LLMs have demonstrated robust reasoning and data capabilities, but they usually require exterior data augmentation when their inner representations lack particular particulars. One technique for incorporating new info is supervised fine-tuning, the place fashions are educated on extra datasets to replace their weights. Nevertheless, this strategy is inefficient because it requires retraining each time new data is launched and should result in catastrophic forgetting, degrading the mannequin’s efficiency on normal duties. To beat these limitations, various methods that protect the mannequin’s weights have gained recognition. RAG is one strategy that retrieves related data from unstructured textual content and appends it to the enter question earlier than passing it by means of the mannequin. By dynamically retrieving info, RAG permits LLMs to entry giant data bases whereas sustaining a smaller context measurement. Nevertheless, as long-context fashions comparable to GPT-4 and Gemini have emerged, researchers have explored in-context studying, the place exterior data is instantly supplied within the mannequin’s enter. This eliminates the necessity for retrieval however comes with computational challenges, as processing lengthy contexts requires considerably extra reminiscence and time.
A number of superior methods have been developed to boost LLMs’ capability to combine exterior data extra effectively. Structured consideration mechanisms enhance reminiscence effectivity by segmenting the context into unbiased sections, decreasing the computational load of self-attention. Key-value (KV) caching optimizes response era by storing precomputed embeddings at completely different layers, permitting the mannequin to recall related info with out recalculating it. This reduces the complexity from quadratic to linear regarding context size. Not like conventional KV caching, which requires full recomputation when the enter modifications, newer strategies permit selective updates, making exterior data integration extra versatile.
Researchers from Johns Hopkins College and Microsoft suggest a Data Base Augmented Language Mannequin (KBLAM), a technique for integrating exterior data into LLMs. KBLAM converts structured data base (KB) triples into key-value vector pairs, seamlessly embedding them throughout the LLM’s consideration layers. Not like RAG, it eliminates exterior retrievers, and in contrast to in-context studying, it scales linearly with KB measurement. KBLAM permits environment friendly dynamic updates with out retraining and enhances interpretability. Skilled utilizing instruction tuning on artificial information, it improves reliability by refusing to reply when related data is absent, decreasing hallucinations and enhancing scalability.
KBLAM enhances LLMs by integrating a KB by means of two steps. First, every KB triple is transformed into steady key-value embeddings, termed data tokens, utilizing a pre-trained sentence encoder and linear adapters. These tokens are then included into every consideration layer by way of an oblong consideration construction, permitting environment friendly retrieval with out altering the LLM’s core parameters. This technique ensures scalability, mitigates positional bias and maintains reasoning talents. Moreover, instruction tuning optimizes data token projection with out modifying the LLM, utilizing an artificial KB to stop memorization. This strategy effectively integrates giant KBs whereas preserving the mannequin’s authentic capabilities.
The empirical analysis of KBLAM demonstrates its effectiveness as a data retrieval and reasoning mannequin. After instruction tuning, its consideration matrix displays interpretable patterns, permitting correct retrieval. KBLAM achieves efficiency corresponding to in-context studying whereas considerably decreasing reminiscence utilization and sustaining scalability as much as 10K triples. It could additionally refuse to reply when no related data is discovered, with “over-refusal” occurring later than in-context studying. The mannequin is educated on an instruction-tuned Llama3-8B and optimized utilizing AdamW. Analysis of artificial and Enron datasets confirms KBLAM’s robust retrieval accuracy, environment friendly data integration, and talent to reduce hallucinations.
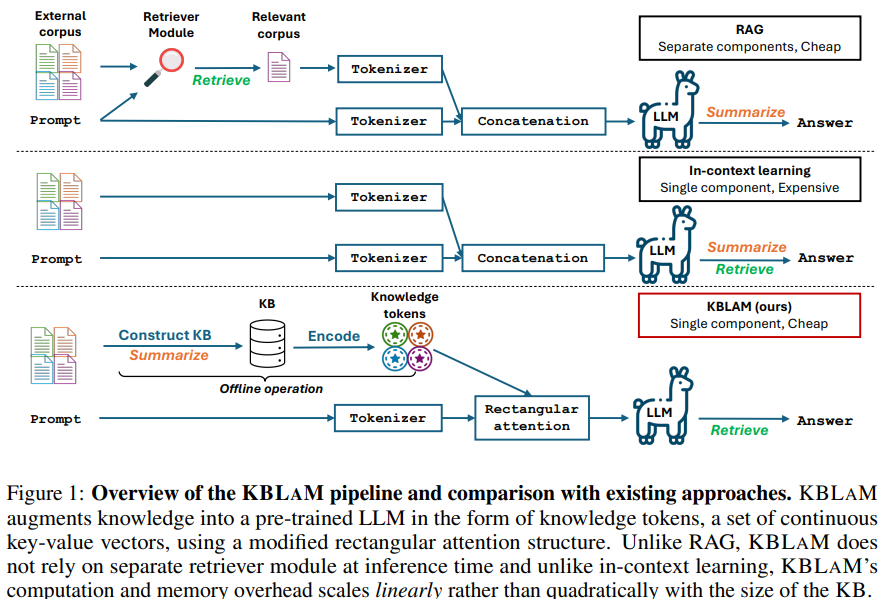
In conclusion, KBLAM is an strategy for enhancing LLMs with exterior KBs. It encodes KB entries as steady key-value vector pairs utilizing pre-trained sentence encoders with linear adapters and integrates them into LLMs by means of a specialised consideration mechanism. Not like Retrieval-Augmented Technology, KBLAM removes exterior retrieval modules, and in contrast to in-context studying, it scales linearly with KB measurement. This allows environment friendly integration of over 10K triples into an 8B LLM inside an 8K context window on a single A100 GPU. Experiments present its effectiveness in question-answering and reasoning duties whereas sustaining interpretability and enabling dynamic data updates.
Check out the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 85k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.