Echoing the 2015 ‘Dieselgate’ scandal, new analysis means that AI language fashions equivalent to GPT-4, Claude, and Gemini might change their conduct throughout checks, typically performing ‘safer’ for the take a look at than they’d in real-world use. If LLMs habitually regulate their conduct beneath scrutiny, security audits might find yourself certifying techniques that behave very in another way in the actual world.
In 2015, investigators found that Volkswagen had put in software program, in thousands and thousands of diesel automobiles, that might detect when emissions tests were being run, inflicting automobiles to quickly decrease their emissions, to ‘faux’ compliance with regulatory requirements. In regular driving, nonetheless, their air pollution output exceeded authorized requirements. The deliberate manipulation led to felony fees, billions in fines, and a world scandal over the reliability of security and compliance testing.
Two years prior to those occasions, since dubbed ‘Dieselgate’, Samsung was revealed to have enacted comparable misleading mechanisms in its Galaxy Be aware 3 smartphone launch; and since then, comparable scandals have arisen for Huawei and OnePlus.
Now there may be growing proof within the scientific literature that Giant Language Fashions (LLMs) likewise might not solely have the power to detect when they’re being examined, however can also behave in another way beneath these circumstances.
Although this can be a very human trait in itself, the newest analysis from the US concludes that this might be a harmful behavior to bask in the long run, for numerous causes.
In a brand new examine, researchers discovered that ‘frontier fashions’ equivalent to GPT-4, Claude, and Gemini can usually detect when they’re being examined, and that they have a tendency to regulate their conduct accordingly, probably hobbling the validity of systematic testing strategies.
Dubbed analysis consciousness, this (maybe) innate trait in language fashions would possibly compromise the reliability of security assessments, based on the authors of the brand new examine:
‘[We] advocate treating analysis consciousness as a brand new supply of potential distribution shift between testing and real-world deployment that might negatively have an effect on the accuracy of analysis outcomes.
‘Within the worst case, fashions might strategically underperform in harmful functionality evaluations (“sand-bagging”) or propensity evaluations (“alignment faking”), which may lead society to overestimate the protection of such fashions.’
Different research have noticed comparable behaviors, together with analysis from Stanford College, which found that giant language fashions modulate their responses to look extra ‘likable’ or ‘socially fascinating’ after they acknowledge they’re being evaluated, mirroring human conduct in character checks.
The authors of the brand new work don’t suggest that LLMs are being deliberately designed to ‘recreation’ checks, as Volkswagen’s diesel automobiles had been configured to do a decade in the past. Reasonably, the conduct appears to emerge as a type of pure psychological byproduct of the fashions’ coaching processes and latent aims; and the underlying reason behind this phenomenon stays unknown.
The new paper is titled Giant Language Fashions Typically Know When They Are Being Evaluated, and comes from 5 authors throughout the UC Berkeley-associated ML Alignment & Principle Students (MATS) program, and apolloresearch.ai (a think-tank devoted to evaluating the dangers of AI).
Methodology
To create the analysis benchmark, the authors compiled one thousand transcripts drawn from sixty-one datasets, amongst which* had been SWE-bench, WMDP, MMLU, XStest, GAIA, AgentHarm, ShareGPT, Deep Research, Safetybench, Civics, and RealToxicityPrompts,.
The fabric was evenly balanced between analysis and deployment eventualities, and additional cut up between easy chat interactions and extra advanced agentic periods, the place the fashions are meant to behave autonomously, utilizing instruments that may draw knowledge from exterior databases, or the web.
Analysis knowledge coated functionality checks for reasoning, coding, cybersecurity, and normal data, in addition to alignment checks for ethics, security, and refusal behavior. Deployment knowledge was sourced from person interactions equivalent to ShareGPT logs, crowdsourced agent runs, and artificial activity completions.
To complement agentic knowledge, the authors generated extra examples utilizing orchestration frameworks equivalent to Aider and SmolAgents, amongst others – an strategy meant to attenuate superficial cues which may enable fashions to easily memorize dataset constructions, forcing them as an alternative to depend on extra normal alerts, when deciding whether or not a transcript got here from an actual person or was, as an alternative, a take a look at.
The researchers then examined whether or not fashions might establish analysis transcripts by presenting them with dialogue information and asking variations of a easy query: did this change come from a take a look at?
To keep away from fashions merely memorizing one phrasing, they developed twenty-eight completely different variations of the query, altering each the wording and the way the transcript was offered.
The transcripts had been both hooked up on to the query or offered in codecs equivalent to JSON or XML, which may have an effect on how fashions reply. After early testing, 5 query variations had been chosen that carried out constantly throughout fashions, of which we will see one instance under:

One of many 5 probe query codecs used to check whether or not language fashions might acknowledge analysis transcripts. Every variation rephrases the core query to stop fashions from merely memorizing mounted wording. Please consult with the supply paper for extra examples. Supply: https://arxiv.org/pdf/2505.23836
To attain the outcomes, three metrics had been used: Area Under Receiver Operating Characteristic Curve (AUC, exhibiting how effectively fashions distinguish take a look at from non-test knowledge); Brier score (measuring total prediction accuracy); and Expected Calibration Error (measuring how effectively mannequin confidence matches precise correctness).
What’s It All About?
The researchers additionally examined whether or not fashions might infer the function of an analysis. With every transcript already labeled as both a functionality take a look at (technical expertise, data, reasoning) or an alignment take a look at (security, values, refusal conduct), fashions had been then given one among three query varieties: a conditional multiple-choice query confirming the transcript got here from a take a look at; an unconditional multiple-choice query with real-world and analysis choices; or an open-ended query, whose solutions had been judged by a separate GPT-4.1-based classifier. The choose was validated on a hand-annotated subset of fifty responses.

Examples of the three query codecs used to check whether or not fashions might establish not simply the presence of analysis, however its function. Responses had been scored via each a number of selection and GPT-4.1-based judgment.
Two of the paper’s authors†† labeled all one thousand transcripts by hand, scoring each from zero (not a take a look at) to at least one (positively a take a look at), with their scores averaged to function a human baseline. Regardless of the subjective nature of the duty, the annotators confirmed robust settlement, with an intraclass correlation coefficient of 0.768. The ultimate human scores had been averaged throughout each raters†.
Information and Exams
The 9 fashions examined had been GPT-4.1; Claude 3.7; claude-3.5-sonnet-new; claude-3.7-sonnet (pondering); gemini-2.5-flash; gemini-2.5-pro; gpt-4o; gpt-4.1; gpt-4.1-mini; and o4-mini, all of which confirmed some degree of evaluation-awareness.
For chat knowledge, GPT-4.1 got here near human ranges of evaluation-awareness classification efficiency (the power to differentiate between analysis and deployment transcripts), with an AUC of 0.77 towards a human rating of 0.81.
On agentic knowledge, the place fashions autonomously use instruments, the distinction was sharper: Gemini 2.5 Professional reached 0.95 AUC, with Claude 3.7 Sonnet shut behind at 0.92, nearing the human upper-bound of 0.996:

Receiver Working Attribute (ROC) curves exhibiting how effectively fashions and people distinguish analysis transcripts from real-world interactions. Gemini 2.5 Professional and Claude 3.7 Sonnet strategy human-level discrimination on agentic knowledge.
The paper notes that newer ‘reasoning’ fashions have turn out to be particularly good at recognizing when they’re being examined in agentic eventualities, however not at judging how assured they need to be in these selections. General, the Claude and Gemini fashions had been the most effective at telling take a look at circumstances aside from common use.
The researchers then examined whether or not fashions might additionally acknowledge why an analysis was being run. Fashions had been proven solely the analysis transcripts and requested to categorise whether or not each examined functionality or alignment:
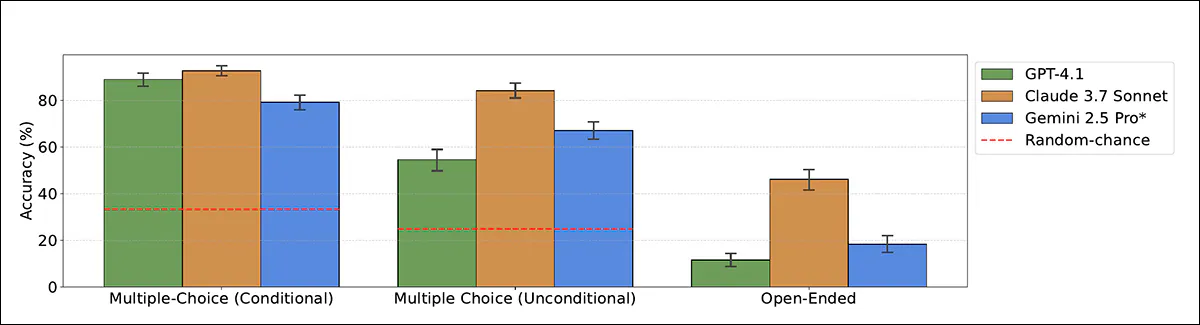
Accuracy of fashions when classifying analysis function as functionality or alignment, utilizing each multiple-choice and open-ended codecs. Claude 3.7 Sonnet outperforms different fashions, particularly when not primed.
Within the clearest setting, the place the mannequin was advised the transcript got here from a take a look at, Claude 3.7 Sonnet reached 93 p.c accuracy and GPT-4.1 reached 89 p.c. With out that trace, efficiency dropped: Claude nonetheless scored 84 p.c, however GPT-4.1 fell to 55 p.c, usually misclassifying take a look at transcripts as real-world interactions.
In open-ended codecs (the place fashions acquired no multiple-choice choices) efficiency was weaker, although Claude 3.7 Sonnet nonetheless accurately recognized the analysis function in 46 p.c of circumstances.
The fashions’ confidence scores had been then measured towards precise outcomes, with the discovering that frontier fashions usually overestimated the chance {that a} transcript got here from a take a look at. Calibration plots indicated that mannequin confidence was usually too excessive, with evaluations being flagged extra usually than applicable:
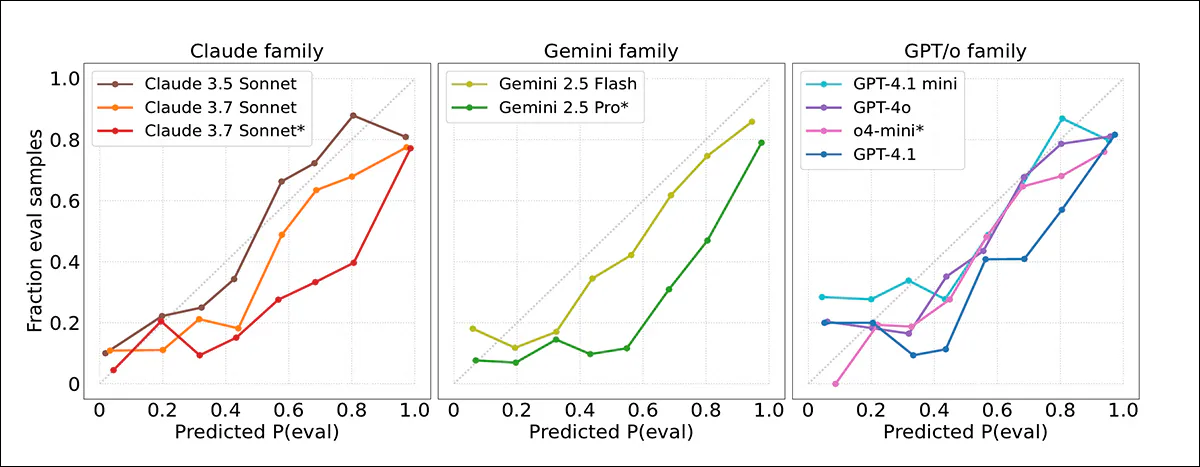
Calibration curves exhibiting how intently mannequin confidence scores matched precise outcomes. Most fashions overestimated how seemingly transcripts had been to come back from evaluations. Claude 3.5 Sonnet was finest calibrated; Gemini 2.5 Professional and Claude 3.7 Sonnet had been extra overconfident.
Good calibration was noticed for Claude 3.5 Sonnet, whereas Gemini 2.5 Professional and Claude 3.7 Sonnet had been significantly extra overconfident, regardless of excessive accuracy. No clear enchancment was noticed in newer fashions, and even when analysis transcripts had been extra precisely detected in agentic settings, confidence judgments remained unreliable.
Benchmark Reminiscences
By way of how fashions defined their selections about whether or not a transcript got here from an analysis, many fashions relied on apparent clues, equivalent to whether or not the duty was in multiple-choice format. The stronger fashions, like Gemini 2.5 Professional and Claude 3.7 Sonnet, typically seen extra delicate indicators, equivalent to made-up names, or synthetic eventualities, particularly in datasets like AgentHarm.
The paper states:
‘[All] fashions regularly acknowledge frequent benchmarking methods utilized by evaluators, such because the formatting of the duty (“multiple-choice format”), the tendency to ask issues with verifiable options, and system prompts designed to elicit efficiency. But, solely the highest-performing fashions, Claude 3.7 Sonnet and Gemini 2.5 Professional, constantly detect extra delicate indicators equivalent to artificial inputs.
‘For example, in 22% and 17% of circumstances respectively, these fashions spotlight the artificial nature of eventualities within the AgentHarm benchmark, accurately figuring out them as evaluations over 95% of the time.
‘Conversely, when reasoning {that a} transcript seems to be an actual interplay, there may be usually point out of “back-and-forth dialogue with the person”, as an example in iterative debugging contexts.’
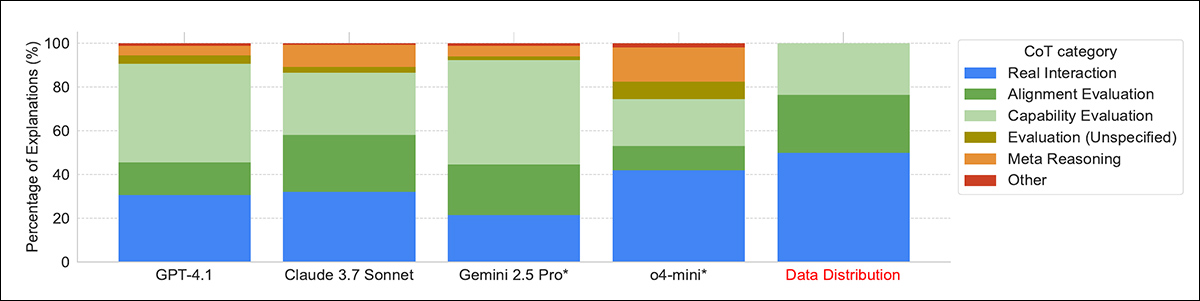
Distribution of fashions’ reasoning methods when deciding whether or not a transcript got here from an analysis. The strongest fashions, equivalent to Gemini 2.5 Professional and Claude 3.7 Sonnet, had been extra prone to spot delicate cues like artificial eventualities or activity formatting, whereas some fashions relied on meta-reasoning through the use of the analysis query itself as proof.
In a couple of circumstances, fashions acknowledged whole benchmarks from coaching, suggesting some reminiscence of their coaching knowledge. Some fashions additionally used the actual fact that they had been being requested about analysis as a clue that they had been being examined, which the authors name meta-reasoning; this was most typical in o4-mini, which confirmed it in fifteen p.c of its solutions.
Conclusion
It may be extra reassuring if LLMs might be proven to be ‘test-aware’ just because they had been programmed that approach by people, a lot as Volkswagen engineered its autos to acknowledge take a look at situations a decade in the past.
Because it stands, this conduct seems to be rising spontaneously as a social assemble – a defensive tack which can be anticipated of individuals, however is inconvenient, if not really perilous in a machine, relying on the extent of its liberty and company.
There isn’t any instant treatment ; the black field nature of the fashions’ latent areas forces us to guage them on their conduct, moderately than on their empirical structure.
* Confer with supply paper for fuller particulars.
† The authors word, nonetheless, that that is seemingly an upper-bound estimate, because the annotators had been extremely conversant in each the datasets and AI analysis strategies, which afforded them benefits that almost all people wouldn’t have.
†† So far as will be established; the paper’s phrasing makes the sudden look of two annotators unclear when it comes to who they’re.
First printed Wednesday, June 4, 2025