In keeping with latest analysis by a number of students, language fashions have demonstrated exceptional developments in complicated reasoning duties, together with arithmetic and programming. Regardless of these important enhancements, these fashions proceed to come across challenges when addressing notably tough issues. The rising discipline of scalable oversight seeks to develop efficient supervision strategies for synthetic intelligence techniques that strategy or surpass human-level efficiency. Researchers anticipate that language fashions can doubtlessly establish errors inside their very own reasoning processes robotically. Nevertheless, current analysis benchmarks face crucial limitations, with some drawback units turning into much less difficult for superior fashions and others offering solely binary correctness assessments with out detailed error annotations. This hole highlights the necessity for extra nuanced and complete analysis frameworks that may totally study the reasoning mechanisms of subtle language fashions.
A number of benchmark datasets have emerged to evaluate language fashions’ reasoning processes, every contributing distinctive insights into error identification and resolution critique. CriticBench focuses on evaluating language fashions’ capabilities to critique options and rectify errors throughout varied reasoning domains. MathCheck makes use of the GSM8K dataset to synthesize options with intentional errors, and difficult fashions to establish incorrect reasoning steps and ultimate solutions. The PRM800K benchmark, constructed upon MATH issues, supplies complete annotations for reasoning step correctness and soundness, producing important analysis curiosity in course of reward fashions. These benchmarks characterize crucial advances in understanding and enhancing the error-detection capabilities of language fashions, providing more and more subtle strategies to judge their reasoning mechanisms.
Qwen Workforce and Alibaba Inc. researchers introduce PROCESSBENCH, a sturdy benchmark designed to measure language fashions’ capabilities in figuring out misguided steps inside mathematical reasoning. This benchmark distinguishes itself by means of three key design rules: drawback issue, resolution variety, and complete analysis. PROCESSBENCH particularly targets competitors and Olympiad-level mathematical issues, using a number of open-source language fashions to generate options that show different fixing approaches. The benchmark includes 3,400 take a look at instances, every meticulously annotated by a number of human consultants to make sure excessive information high quality and analysis reliability. In contrast to earlier benchmarks, PROCESSBENCH adopts a simple analysis protocol that requires fashions to pinpoint the earliest misguided step in an answer, making it adaptable for various mannequin varieties, together with course of reward fashions and critic fashions. This strategy supplies a sturdy framework for assessing reasoning error detection capabilities.

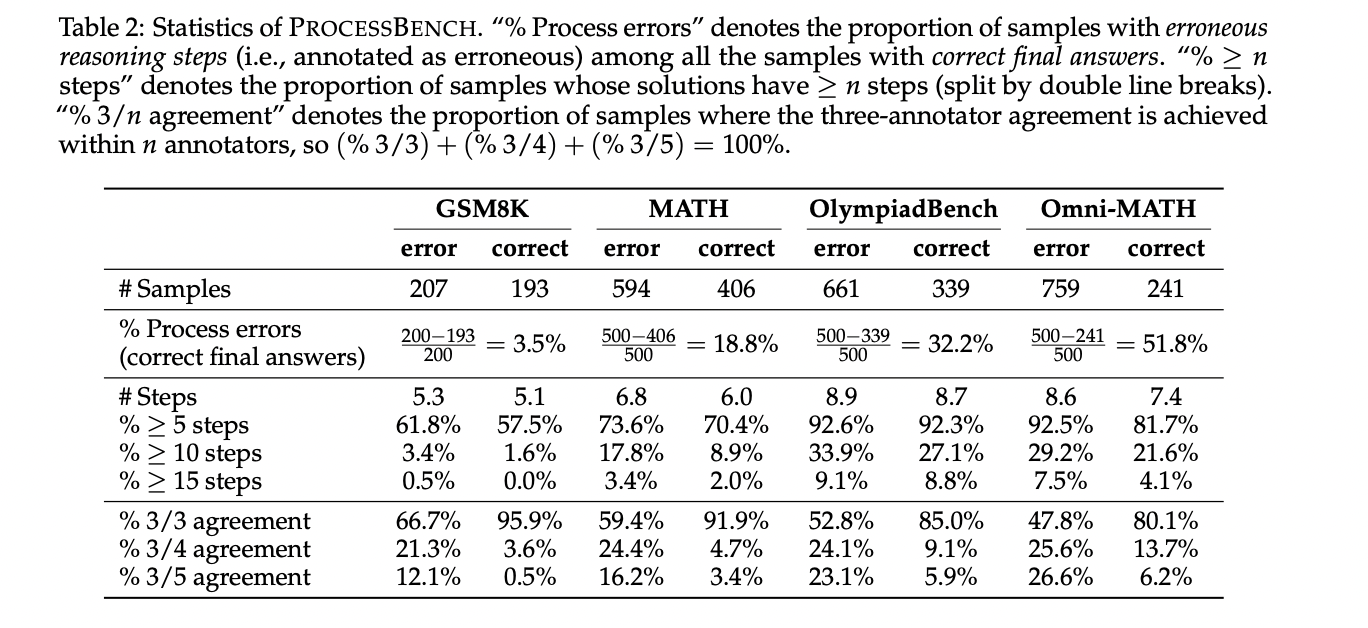
The researchers developed PROCESSBENCH by means of a meticulous technique of drawback curation, resolution era, and skilled annotation. They collected mathematical issues from 4 established datasets: GSM8K, MATH, OlympiadBench, and Omni-MATH, making certain a complete vary of drawback difficulties from grade faculty to competitors degree. Options had been generated utilizing open-source fashions from the Qwen and LLaMA sequence, creating twelve distinct resolution turbines to maximise resolution variety. To handle inconsistencies in resolution step formatting, the staff carried out a reformatting technique utilizing Qwen2.5-72B-Instruct to standardize step granularity, making certain logically full and progressive reasoning steps. This strategy helped preserve resolution content material integrity whereas making a extra uniform annotation framework for subsequent skilled analysis.
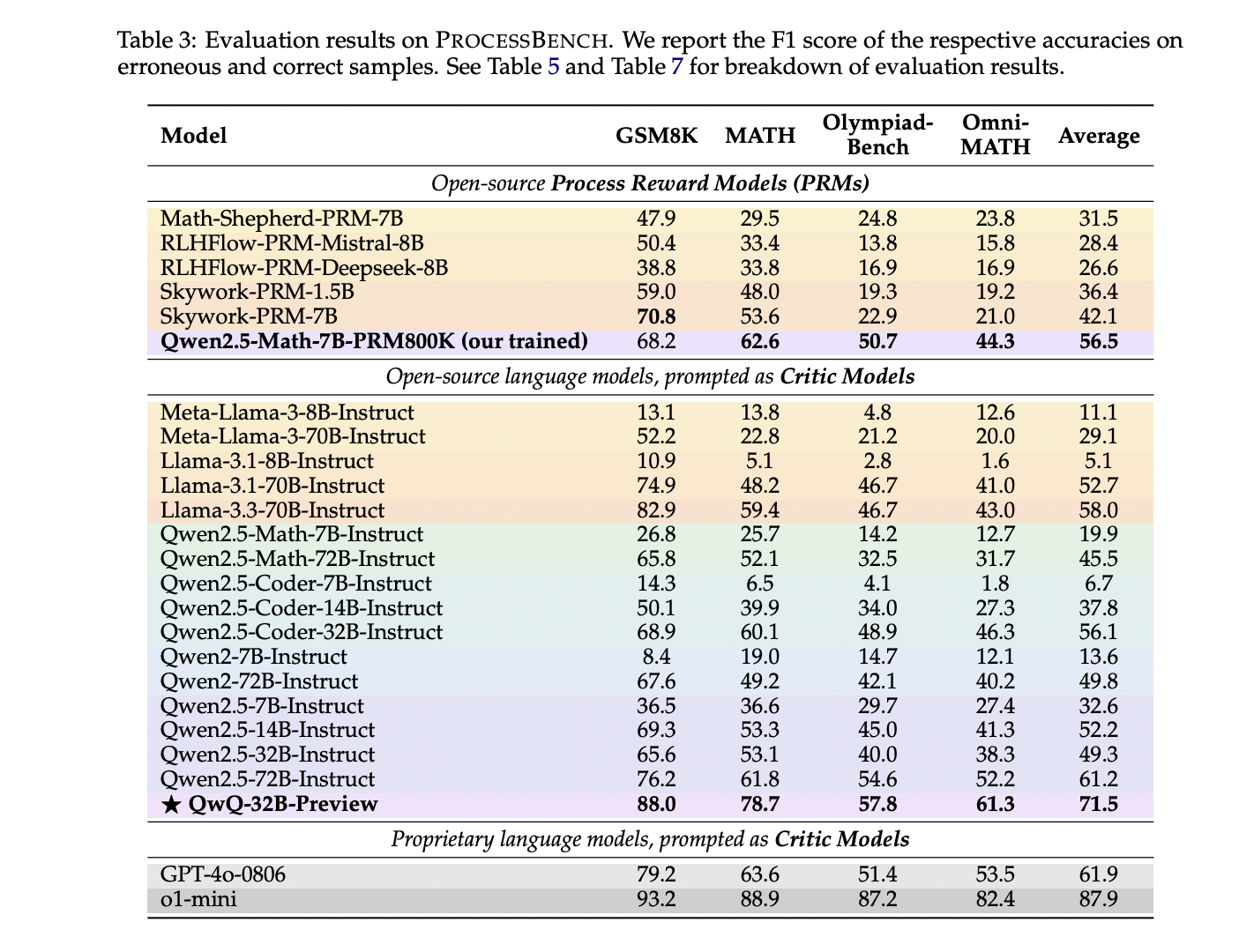
The analysis outcomes of PROCESSBENCH revealed a number of crucial insights into the efficiency of course of reward fashions (PRMs) and critic fashions throughout completely different mathematical drawback difficulties. As drawback complexity elevated from GSM8K and MATH to OlympiadBench and Omni-MATH, a constant efficiency decline was noticed throughout all fashions, highlighting important generalization challenges. Present PRMs demonstrated notably weaker efficiency in comparison with high prompt-driven critic fashions, notably on less complicated drawback units. The analysis uncovered basic limitations in present PRM improvement methodologies, which regularly depend on estimating step correctness based mostly on ultimate reply chances. These approaches inherently battle with the nuanced nature of mathematical reasoning, particularly when fashions can attain right solutions by means of flawed intermediate steps. The research emphasised the crucial want for extra strong error identification methods to precisely assess the reasoning course of past the correctness of the correctness of the ultimate reply.
This analysis introduces PROCESSBENCH as a pioneering benchmark for assessing language fashions’ capabilities in figuring out mathematical reasoning errors. By integrating high-difficulty issues, numerous resolution era, and rigorous human skilled annotation, the benchmark supplies a complete framework for evaluating error detection mechanisms. The research’s key findings spotlight important challenges in present course of reward fashions, notably their restricted potential to generalize throughout various drawback complexities. Additionally, the analysis reveals an rising panorama of open-source language fashions which might be progressively approaching the efficiency of proprietary fashions in crucial reasoning and error identification duties. These insights underscore the significance of growing extra subtle methodologies for understanding and enhancing synthetic intelligence’s reasoning processes.
Take a look at the Paper, GitHub Page, and Data on Hugging Face. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.