Massive Language Fashions (LLMs) are important in fields that require contextual understanding and decision-making. Nevertheless, their improvement and deployment include substantial computational prices, which limits their scalability and accessibility. Researchers have optimized LLMs to enhance effectivity, significantly fine-tuning processes, with out sacrificing reasoning capabilities or accuracy. This has led to exploring parameter-efficient coaching strategies that preserve efficiency whereas lowering useful resource consumption.
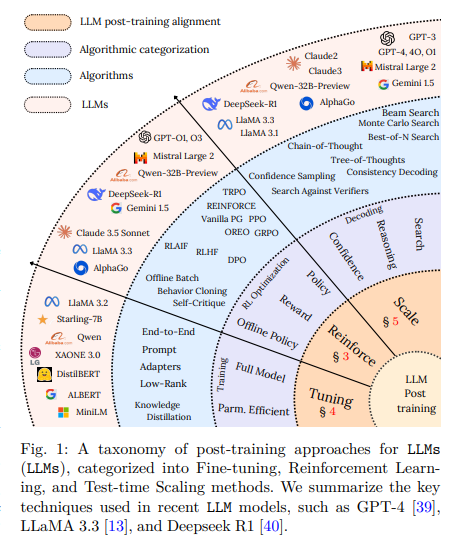
One of many vital challenges confronted within the area is the extreme value of coaching and fine-tuning LLMs. These fashions require large datasets and in depth computational energy, making them impractical for a lot of purposes. Furthermore, conventional fine-tuning strategies result in overfitting and require vital reminiscence utilization, making them much less adaptable to new domains. One other drawback is the shortcoming of LLMs to deal with multi-step logical reasoning successfully. Whereas they carry out nicely on easy duties, they typically wrestle with math issues, complicated decision-making, and sustaining coherence in multi-turn conversations. To make LLMs extra sensible and scalable, it’s essential to develop strategies that cut back the computational footprint whereas enhancing their reasoning capabilities.
Earlier approaches to enhancing LLM effectivity have relied on instruction fine-tuning, reinforcement studying, and mannequin distillation. Instruction fine-tuning allows fashions to know higher and reply to consumer prompts, whereas reinforcement studying helps refine decision-making processes. Nevertheless, these strategies require labeled datasets which can be costly to acquire. Mannequin distillation, which transfers data from bigger fashions to smaller ones, has been one other strategy, nevertheless it typically ends in a lack of reasoning capacity. Researchers have additionally experimented with quantization methods and pruning methods to cut back the variety of lively parameters, however these strategies have had restricted success in sustaining mannequin accuracy.

A analysis workforce from DeepSeek AI launched a novel parameter-efficient fine-tuning (PEFT) framework that optimizes LLMs for higher reasoning and decrease computational prices. The framework integrates Low-Rank Adaptation (LoRA), Quantized LoRA (QLoRA), structured pruning, and novel test-time scaling strategies to enhance inference effectivity. As a substitute of coaching complete fashions, LoRA and QLoRA inject trainable low-rank matrices into particular layers, lowering the variety of lively parameters whereas preserving efficiency. Structured pruning additional eliminates pointless computations by eradicating redundant mannequin weights. Additionally, the researchers included test-time scaling methods, together with Beam Search, Finest-of-N Sampling, and Monte Carlo Tree Search (MCTS), to reinforce multi-step reasoning with out requiring retraining. This strategy ensures that LLMs dynamically allocate computational energy based mostly on process complexity, making them considerably extra environment friendly.
The proposed methodology refines LLM reasoning by integrating Tree-of-Thought (ToT) and Self-Consistency Decoding. The ToT strategy constructions logical steps right into a tree-like format, permitting the mannequin to discover a number of reasoning paths earlier than choosing the right reply. This prevents the mannequin from prematurely committing to a single reasoning path, typically resulting in errors. Self-Consistency Decoding additional enhances accuracy by producing a number of responses and choosing probably the most often occurring appropriate reply. Additional, the framework employs distillation-based studying, permitting smaller fashions to inherit reasoning skills from bigger ones with out in depth computation. By combining these methods, the researchers have achieved excessive effectivity with out compromising efficiency. The methodology ensures that fashions skilled with lower than half the computational assets of conventional strategies carry out at comparable or larger ranges on complicated reasoning duties.

Intensive evaluations demonstrated that test-time scaling allows fashions to carry out comparably to these 14× bigger on easy-to-intermediate duties whereas lowering inference prices by 4× FLOPs. LoRA and QLoRA contribute to memory-efficient coaching by integrating 4-bit quantization with low-rank adaptation, enabling fine-tuning on shopper GPUs. BitsAndBytes supplies 8-bit optimizers to optimize reminiscence utilization whereas sustaining mannequin efficiency. Tree-of-thought reasoning enhances structured multi-step problem-solving, enhancing decision-making accuracy in complicated duties. On the similar time, Monte Carlo Tree Search refines response choice in multi-step reasoning eventualities, significantly in scientific Q&A duties. These findings spotlight the potential of parameter-efficient fine-tuning to enhance LLM effectivity with out sacrificing reasoning capabilities.
This analysis supplies a sensible and scalable answer for enhancing LLMs whereas lowering computational calls for. The framework ensures that fashions obtain excessive efficiency with out extreme assets by combining parameter-efficient fine-tuning, test-time scaling, and memory-efficient optimizations. The findings recommend that future developments ought to steadiness mannequin dimension with reasoning effectivity, enabling broader accessibility of LLM know-how. With firms and establishments in search of cost-effective AI options, this analysis units a basis for environment friendly and scalable LLM deployment.
Check out the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 80k+ ML SubReddit.
🚨 Really helpful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Handle Authorized Considerations in AI Datasets
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.