Current advances in generative fashions, particularly diffusion fashions and rectified flows, have revolutionized visible content material creation with enhanced output high quality and flexibility. Human suggestions integration throughout coaching is crucial for aligning outputs with human preferences and aesthetic requirements. Present approaches like ReFL strategies depend upon differentiable reward fashions that introduce VRAM inefficiency for video technology. DPO variants obtain solely marginal visible enhancements. Additional, RL-based strategies face challenges together with conflicts between ODE-based sampling of rectified movement fashions and Markov Choice Course of formulations, instability when scaling past small datasets, and a scarcity of validation for video technology duties.
Aligning LLMs employs Reinforcement Studying from Human Suggestions (RLHF), which trains reward features primarily based on comparability information to seize human preferences. Coverage gradient strategies have confirmed efficient however are computationally intensive and require intensive tuning, whereas Direct Coverage Optimization (DPO) affords value effectivity however delivers inferior efficiency. DeepSeek-R1 just lately confirmed that large-scale RL with specialised reward features can information LLMs towards self-emergent thought processes. Present approaches embody DPO-style strategies, direct backpropagation with reward indicators like ReFL, and coverage gradient-based strategies resembling DPOK and DDPO. Manufacturing fashions primarily make the most of DPO and ReFL as a result of instability of coverage gradient strategies in large-scale functions.
Researchers from ByteDance Seed and the College of Hong Kong have proposed DanceGRPO, a unified framework adapting Group Relative Coverage Optimization to visible technology paradigms. This resolution operates seamlessly throughout diffusion fashions and rectified flows, dealing with text-to-image, text-to-video, and image-to-video duties. The framework integrates with 4 basis fashions (Secure Diffusion, HunyuanVideo, FLUX, SkyReels-I2V) and 5 reward fashions protecting picture/video aesthetics, text-image alignment, video movement high quality, and binary reward assessments. DanceGRPO outperforms baselines by as much as 181% on key benchmarks, together with HPS-v2.1, CLIP Rating, VideoAlign, and GenEval.
The structure makes use of 5 specialised reward fashions to optimize visible technology high quality:
- Picture Aesthetics quantifies visible attraction utilizing fashions fine-tuned on human-rated information.
- Textual content-image Alignment makes use of CLIP to maximise cross-modal consistency.
- Video Aesthetics High quality extends analysis to temporal domains utilizing Imaginative and prescient Language Fashions (VLMs).
- Video Movement High quality evaluates movement realism by physics-aware VLM evaluation.
- Thresholding Binary Reward employs a discretization mechanism the place values exceeding a threshold obtain 1, others 0, particularly designed to judge generative fashions’ means to study abrupt reward distributions below threshold-based optimization.
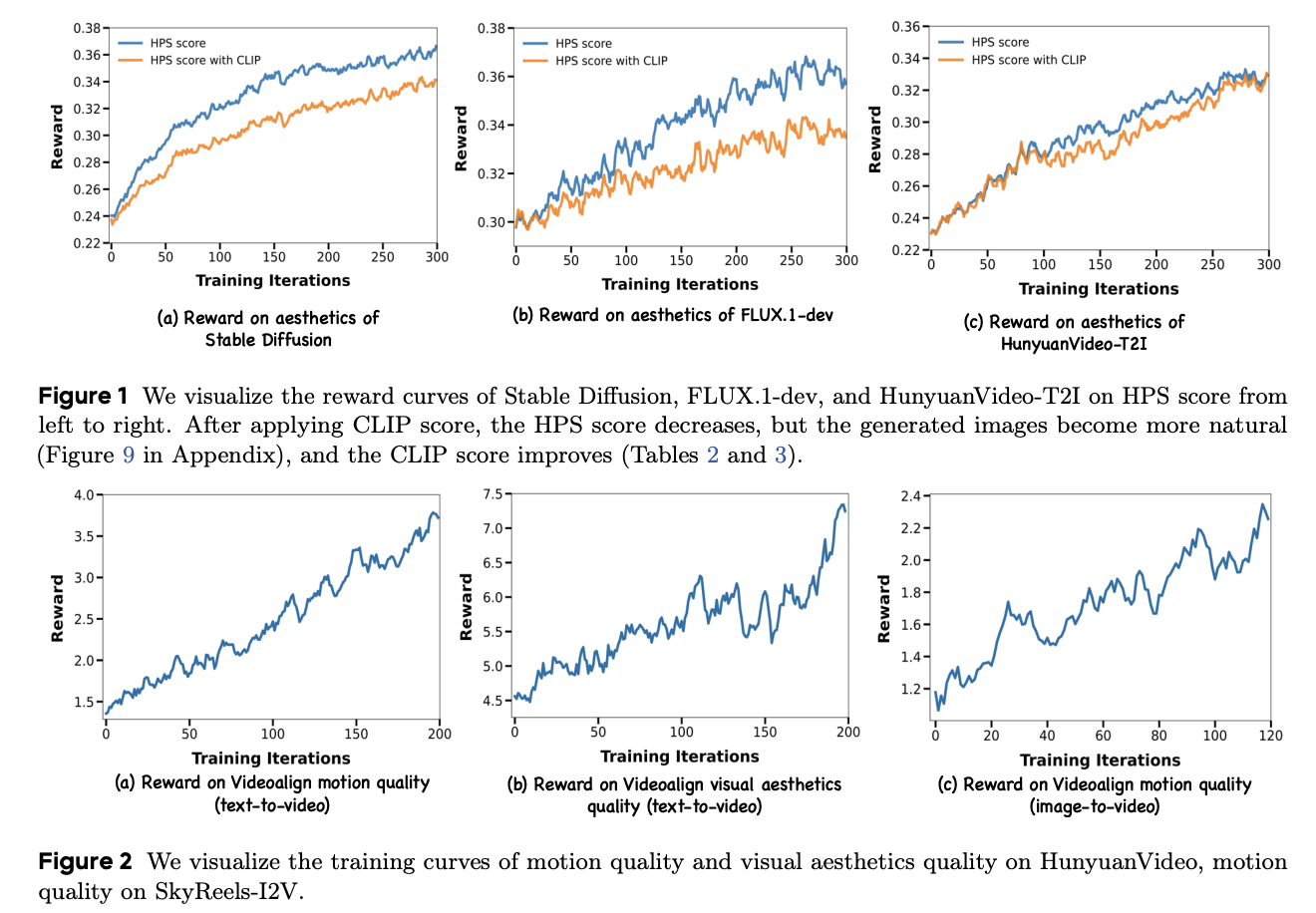
DanceGRPO exhibits vital enhancements in reward metrics for Secure Diffusion v1.4 with a rise within the HPS rating from 0.239 to 0.365, and CLIP Rating from 0.363 to 0.395. Choose-a-Pic and GenEval evaluations affirm the tactic’s effectiveness, with DanceGRPO outperforming all competing approaches. For HunyuanVideo-T2I, optimization utilizing the HPS-v2.1 mannequin will increase the imply reward rating from 0.23 to 0.33, displaying enhanced alignment with human aesthetic preferences. With HunyuanVideo, regardless of excluding text-video alignment attributable to instability, the methodology achieves relative enhancements of 56% and 181% in visible and movement high quality metrics, respectively. DanceGRPO makes use of the VideoAlign reward mannequin’s movement high quality metric, attaining a considerable 91% relative enchancment on this dimension.
On this paper, researchers have launched DanceGRPO, a unified framework for enhancing diffusion fashions and rectified flows throughout text-to-image, text-to-video, and image-to-video duties. It addresses crucial limitations of prior strategies by bridging the hole between language and visible modalities, attaining superior efficiency by environment friendly alignment with human preferences and sturdy scaling to complicated, multi-task settings. Experiments show substantial enhancements in visible constancy, movement high quality, and text-image alignment. Future work will discover GRPO’s extension to multimodal technology, additional unifying optimization paradigms throughout Generative AI.
Take a look at the Paper and Project Page. All credit score for this analysis goes to the researchers of this mission. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 90k+ ML SubReddit.

Sajjad Ansari is a remaining yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.
