Giant Language Fashions (LLMs) have emerged as transformative instruments in analysis and business, with their efficiency straight correlating to mannequin dimension. Nonetheless, coaching these large fashions presents important challenges, associated to computational sources, time, and value. The coaching course of for state-of-the-art fashions like Llama 3 405B requires intensive {hardware} infrastructure, using as much as 16,000 H100 GPUs over 54 days. Equally, fashions like GPT-4, estimated to have one trillion parameters, demand extraordinary computational energy. These useful resource necessities create obstacles to entry and improvement within the area, highlighting the essential want for extra environment friendly coaching methodologies for advancing LLM expertise whereas decreasing the related computational burden.
Varied approaches have been explored to handle the computational challenges in LLM coaching and inference. Blended Precision Coaching has been extensively adopted to speed up mannequin coaching whereas sustaining accuracy, initially specializing in CNNs and DNNs earlier than increasing to LLMs. For inference optimization, Publish-Coaching Quantization (PTQ) and Quantization Conscious Coaching (QAT) have achieved important compression utilizing 4-bit, 2-bit, and even 1-bit quantization. Whereas differentiable quantization methods have been proposed utilizing learnable parameters up to date by way of backpropagation, they face limitations in dealing with activation outliers successfully. Current options for managing outliers rely on offline pre-processing strategies, making them impractical for direct utility in coaching eventualities.
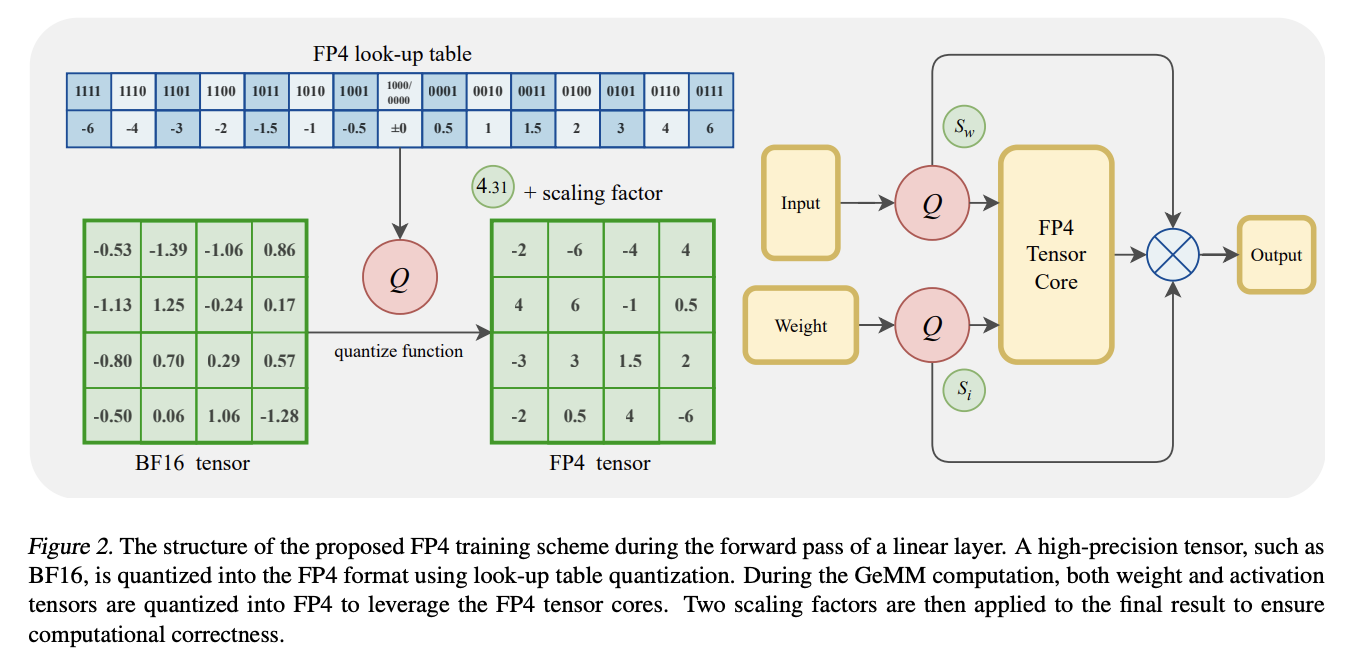
Researchers from the College of Science and Expertise of China, Microsoft SIGMA Staff, and Microsoft Analysis Asia have proposed a framework for coaching language fashions utilizing the FP4 format, marking the primary complete validation of this ultra-low precision illustration. The framework addresses quantization errors by way of two key improvements:
- A differentiable quantization estimator for weights that enhances gradient updates in FP4 computations by incorporating correction phrases
- An outlier dealing with mechanism for activations that mixes clamping with a sparse auxiliary matrix.
These methods assist to take care of mannequin efficiency whereas enabling environment friendly coaching in ultra-low precision codecs, representing a big development in environment friendly LLM coaching.
The framework primarily targets Basic Matrix Multiplication (GeMM) operations, containing over 95% of LLM coaching computations. The structure implements 4-bit quantization for GeMM operations utilizing distinct quantization approaches: token-wise quantization for activation tensors and channel-wise quantization for weight tensors. Resulting from {hardware} limitations, the system’s efficiency is validated utilizing Nvidia H-series GPUs’ FP8 Tensor Cores, which may precisely simulate FP4’s dynamic vary. The framework employs FP8 gradient communication and a mixed-precision Adam optimizer for reminiscence effectivity. The system was validated utilizing the LLaMA 2 structure, educated from scratch on the DCLM dataset, with fastidiously tuned hyperparameters together with a warm-up and cosine decay studying charge schedule, and particular parameters for the FP4 methodology’s distinctive elements.
The proposed FP4 coaching framework exhibits that coaching curves for LLaMA fashions of 1.3B, 7B, and 13B parameters have comparable patterns between FP4 and BF16 implementations, with FP4 exhibiting marginally increased coaching losses: 2.55 vs. 2.49 (1.3B), 2.17 vs. 2.07 (7B), and 1.97 vs. 1.88 (13B) after 100B tokens of coaching. Zero-shot evaluations throughout various downstream duties, together with Arc, BoolQ, HellaSwag, LogiQA, PiQA, SciQ, OpenbookQA, and Lambada, reveal that FP4-trained fashions obtain aggressive or often superior efficiency in comparison with their BF16 counterparts. The outcomes exhibit that bigger fashions obtain increased accuracy, validating the scalability of the FP4 coaching method.
In conclusion, researchers have efficiently developed and validated the primary FP4 pretraining framework for LLMs, marking a big development in ultra-low-precision computing. The framework achieves efficiency corresponding to higher-precision codecs throughout varied mannequin scales by way of revolutionary options just like the differentiable gradient estimator and outlier compensation mechanism. Nonetheless, the present implementation faces a notable limitation: the shortage of devoted FP4 Tensor Cores in present {hardware} necessitates simulation-based testing, which introduces computational overhead and prevents direct measurement of potential effectivity good points. This limitation underscores the necessity for {hardware} development to comprehend the advantages of FP4 computation.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)

Sajjad Ansari is a closing yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.