Giant Language Fashions (LLMs) have proven vital enhancements when explicitly skilled on structured reasoning traces, permitting them to unravel mathematical equations, infer logical conclusions, and navigate multistep planning duties. Nevertheless, the computational assets required to course of these prolonged reasoning traces are substantial. Researchers proceed to discover methods to boost effectivity whereas sustaining the effectiveness of those fashions.
One of many main challenges in LLM reasoning is the excessive computational value related to coaching and inference. When fashions course of step-by-step reasoning traces in pure language, a lot of the textual content is used to take care of coherence quite than contribute to reasoning. This results in inefficient reminiscence utilization and elevated processing time. Present strategies search to mitigate this problem by abstracting reasoning steps into compressed representations with out dropping vital data. Regardless of these efforts, fashions that try to internalize reasoning traces by way of steady latent house or multi-stage coaching usually carry out worse than these skilled with full reasoning particulars.
Present options have aimed to cut back redundancy in reasoning traces by compressing intermediate steps. Some approaches use steady latent representations, whereas others contain iterative reductions of reasoning sequences. Nevertheless, these strategies require complicated coaching procedures and fail to take care of efficiency akin to express textual reasoning. Researchers have sought another method that reduces computational calls for whereas preserving reasoning capabilities. To handle this, they’ve launched a way that replaces components of the reasoning course of with latent discrete tokens, reaching improved effectivity with out sacrificing accuracy.
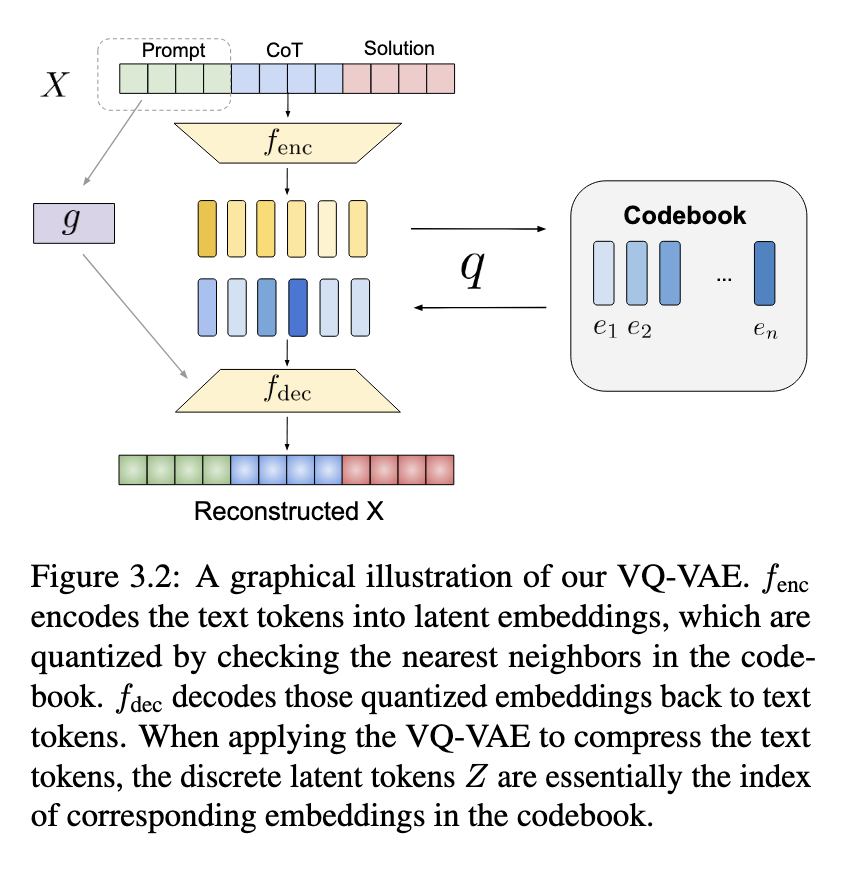
A analysis group from Meta AI and UC Berkeley proposed a novel approach that integrates discrete latent tokens into LLM reasoning. They make use of a vector-quantized variational autoencoder (VQ-VAE) to transform a portion of the stepwise reasoning course of into compact representations. The strategy includes changing early reasoning steps with latent abstractions whereas retaining later steps in textual type. This hybrid illustration ensures the mannequin maintains interpretability whereas decreasing the token size of reasoning sequences. The important thing innovation is the randomized mixing of latent and textual content tokens, which permits the mannequin to adapt seamlessly to new reasoning buildings with out in depth retraining.
The researchers developed a coaching technique incorporating latent tokens into LLM reasoning traces. Throughout coaching, a managed variety of reasoning steps are changed with their corresponding latent representations, making certain that the mannequin learns to interpret each abstracted and express reasoning buildings. The randomization of latent token replacements permits adaptability throughout totally different drawback sorts, bettering the mannequin’s generalization potential. Limiting the variety of textual reasoning steps reduces enter dimension, making LLMs extra computationally environment friendly whereas sustaining reasoning efficiency. Additional, the researchers ensured that the prolonged vocabulary, together with newly launched latent tokens, could possibly be seamlessly built-in into the mannequin with out requiring main modifications.
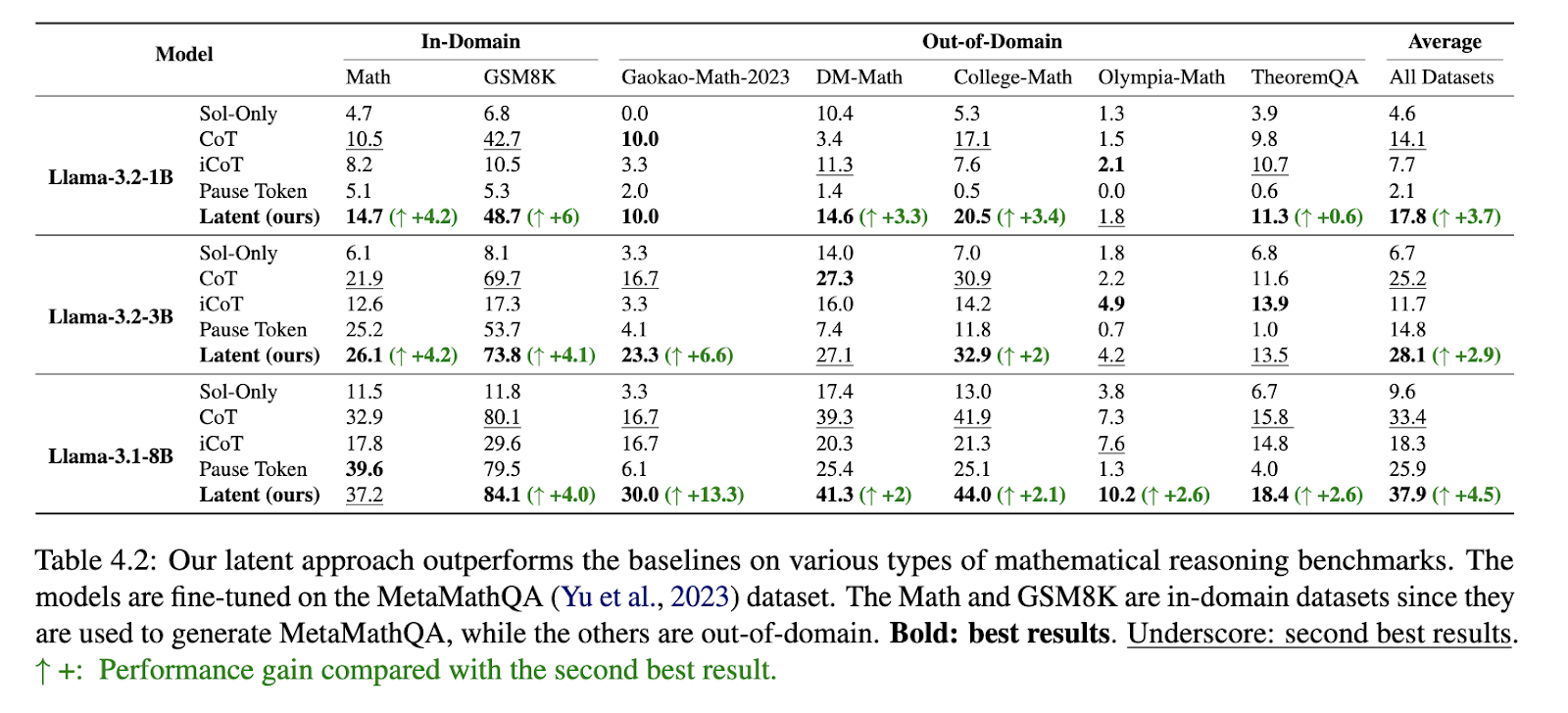
The proposed technique demonstrated vital efficiency enhancements throughout varied benchmarks. The method outperformed conventional chain-of-thought (CoT) fashions when utilized to mathematical reasoning duties. On the Math dataset, it achieved a 4.2% enchancment over earlier best-performing strategies. Within the GSM8K benchmark, the method yielded a 4.1% acquire, whereas within the Contemporary-Gaokao-Math-2023 dataset, it outperformed current fashions by 13.3%. The discount in reasoning hint size was equally noteworthy, with a mean lower of 17%, which resulted in quicker inference instances and decrease reminiscence consumption. Evaluations on logical reasoning datasets similar to ProntoQA and ProsQA additional validated the method’s effectiveness, with accuracy enhancements of 1.2% and 18.7%, respectively. The mannequin achieved 100% accuracy on easier reasoning duties, demonstrating its capability for environment friendly logical deduction.
The introduction of latent tokens has offered a big step ahead in optimizing LLM reasoning with out compromising accuracy. By decreasing the dependence on full-text reasoning sequences and leveraging discrete latent representations, the researchers have developed an method that maintains effectivity whereas bettering mannequin generalization. The hybrid construction ensures that important reasoning elements are preserved, providing a sensible resolution to the problem of balancing interpretability and computational effectivity. As LLMs proceed to evolve, such strategies might pave the best way for extra resource-efficient synthetic intelligence methods that retain excessive ranges of reasoning functionality.
Check out the Technical details. All credit score for this analysis goes to the researchers of this venture. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.