Deep Neural Community (DNN) coaching has skilled unprecedented development with the rise of enormous language fashions (LLMs) and generative AI. The effectiveness of those fashions straight correlates with growing their dimension, a growth made potential by advances in GPU expertise and frameworks like PyTorch and TensorFlow. Nevertheless, coaching neural networks with billions of parameters presents important technical challenges as fashions exceed the capability of particular person GPUs. This necessitates distributing the mannequin throughout a number of GPUs and parallelizing matrix multiplication operations. A number of components influence coaching effectivity, together with sustained computational efficiency, collective communication operations over subcommunicators, and the overlap of computation with non-blocking collectives.
Latest efforts to coach LLMs have pushed the boundaries of GPU-based cluster utilization, although effectivity stays a problem. Meta educated Llama 2 utilizing 2,000 NVIDIA A100 GPUs, whereas Megatron-LM’s pipeline parallelism achieved 52% of peak efficiency when benchmarking a 1000B parameter mannequin on 3,072 GPUs. The Megatron-LM and DeepSpeed mixture reached 36% of peak efficiency when coaching a 530B parameter mannequin on 4,480 A100 GPUs. MegaScale achieved 55.2% of peak efficiency for a 175B parameter mannequin on 12,288 A100 GPUs. On AMD methods, FORGE coaching reached 28% of peak efficiency on 2,048 MI250X GPUs, whereas different research achieved 31.96% of peak when benchmarking a 1T parameter mannequin on 1,024 MI250X GPUs.
Researchers from the College of Maryland, School Park, USA; Max Planck Institute for Clever Programs, Tübingen, Germany; and College of California, Berkeley, USA have proposed AxoNN, a novel four-dimensional hybrid parallel algorithm carried out in a extremely scalable, moveable, open-source framework. Researchers launched a number of efficiency optimizations in AxoNN to reinforce matrix multiplication kernel efficiency, successfully overlap non-blocking collectives with computation, and make use of efficiency modeling to establish optimum configurations. Past efficiency, additionally they addressed important privateness and copyright issues arising from coaching knowledge memorization in LLMs by investigating “catastrophic memorization”. A 405-billion parameter LLM is fine-tuned utilizing AxoNN on Frontier.
AxoNN is evaluated on three main supercomputing platforms: Perlmutter at NERSC/LBL with NVIDIA A100 GPUs (40GB DRAM every), Frontier at OLCF/ORNL that includes AMD Intuition MI250X GPUs (128GB DRAM every, divided into two independently managed 64GB Graphic Compute Dies), and Alps at CSCS outfitted with GH200 Superchips (96GB DRAM per H100 GPU). All methods make the most of 4 HPE Slingshot 11 NICs per node, every delivering bidirectional hyperlink speeds of 25 GB/s. Efficiency measurements comply with a rigorous methodology, operating ten iterations and averaging the final eight to account for warmup variability. Benchmarking is finished for outcomes in opposition to theoretical peak efficiency values, reporting the share of peak achieved and complete sustained bf16 flop/s.
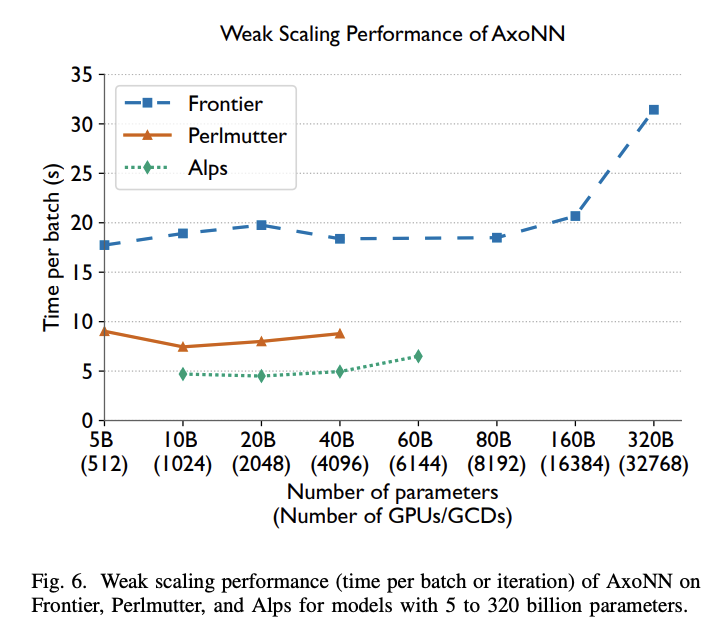
AxoNN reveals distinctive weak scaling efficiency on all three supercomputers with GPT-style transformers. Close to-ideal scaling is achieved as much as 4,096 GPUs/GCDs throughout all platforms, masking the standard {hardware} vary for large-scale LLM coaching. Whereas operating the 60B mannequin on 6,144 H100 GPUs of Alps reveals a slight effectivity discount to 76.5% in comparison with 1,024 GPU efficiency, Frontier’s in depth GPU availability permits unprecedented scaling checks. AxoNN maintains near-perfect weak scaling as much as 8,192 GCDs on Frontier with 88.3% effectivity relative to 512 GCD efficiency. On Perlmutter, AxoNN persistently achieves 50% or larger of the marketed 312 Tflop/s peak per GPU. The linear efficiency scaling is evidenced by an nearly 8 instances enhance in sustained floating-point operations, from 80.8 Pflop/s on 512 GPUs to a formidable 620.1 Pflop/s on 4,096 GPUs.
In conclusion, researchers have launched AxoNN, whose contributions to machine studying lengthen past efficiency metrics by offering scalable, user-friendly, and moveable entry to mannequin parallelism. It permits the coaching and fine-tuning of bigger fashions beneath commodity computing constraints, permitting sequential LLM coaching codebases to make the most of distributed sources effectively. Furthermore, by democratizing the power to fine-tune giant fashions on domain-specific knowledge, AxoNN expands the capabilities of practitioners throughout numerous fields. So, there’s an urgency for understanding and addressing memorization dangers, as extra researchers can now work with fashions of unprecedented scale and complexity which will inadvertently seize delicate data from coaching knowledge.
Check out the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.
🚨 Beneficial Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Handle Authorized Considerations in AI Datasets

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.