Massive Language Fashions (LLMs) are the spine of quite a few purposes, resembling conversational brokers, automated content material creation, and pure language understanding duties. Their effectiveness lies of their potential to mannequin and predict advanced language patterns from huge datasets. Nonetheless, creating LLMs presents a serious problem because of the immense computational value of coaching. This includes optimizing fashions with billions of parameters over huge corpora, requiring intensive {hardware} and time. Consequently, there’s a want for revolutionary coaching methodologies that may mitigate these challenges whereas sustaining or enhancing the standard of LLMs.
In creating LLMs, conventional coaching approaches are inefficient, as they deal with all knowledge equally, no matter complexity. These strategies don’t prioritize particular subsets of information that might expedite studying, nor do they leverage current fashions to help in coaching. This typically leads to pointless computational effort, as less complicated situations are processed alongside advanced ones with out differentiation. Additionally, commonplace self-supervised studying, the place fashions predict the subsequent token in a sequence, fails to make the most of the potential of smaller, much less computationally costly fashions that may inform and information the coaching of bigger fashions.
Information distillation (KD) is usually employed to switch data from bigger, well-trained fashions to smaller, extra environment friendly ones. Nonetheless, this course of has not often been reversed, the place smaller fashions help in coaching bigger ones. This hole represents a missed alternative, as smaller fashions, regardless of their restricted capability, can present precious insights into particular areas of the information distribution. They will effectively establish “simple” and “onerous” situations, which might considerably affect the coaching dynamics of LLMs.
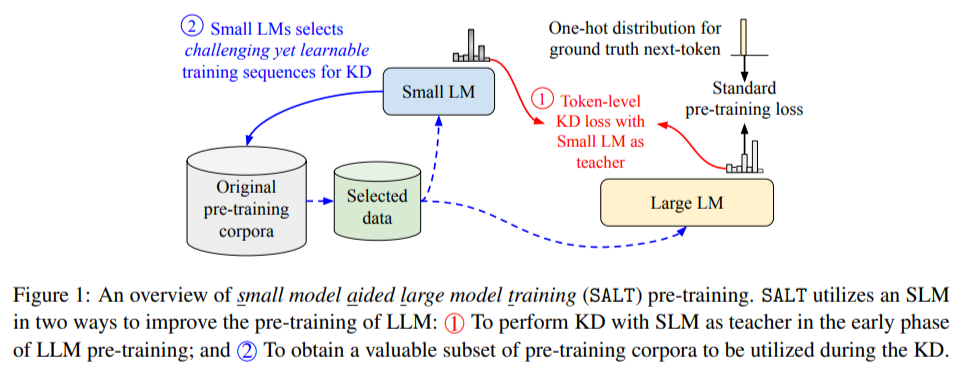
Google Analysis and Google DeepMind researchers launched a novel strategy known as Small mannequin Aided Large mannequin Training (SALT) to deal with the above challenges. This methodology innovatively employs smaller language fashions (SLMs) to enhance the effectivity of LLM coaching. SALT leverages SLMs in two methods: offering comfortable labels as an extra supply of supervision through the preliminary coaching part and deciding on subsets of information which are significantly precious for studying. The strategy ensures that LLMs are guided by SLMs in prioritizing informative and difficult knowledge sequences, thereby decreasing computational necessities whereas enhancing the general high quality of the educated mannequin.
SALT operates by way of a two-phase methodology:
- Within the first part, SLMs act as academics, transferring their predictive distributions to the LLMs by way of data distillation. This course of focuses on aligning the LLM’s predictions with these of the SLM in areas the place the latter excels. Additionally, SLMs establish subsets of information which are each difficult and learnable, enabling the LLM to focus on these crucial examples early in coaching.
- The second part transitions to conventional self-supervised studying, permitting the LLM to independently refine its understanding of extra advanced knowledge distributions.
This two-stage course of balances leveraging the strengths of SLMs and maximizing the inherent capabilities of LLMs.
In experimental outcomes, a 2.8-billion-parameter LLM educated with SALT on the Pile dataset outperformed a baseline mannequin educated utilizing typical strategies. Notably, the SALT-trained mannequin achieved higher outcomes on benchmarks resembling studying comprehension, commonsense reasoning, and pure language inference whereas using solely 70% of the coaching steps. This translated to a discount of roughly 28% in wall-clock coaching time. Additionally, the LLM pre-trained utilizing SALT demonstrated a 58.99% accuracy in next-token prediction in comparison with 57.7% for the baseline and exhibited a decrease log-perplexity of 1.868 versus 1.951 for the baseline, indicating enhanced mannequin high quality.

Key takeaways from the analysis embrace the next:
- SALT diminished the computational necessities for coaching LLMs by nearly 28%, primarily by using smaller fashions to information preliminary coaching phases.
- The strategy constantly produced better-performing LLMs throughout varied duties, together with summarization, arithmetic reasoning, and pure language inference.
- By enabling smaller fashions to pick out difficult but learnable knowledge, SALT ensured that LLMs centered on high-value knowledge factors, expediting studying with out compromising high quality.
- The strategy is especially promising for establishments with restricted computational sources. It leverages smaller, less expensive fashions to help in creating large-scale LLMs.
- After supervised fine-tuning, the SALT-trained fashions showcased higher generalization capabilities in few-shot evaluations and downstream duties.

In conclusion, SALT successfully redefines the paradigm of LLM coaching by reworking smaller fashions into precious coaching aids. Its revolutionary two-stage course of achieves a uncommon stability of effectivity and effectiveness, making it a pioneering strategy in machine studying. SALT will probably be instrumental in overcoming useful resource constraints, enhancing mannequin efficiency, and democratizing entry to cutting-edge AI applied sciences. This analysis underscores the significance of rethinking conventional practices and leveraging current instruments to attain extra with much less.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.