Proteins, the important molecular equipment of life, play a central function in quite a few organic processes. Decoding their intricate sequence, construction, and performance (SSF) is a elementary pursuit in biochemistry, molecular biology, and drug growth. Understanding the interaction between these three elements is essential for uncovering the rules of life at a molecular degree. Computational instruments have been developed to sort out this problem, with alignment-based strategies reminiscent of BLAST, MUSCLE, TM-align, MMseqs2, and Foldseek making vital strides. Nonetheless, these instruments usually prioritize effectivity by specializing in native alignments, which may restrict their means to seize international insights. Moreover, they usually function inside a single modality—sequence or construction—with out integrating a number of modalities. This limitation is compounded by the truth that practically 30% of proteins in UniProt stay unannotated because of their sequences being too divergent from identified useful counterparts.
Latest developments in neural network-based instruments have enabled extra correct useful annotation of proteins, figuring out corresponding labels for given sequences. Nonetheless, these strategies depend on predefined annotations and can’t interpret or generate detailed pure language descriptions of protein capabilities. The emergence of LLMs reminiscent of ChatGPT and LLaMA has showcased distinctive capabilities in pure language processing. Equally, the rise of protein language fashions (PLMs) has opened new avenues in computational biology. Constructing on these developments, researchers suggest making a foundational protein mannequin that leverages superior language modeling to characterize protein SSF holistically, addressing limitations in present approaches.
ProTrek, developed by researchers at Westlake College, is a cutting-edge tri-modal PLM that integrates SSF. Utilizing contrastive studying it aligns these modalities to allow speedy and correct searches throughout 9 SSF combos. ProTrek surpasses current instruments like Foldseek and MMseqs2 in pace (100x) and accuracy whereas outperforming ESM-2 in downstream prediction duties. Skilled on 40 million protein-text pairs, it provides international illustration studying to establish proteins with related capabilities regardless of structural or sequence variations. With its zero-shot retrieval and fine-tuning capabilities, ProTrek units new protein analysis and evaluation benchmarks.
Descriptive information from UniProt subsections have been categorized into sequence-level (e.g., perform descriptions) and residue-level (e.g., binding websites) to assemble protein-function pairs. GPT-4 was used to arrange residue-level information and paraphrase sequence-level descriptions, yielding 14M coaching pairs from Swiss-Prot. An preliminary ProTrek mannequin was pre-trained on this dataset after which used to filter UniRef50, producing a last dataset of 39M pairs. The coaching concerned InfoNCE and MLM losses, leveraging ESM-2 and PubMedBERT encoders with optimization methods like AdamW and DeepSpeed. ProTrek outperformed baselines on benchmarks utilizing 4,000 Swiss-Prot proteins and 104,000 UniProt negatives, evaluated by metrics like MAP and precision.
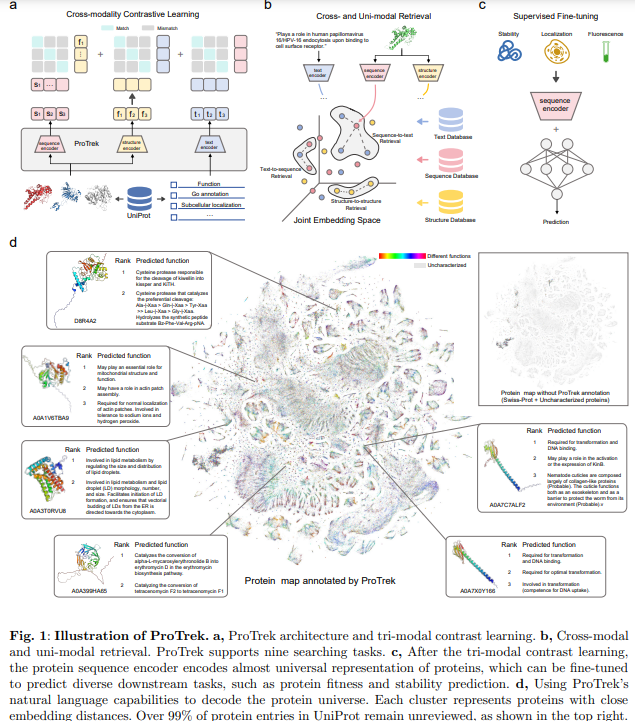
ProTrek represents a groundbreaking development in protein exploration by integrating sequence, construction, and pure language perform (SSF) into a complicated tri-modal language mannequin. Leveraging contrastive studying bridges the divide between protein information and human interpretation, enabling extremely environment friendly searches throughout 9 SSF pairwise modality combos. ProTrek delivers transformative enhancements, significantly in protein sequence-function retrieval, reaching 30-60 occasions the efficiency of earlier strategies. It additionally surpasses conventional alignment instruments reminiscent of Foldseek and MMseqs2, demonstrating over 100-fold pace enhancements and higher accuracy in figuring out functionally related proteins with various constructions. Moreover, ProTrek constantly outperforms the state-of-the-art ESM-2 mannequin, excelling in 9 out of 11 downstream duties and setting new requirements in protein intelligence.
These capabilities set up ProTrek as a pivotal protein analysis and database evaluation software. Its exceptional efficiency stems from its in depth coaching dataset, which is considerably bigger than comparable fashions. ProTrek’s pure language understanding capabilities transcend typical keyword-matching approaches, enabling context-aware searches and advancing purposes reminiscent of text-guided protein design and protein-specific ChatGPT programs. ProTrek empowers researchers to research huge protein databases effectively and tackle complicated protein-text interactions by offering superior pace, accuracy, and flexibility, paving the best way for vital developments in protein science and engineering.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.