Aligning massive language fashions (LLMs) with human values stays troublesome because of unclear objectives, weak coaching indicators, and the complexity of human intent. Direct Alignment Algorithms (DAAs) supply a strategy to simplify this course of by optimizing fashions instantly with out counting on reward modeling or reinforcement studying. These algorithms use totally different rating strategies, corresponding to evaluating pairs of outputs or scoring particular person responses. Some variations additionally require an additional fine-tuning step, whereas others don’t. There are additional problems in understanding how efficient they’re and which strategy is greatest due to variations in how rewards are outlined and utilized.
At present, strategies for aligning massive language fashions (LLMs) observe a number of steps, together with supervised fine-tuning (SFT), reward modeling, and reinforcement studying. These strategies introduce challenges because of their complexity, dependence on reward fashions, and excessive computational price. DAAs attempt to optimize fashions from human preferences instantly, bypassing reinforcement studying and reward modeling. Completely different types of DAAs could differ of their optimization methodology, loss features, and fine-tuning methodology. Regardless of their potential to simplify alignment, inconsistencies in rating strategies, reward calculations, and coaching methods create additional difficulties in evaluating their effectiveness.
To enhance single-stage direct alignment algorithms (DAAs) like ORPO and ASFT, researchers proposed including a separate supervised fine-tuning (SFT) section and introducing a scaling parameter (β). These strategies have been initially not supplied with a β parameter and did alignment instantly. As such, they have been much less efficient. Together with an specific SFT section and letting β management choice scaling offers these strategies efficiency similar to two-stage approaches corresponding to DPO. The principle distinction between totally different DAAs lies in whether or not they use an odds ratio or a reference coverage ratio, which impacts how alignment is optimized.
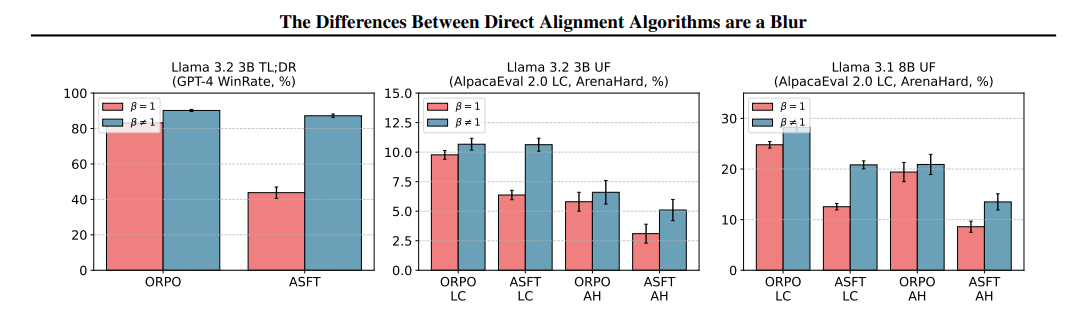
The framework modifies the loss features of ASFT and ORPO to incorporate SFT in an implicit manner, making them adaptable to single-stage and two-stage configurations. The scaling parameter β is used to regulate the power of choice updates towards higher management in optimization. Experimental evaluation means that DAAs counting on pairwise comparisons outperform these counting on pointwise preferences, thus warranting structured rating indicators in alignment high quality.

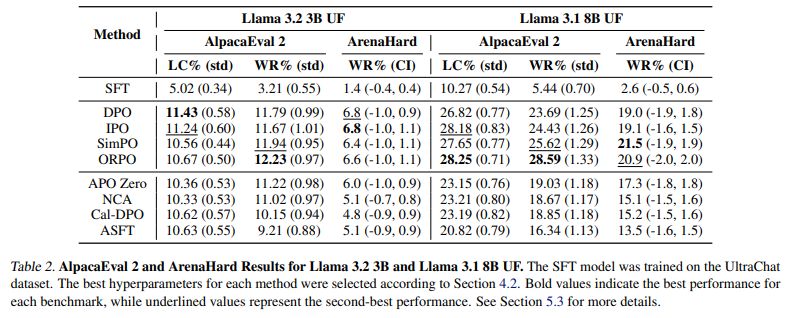
Researchers evaluated Direct Alignment Algorithms (DAA) utilizing Llama 3.1 8B on UltraChat and UF datasets, testing on AlpacaEval 2 and ArenaHard, whereas Llama 3.2 3B was used for Reddit TL; DR. Supervised fine-tuning (SFT) on UF improved ORPO and ASFT alignment. ORPO carried out on par with DPO and ASFT, attaining a +2.04% enhance in ArenaHard win charge however nonetheless lagging behind ORPO. β tuning considerably enhanced efficiency, yielding enhancements of +7.0 and +43.4 in GPT-4 win charge for TL;DR and +3.46 and +8.27 in UF AlpacaEval 2 LC win charge. Comparative evaluation of DPO, IPO, SimPO, and different alignment strategies confirmed that β changes in LβASFTAlign and LβORPOAlign improved choice optimization, demonstrating that SFT-trained fashions carried out greatest when incorporating LAlign elements.
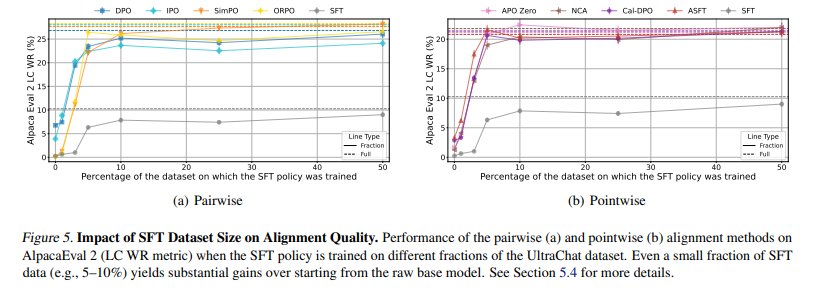
In the long run, the proposed methodology improved Direct Alignment Algorithms (DAAs) by incorporating a supervised fine-tuning (SFT) section. This led to constant efficiency features and considerably enhanced ORPO and ASFT. Though the analysis was carried out on particular datasets and mannequin sizes, the findings present a structured strategy for enhancing mannequin alignment. This methodology is a basis for use as a foundation for future analysis. It may be extrapolated to different bigger fashions with extra numerous information units to refine alignment strategies by way of optimization methods that determine components in alignment high quality.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and clear up challenges.