Latest developments in RL for LLMs, similar to DeepSeek R1, have demonstrated that even easy question-answering duties can considerably improve reasoning capabilities. Conventional RL approaches for LLMs typically depend on single-turn duties, the place a mannequin is rewarded primarily based on the correctness of a single response. Nevertheless, these strategies endure from sparse rewards and fail to coach fashions to refine their responses primarily based on consumer suggestions. To handle these limitations, multi-turn RL approaches have been explored, permitting LLMs to make a number of makes an attempt at fixing an issue, thus enhancing their reasoning and self-correction talents.
A number of prior research have investigated planning and self-correction mechanisms in RL for LLMs. Impressed by the Thinker algorithm, which permits brokers to discover alternate options earlier than taking motion, some approaches improve LLM reasoning by permitting a number of makes an attempt reasonably than studying a world mannequin. Strategies similar to SCoRe prepare LLMs on multi-attempt duties however lack verification of prior responses utilizing ground-truth rewards, necessitating complicated calibration. Different works concentrate on self-correction utilizing exterior instruments, similar to Reflexion for self-reflection and CRITIC for real-time suggestions. In contrast to these approaches, the proposed methodology extends DeepSeek R1’s single-turn question-answering activity right into a multi-attempt framework, leveraging historic errors to refine responses and improve reasoning.
DualityRL and Shanghai AI Lab researchers introduce a multi-attempt RL strategy to boost reasoning in LLMs. In contrast to single-turn duties, this methodology permits fashions to refine responses via a number of makes an attempt with suggestions. Experimental outcomes present a forty five.6% to 52.5% accuracy enchancment with two makes an attempt on math benchmarks, in comparison with a marginal achieve in single-turn fashions. The mannequin learns self-correction utilizing Proximal Coverage Optimization (PPO), resulting in emergent reasoning capabilities. This multi-attempt setting facilitates iterative refinement, selling deeper studying and problem-solving expertise, making it a promising various to standard RLHF and supervised fine-tuning strategies.
In a single-turn activity, an LLM generates a response to a query sampled from a dataset, optimising its coverage to maximise rewards primarily based on reply correctness. In distinction, the multi-turn strategy permits iterative refinement, the place responses affect subsequent prompts. The proposed multi-attempt activity introduces a hard and fast variety of makes an attempt, prompting retries if the preliminary response is inaccurate. The mannequin will get a reward of +1 for proper solutions, -0.5 for incorrect however well-formatted responses, and -1 in any other case. This strategy encourages exploration in early makes an attempt with out penalties, leveraging PPO for optimisation, enhancing reasoning via reinforcement studying.
The research fine-tunes the Qwen 2.5 Math 1.5B mannequin on 8K math questions utilizing PPO with γ = 1, λ = 0.99, and a KL divergence coefficient of 0.01. Coaching spans 160 episodes, producing 1.28M samples. Within the multi-attempt setting, makes an attempt are sampled from {1, …, 5}, whereas the baseline follows a single-turn strategy. Outcomes present the multi-attempt mannequin achieves greater rewards and barely higher analysis accuracy. Notably, it refines responses successfully, enhancing accuracy from 45.58% to 53.82% over a number of makes an attempt. This adaptive reasoning functionality may improve efficiency in code era and problem-solving fields.
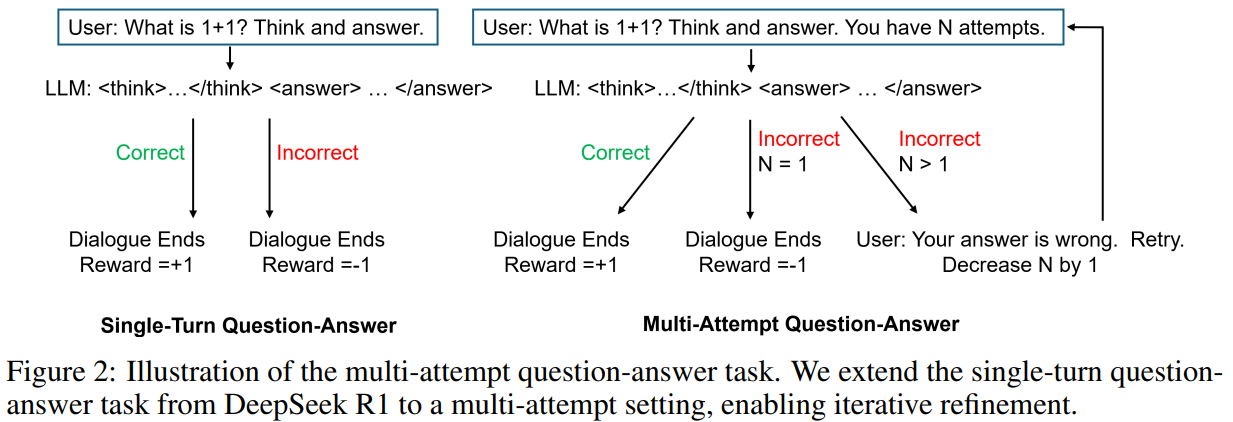
In conclusion, the research builds on DeepSeek R1’s question-answering activity by introducing a multi-attempt mechanism. Whereas efficiency good points on math benchmarks are modest, the strategy considerably improves the mannequin’s capability to refine responses primarily based on suggestions. The mannequin, educated to iterate on incorrect solutions, enhances search effectivity and self-correction. Experimental outcomes present that accuracy improves from 45.6% to 52.5% with two makes an attempt, whereas a single-turn mannequin solely barely will increase. Future work may additional discover incorporating detailed suggestions or auxiliary duties to boost LLM capabilities, making this strategy invaluable for adaptive reasoning and sophisticated problem-solving duties.
Check out the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 80k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.