Reinforcement studying (RL) trains brokers to make sequential choices by maximizing cumulative rewards. It has various purposes, together with robotics, gaming, and automation, the place brokers work together with environments to be taught optimum behaviors. Conventional RL strategies fall into two classes: model-free and model-based approaches. Mannequin-free strategies prioritize simplicity however require in depth coaching information, whereas model-based strategies introduce structured studying however are computationally demanding. A rising space of analysis goals to bridge these approaches and develop extra versatile RL frameworks that operate effectively throughout totally different domains.
A persistent problem in RL is the absence of a common algorithm able to performing persistently throughout a number of environments with out exhaustive parameter tuning. Most RL algorithms are designed for particular purposes, necessitating changes to work successfully in new settings. Mannequin-based RL strategies typically exhibit superior generalization however at the price of larger complexity and slower execution speeds. Then again, model-free strategies are simpler to implement however usually lack effectivity when utilized to unfamiliar duties. Growing an RL framework that integrates the strengths of each approaches with out compromising computational feasibility stays a key analysis goal.
A number of RL methodologies have emerged, every with trade-offs between efficiency and effectivity. Mannequin-based options reminiscent of DreamerV3 and TD-MPC2 have achieved substantial outcomes throughout totally different duties however rely closely on complicated planning mechanisms and large-scale simulations. Mannequin-free options, together with TD3 and PPO, supply lowered computational calls for however require domain-specific tuning. This disparity underscores the necessity for an RL algorithm that mixes adaptability and effectivity, enabling seamless utility throughout numerous duties and environments.
A analysis workforce from Meta FAIR launched MR.Q, a model-free RL algorithm incorporating model-based representations to enhance studying effectivity and generalization. In contrast to conventional model-free approaches, MR.Q leverages a illustration studying part impressed by model-based aims, enabling the algorithm to operate successfully throughout totally different RL benchmarks with minimal tuning. This method permits MR.Q to profit from the structured studying alerts of model-based strategies whereas avoiding the computational overhead related to full-scale planning and simulated rollouts.
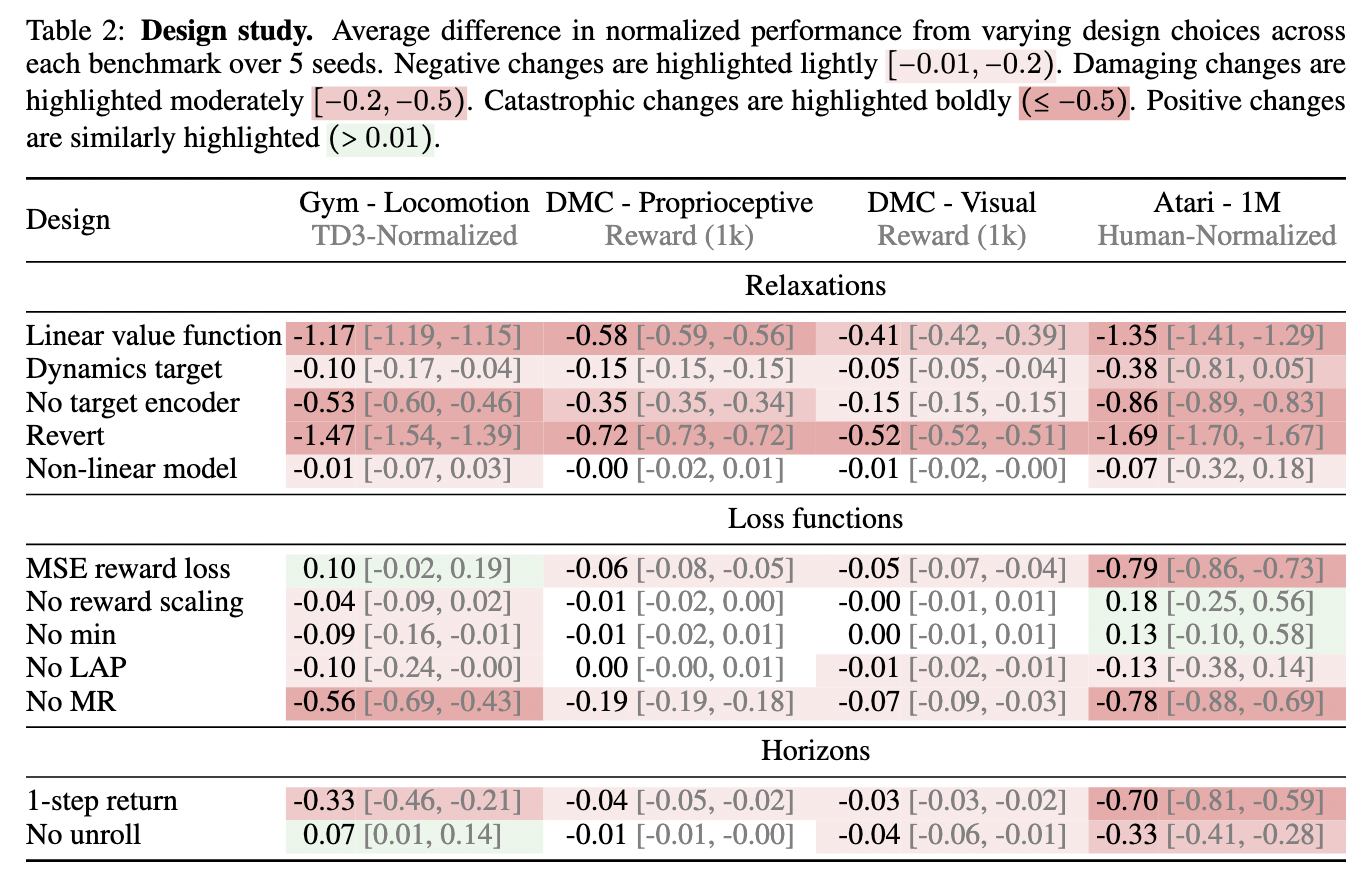
The MR.Q framework maps state-action pairs into embeddings that preserve an roughly linear relationship with the worth operate. These embeddings are then processed by means of a non-linear operate to retain consistency throughout totally different environments. The system integrates an encoder that extracts related options from state and motion inputs, enhancing studying stability. Additional, MR.Q employs a prioritized sampling approach and a reward scaling mechanism to enhance coaching effectivity. The algorithm achieves strong efficiency throughout a number of RL benchmarks whereas sustaining computational effectivity by specializing in an optimized studying technique.
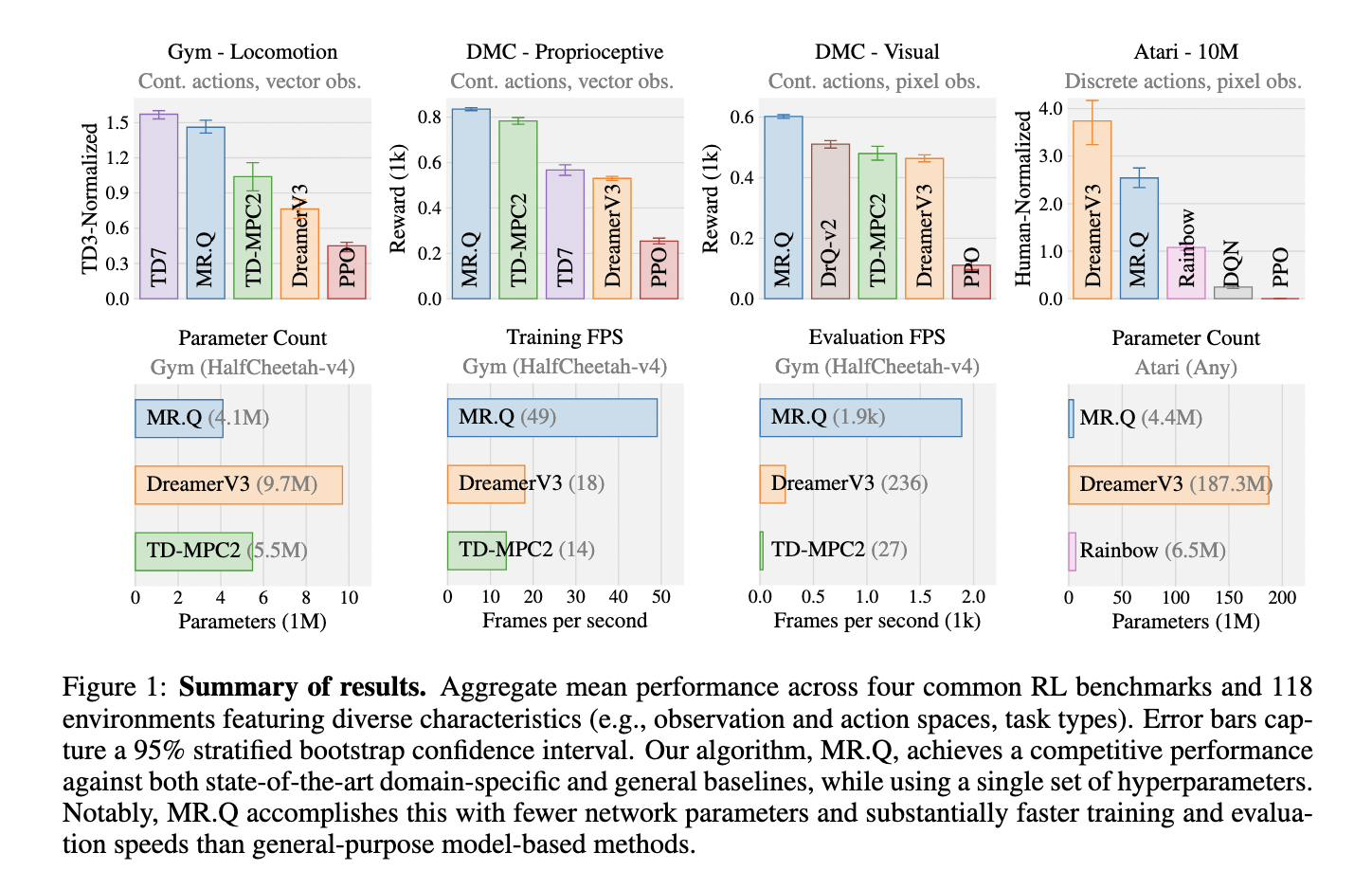
Experiments carried out throughout 4 RL benchmarks—Gymnasium locomotion duties, DeepMind Management Suite, and Atari—exhibit that MR.Q achieves robust outcomes with a single set of hyperparameters. The algorithm outperforms typical model-free baselines like PPO and DQN whereas sustaining comparable efficiency to DreamerV3 and TD-MPC2. MR.Q achieves aggressive outcomes whereas using considerably fewer computational assets, making it a sensible alternative for real-world purposes. Within the Atari benchmark, MR.Q performs notably properly in discrete-action areas, surpassing current strategies. MR.Q demonstrates robust efficiency in steady management environments, surpassing model-free baselines reminiscent of PPO and DQN whereas sustaining aggressive outcomes in comparison with DreamerV3 and TD-MPC2. The algorithm achieves important effectivity enhancements throughout benchmarks with out requiring in depth reconfiguration for various duties. The analysis additional highlights MR.Q’s means to generalize successfully with out requiring in depth reconfiguration for brand new duties.
The examine underscores the advantages of incorporating model-based representations into model-free RL algorithms. MR.Q marks a step towards growing a really versatile RL framework by enhancing effectivity and flexibility. Future developments might refine its method to handle challenges reminiscent of onerous exploration issues and non-Markovian environments. The findings contribute to the broader purpose of constructing RL strategies extra accessible and efficient for a lot of purposes, positioning MR.Q as a promising instrument for researchers and practitioners searching for strong RL options.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 70k+ ML SubReddit.
🚨 Meet IntellAgent: An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.