Giant Language Fashions (LLMs) have demonstrated distinctive capabilities throughout various purposes, however their widespread adoption faces important challenges. The first concern stems from coaching datasets that include various, unfocused, and probably dangerous content material, together with malicious code and cyberattack-related data. This creates a essential have to align LLM outputs with particular person necessities whereas stopping misuse. Present approaches like Reinforcement Studying from Human Suggestions (RLHF) try to handle these points by incorporating human preferences into mannequin conduct. Nonetheless, RLHF faces substantial limitations on account of its excessive computational necessities, dependence on advanced reward fashions, and the inherent instability of reinforcement studying algorithms. This example necessitates extra environment friendly and dependable strategies to fine-tune LLMs whereas sustaining their efficiency and making certain accountable AI improvement.
Varied alignment strategies have emerged to handle the challenges of fine-tuning LLMs with human preferences. RLHF initially gained prominence through the use of a reward mannequin skilled on human desire knowledge, mixed with reinforcement studying algorithms like PPO to optimize mannequin conduct. Nonetheless, its advanced implementation and resource-intensive nature led to the event of Direct Coverage Optimization (DPO), which simplifies the method by eliminating the necessity for a reward mannequin and utilizing binary cross-entropy loss as an alternative. Current analysis has explored totally different divergence measures to regulate output variety, significantly specializing in α-divergence as a method to stability between reverse KL and ahead KL divergence. Additionally, researchers have investigated numerous approaches to boost response variety, together with temperature-based sampling strategies, immediate manipulation, and goal operate modifications. The significance of variety has turn into more and more related, particularly in duties the place protection – the power to resolve issues by means of a number of generated samples – is essential, reminiscent of in mathematical and coding purposes.
Researchers from The College of Tokyo and Most popular Networks, Inc. introduce H-DPO, a strong modification to the normal DPO method that addresses the constraints of mode-seeking conduct. The important thing innovation lies in controlling the entropy of the ensuing coverage distribution, which allows simpler seize of goal distribution modes. Conventional reverse KL divergence minimization can generally fail to realize correct mode-seeking becoming by preserving variance when becoming an unimodal distribution to a multimodal goal. H-DPO addresses this by introducing a hyperparameter α that modifies the regularization time period, permitting for deliberate entropy discount when α < 1. This method aligns with sensible observations that LLMs usually carry out higher with decrease temperature values throughout analysis. In contrast to post-training temperature changes, H-DPO incorporates this distribution sharpening instantly into the coaching goal, making certain optimum alignment with the specified conduct whereas sustaining implementation simplicity.
The H-DPO methodology introduces a strong method to entropy management in language mannequin alignment by modifying the reverse KL divergence regularization time period. The tactic decomposes reverse KL divergence into entropy and cross-entropy parts, introducing a coefficient α that permits exact management over the distribution’s entropy. The target operate for H-DPO is formulated as JH-DPO, which mixes the anticipated reward with the modified divergence time period. When α equals 1, the operate maintains customary DPO conduct, however setting α under 1 encourages entropy discount. By constrained optimization utilizing Lagrange multipliers, the optimum coverage is derived as a operate of the reference coverage and reward, with α controlling the sharpness of the distribution. The implementation requires minimal modification to the prevailing DPO framework, basically involving the alternative of the coefficient β with αβ within the loss operate, making it extremely sensible for real-world purposes.
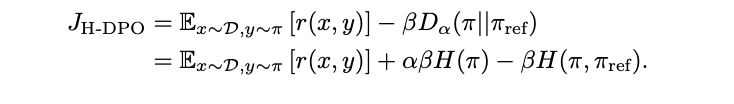
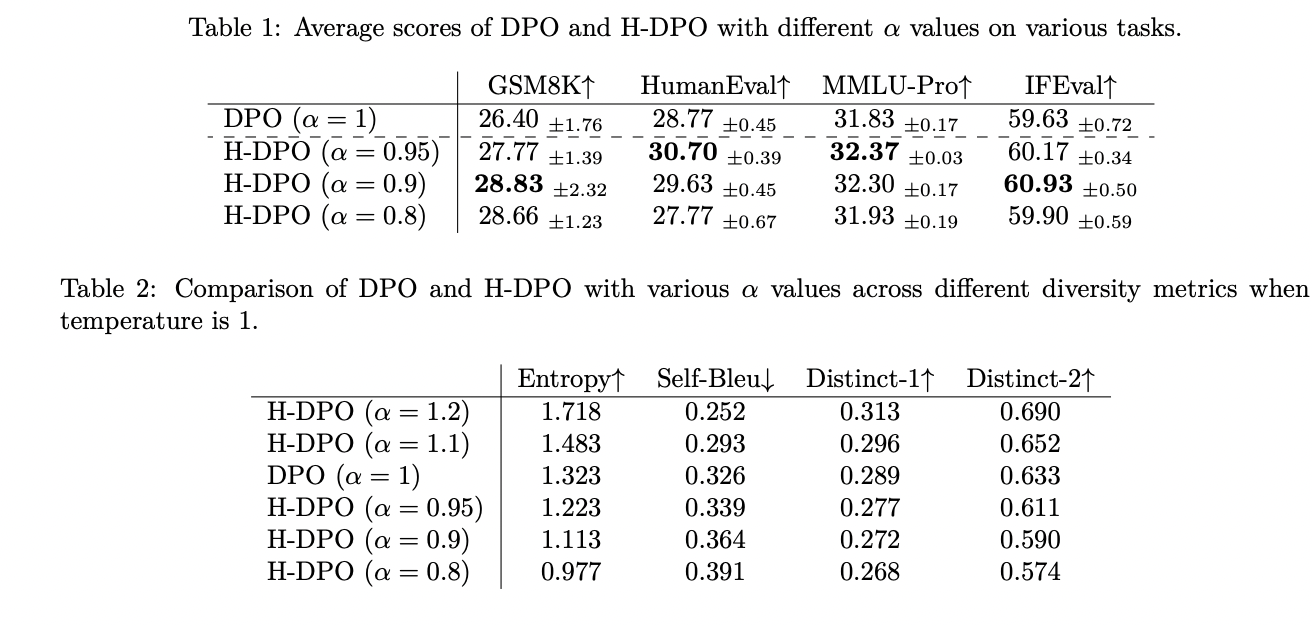
The experimental analysis of H-DPO demonstrated important enhancements throughout a number of benchmarks in comparison with customary DPO. The tactic was examined on various duties together with grade college math issues (GSM8K), coding duties (HumanEval), multiple-choice questions (MMLU-Professional), and instruction-following duties (IFEval). By decreasing α to values between 0.95 and 0.9, H-DPO achieved efficiency enhancements throughout all duties. The range metrics confirmed fascinating trade-offs: decrease α values resulted in decreased variety at temperature 1, whereas larger α values elevated variety. Nonetheless, the connection between α and variety proved extra advanced when contemplating temperature variations. On the GSM8K benchmark, H-DPO with α=0.8 achieved optimum protection on the coaching temperature of 1, outperforming customary DPO’s greatest outcomes at temperature 0.5. Importantly, on HumanEval, bigger α values (α=1.1) confirmed superior efficiency for in depth sampling situations (okay>100), indicating that response variety performed an important function in coding job efficiency.
H-DPO represents a major development in language mannequin alignment, providing a easy but efficient modification to the usual DPO framework. By its progressive entropy management mechanism through the hyperparameter α, the strategy achieves superior mode-seeking conduct and allows extra exact management over output distribution. The experimental outcomes throughout numerous duties demonstrated improved accuracy and variety in mannequin outputs, significantly excelling in mathematical reasoning and protection metrics. Whereas the guide tuning of α stays a limitation, H-DPO’s easy implementation and spectacular efficiency make it a precious contribution to the sphere of language mannequin alignment, paving the best way for simpler and controllable AI methods.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.