Reward features play a vital function in reinforcement studying (RL) programs, however their design presents important challenges in balancing job definition simplicity with optimization effectiveness. The standard method of utilizing binary rewards presents a simple job definition however creates optimization difficulties as a consequence of sparse studying alerts. Whereas intrinsic rewards have emerged as an answer to help coverage optimization, their crafting course of requires intensive task-specific information and experience, putting substantial calls for on human consultants who should rigorously stability a number of components to create reward features that precisely symbolize the specified job and allow environment friendly studying.
Current approaches have utilized Massive Language Fashions (LLMs) to automate reward design based mostly on pure language job descriptions, following two principal methodologies. The primary method focuses on producing reward operate codes by means of LLMs, which has proven success in steady management duties. Nonetheless, this technique faces limitations because it requires entry to surroundings supply code or detailed parameter descriptions and struggles with processing high-dimensional state representations. The second method entails producing reward values straight by means of LLMs, exemplified by strategies like Motif, which ranks commentary captions utilizing LLM preferences. Nonetheless, it requires pre-existing captioned commentary datasets and entails a time-consuming three-stage course of.
Researchers from Meta, the College of Texas Austin, and UCLA have proposed ONI, a novel distributed structure that concurrently learns RL insurance policies and intrinsic reward features utilizing LLM suggestions. The strategy makes use of an asynchronous LLM server to annotate the agent’s collected experiences, that are then remodeled into an intrinsic reward mannequin. The method explores numerous algorithmic strategies for reward modeling, together with hashing, classification, and rating fashions, to research their effectiveness in addressing sparse reward issues. This unified methodology achieves superior efficiency in difficult sparse reward duties throughout the NetHack Studying Setting, working solely on the agent’s gathered expertise with out requiring exterior datasets.
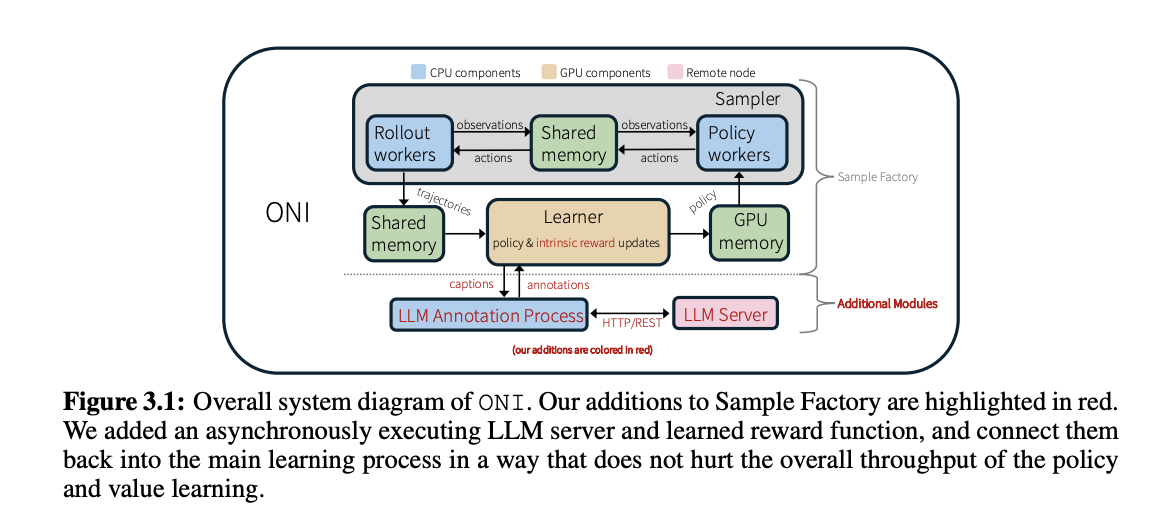
ONI makes use of a number of key elements constructed upon the Pattern Manufacturing facility library and its asynchronous variant proximal coverage optimization (APPO). The system operates with 480 concurrent surroundings cases on a Tesla A100-80GB GPU with 48 CPUs, attaining roughly 32k surroundings interactions per second. The structure incorporates 4 essential elements: an LLM server on a separate node, an asynchronous course of for transmitting commentary captions to the LLM server by way of HTTP requests, a hash desk for storing captions and LLM annotations, and a dynamic reward mannequin studying code. This asynchronous design maintains 80-95% of the unique system throughput, processing 30k surroundings interactions per second with out reward mannequin coaching and 26k interactions when coaching a classification-based reward mannequin.
The experimental outcomes exhibit important efficiency enhancements throughout a number of duties within the NetHack Studying Setting. Whereas the extrinsic reward agent performs adequately on the dense Rating job, it fails on sparse reward duties. ‘ONI-classification’ matches or approaches the efficiency of current strategies like Motif throughout most duties, attaining this with out pre-collected knowledge or further dense reward features. Amongst ONI variants, ‘ONI-retrieval’ reveals robust efficiency, whereas ‘ONI-classification’ constantly improves by means of its capacity to generalize to unseen messages. Furthermore, the ‘ONI-ranking’ achieves the very best expertise ranges, whereas ‘ONI-classification’ leads in different efficiency metrics in reward-free settings.
On this paper, researchers launched ONI which represents a big development in RL by introducing a distributed system that concurrently learns intrinsic rewards and agent behaviors on-line. It reveals state-of-the-art efficiency throughout difficult sparse reward duties within the NetHack Studying Setting whereas eliminating the necessity for pre-collected datasets or auxiliary dense reward features that have been beforehand important. This work establishes a basis for growing extra autonomous intrinsic reward strategies that may be taught completely from agent expertise, function independently of exterior dataset constraints, and successfully combine with high-performance reinforcement studying programs.
Take a look at the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….

Sajjad Ansari is a last 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a give attention to understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.