. These representations are then refined by contrastive studying to boost object separability. A transformer-based structure processes these representations to mannequin object interactions over time. The framework is skilled on a large-scale dataset, optimizing for reconstruction accuracy and consistency throughout frames.
V-JEPA is in comparison with pixel prediction strategies utilizing comparable mannequin architectures and reveals superior efficiency throughout video and picture duties in frozen analysis, apart from ImageNet classification. With fine-tuning, it outperforms ViT-L/16-based fashions and matches Hiera-L whereas requiring fewer coaching samples. In comparison with state-of-the-art fashions, V-JEPA excels in movement understanding and video duties, coaching extra effectively. It additionally demonstrates sturdy label effectivity, outperforming opponents in low-shot settings by sustaining accuracy with fewer labeled examples. These outcomes spotlight some great benefits of characteristic prediction in studying efficient video representations with decreased computational and information necessities.
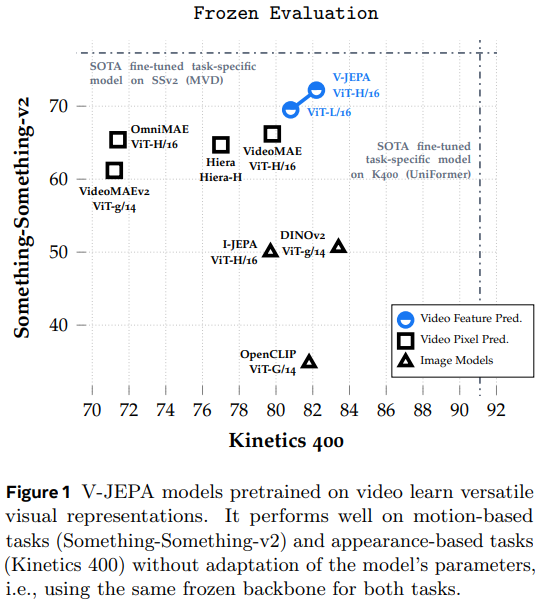
In conclusion, the examine examined the effectiveness of characteristic prediction as an unbiased goal for unsupervised video studying. It launched V-JEPA, a set of imaginative and prescient fashions skilled purely by self-supervised characteristic prediction. V-JEPA performs effectively throughout numerous picture and video duties with out requiring parameter adaptation, surpassing earlier video illustration strategies in frozen evaluations for motion recognition, spatiotemporal motion detection, and picture classification. Pretraining on movies enhances its capacity to seize fine-grained movement particulars, the place large-scale picture fashions wrestle. Moreover, V-JEPA demonstrates sturdy label effectivity, sustaining excessive efficiency even when restricted labeled information is obtainable for downstream duties.
Check out the Paper and Blog. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 75k+ ML SubReddit.
🚨 Advisable Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Deal with Authorized Issues in AI Datasets
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
