Giant Language Fashions (LLMs) have revolutionized textual content era capabilities, however they face the crucial problem of hallucination, producing factually incorrect info, notably in long-form content material. Researchers have developed Retrieved-Augmented Era (RAG) to handle this difficulty, which reinforces factual accuracy by incorporating related paperwork from dependable sources into the enter immediate. Whereas RAG has proven promise, varied iterative prompting strategies like FLARE and Self-RAG have emerged to enhance accuracy additional. Nonetheless, these approaches stay restricted by their reliance on conventional RAG structure, the place retrieved context is the one type of on-line suggestions built-in into the enter string.
Conventional textual content era approaches have developed by a number of key methodologies to enhance factual accuracy and contextual relevance. The iterative retrieval strategies generate responses in segments with every phase using newly retrieved info. ITER-RETGEN exemplifies this method by utilizing earlier outputs to formulate queries for subsequent information retrieval. Adaptive retrieval programs like FLARE and DRAGIN have refined this course of by implementing sentence-by-sentence era with confidence-based verification. Furthermore, long-context LLMs have explored memory-based approaches like Memory3, which encode information chunks utilizing KV caches as reminiscences. Different programs like Memorizing Transformers and LongMem have experimented with reminiscence retrieval mechanisms.
A group of researchers from Meta FAIR has proposed EWE (Express Working Reminiscence), an revolutionary AI method that enhances factual accuracy in long-form textual content era by implementing a dynamic working reminiscence system. This technique uniquely incorporates real-time suggestions from exterior sources and employs on-line fact-checking mechanisms to refresh its reminiscence repeatedly. The important thing innovation lies in its skill to detect and proper false claims throughout the era course of itself, quite than relying solely on pre-retrieved info. Furthermore, the effectiveness of EWE has been proven by complete testing on 4 fact-seeking long-form era datasets, displaying vital enhancements in factuality metrics whereas sustaining response high quality.
The structure of EWE represents a flexible framework that may adapt to varied configurations whereas sustaining effectivity. At its core, EWE makes use of a multi-unit reminiscence module that may be dynamically up to date throughout era. This design permits EWE to function in numerous modes from easy RAG when utilizing a single reminiscence unit with out stopping, to FLARE-like performance when implementing sentence-level verification. In contrast to comparable approaches comparable to Memory3, EWE doesn’t require pre-encoding of all passages and uniquely options dynamic reminiscence updates throughout the era course of. This flexibility permits parallel processing of various types of exterior suggestions by distinct reminiscence items.
The experimental outcomes exhibit vital enhancements in factual accuracy throughout a number of datasets. Utilizing the Llama-3.1 70B base mannequin, retrieval augmentation persistently enhances factuality metrics. Whereas competing approaches present blended outcomes with Nest performing effectively solely on Biography datasets and DRAGIN displaying comparable efficiency to fundamental retrieval augmentation, EWE achieves the best VeriScore F1 throughout all datasets. CoVe, regardless of excessive precision, produces shorter responses leading to decrease recall efficiency. EWE maintains comparable efficiency to the bottom mannequin with roughly 50% win charges in helpfulness, measured by AlpacaEval.
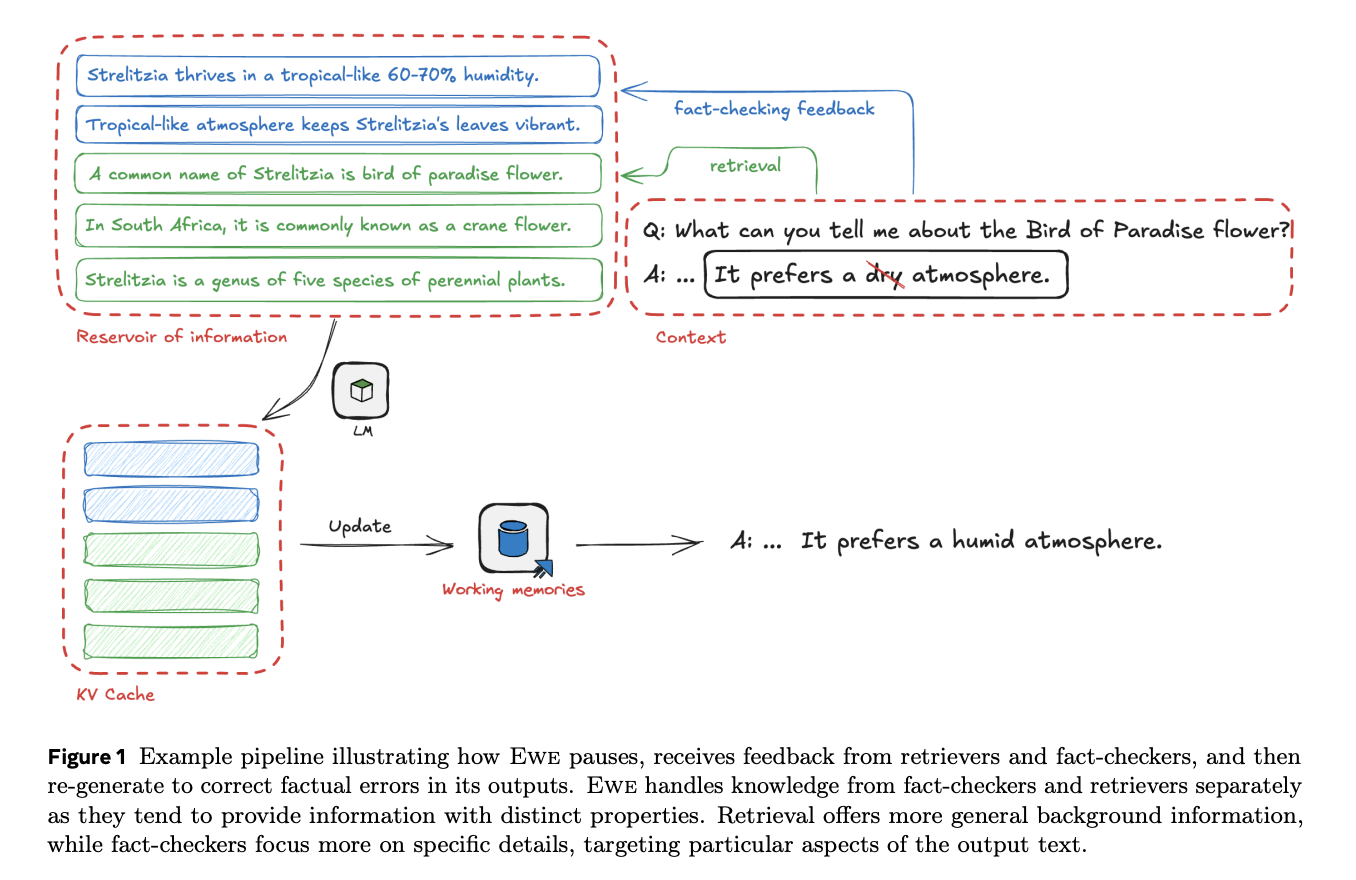
In conclusion, a group from Meta FAIR has launched EWE (Express Working Reminiscence) which represents a big development in addressing the problem of factual accuracy in long-form textual content era. The system’s revolutionary working reminiscence mechanism, which operates by periodic pauses and reminiscence refreshes based mostly on retrieval and fact-checking suggestions, demonstrates the potential for extra dependable AI-generated content material. This analysis has recognized crucial success elements together with well timed reminiscence updates, centered consideration mechanisms, and high-quality retrieval knowledge shops, paving the best way for future developments in factual textual content era programs.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.

Sajjad Ansari is a remaining 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.