Giant basis fashions have demonstrated outstanding potential in biomedical functions, providing promising outcomes on numerous benchmarks and enabling fast adaptation to downstream duties with minimal labeled knowledge necessities. Nonetheless, important challenges persist in implementing these fashions in medical settings. Even superior fashions like GPT-4V present appreciable efficiency gaps in multimodal biomedical functions. Furthermore, sensible boundaries resembling restricted accessibility, excessive operational prices, and the complexity of handbook analysis processes create substantial obstacles for clinicians making an attempt to make the most of these state-of-the-art fashions with non-public affected person knowledge.
Latest developments in multimodal generative AI have expanded biomedical functions to deal with textual content and pictures concurrently, exhibiting promise in duties like visible query answering and radiology report era. Nonetheless, these fashions pose challenges of their medical implementation. Giant fashions’ useful resource necessities pose deployment challenges in computational prices and environmental influence. Small Multimodal Fashions (SMMs), whereas extra environment friendly, nonetheless present important efficiency gaps in comparison with bigger counterparts. Moreover, the shortage of accessible open-source fashions and dependable analysis strategies for factual correctness, notably regarding hallucination detection, creates substantial boundaries to medical adoption.
Researchers from Microsoft Analysis, the College of Washington, Stanford College, the College of Southern California, the College of California Davis, and the College of California San Francisco have proposed LLaVA-Rad, a novel Small Multimodal Mannequin (SMM), alongside CheXprompt, an computerized scoring metric for factual correctness. The system focuses on chest X-ray (CXR) imaging, the most typical medical imaging examination for robotically producing high-quality radiology reviews. LLaVA-Rad is educated on a dataset of 697,435 radiology image-report pairs from seven various sources, using GPT-4 for report synthesis when solely structured labels have been accessible. The system demonstrates environment friendly efficiency, requiring only a single V100 GPU for inference and finishing coaching in in the future utilizing an 8-A100 cluster.
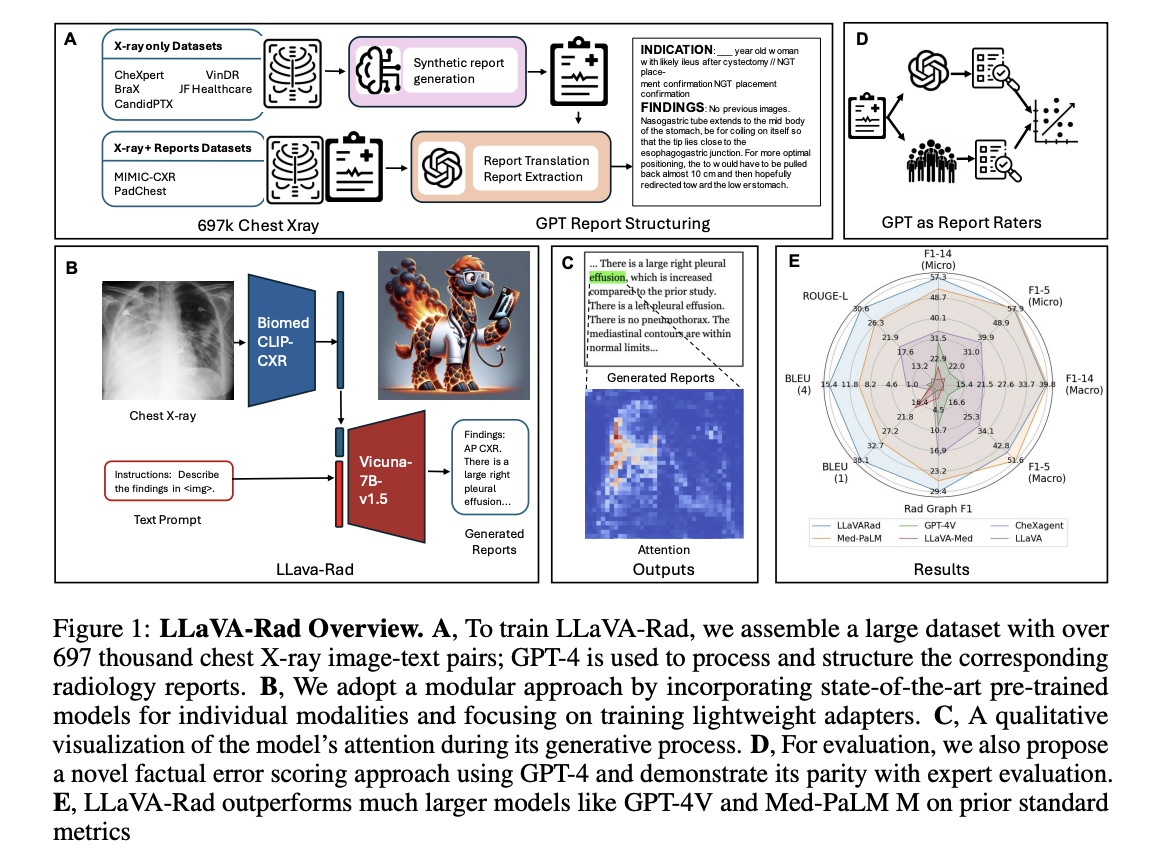
LLaVA-Rad’s structure represents a novel method to Small Multimodal Fashions (SMMs), reaching superior efficiency regardless of being considerably smaller than fashions like Med-PaLM M. The mannequin’s design philosophy facilities on decomposing the coaching course of into distinct phases: unimodal pretraining and light-weight cross-modal studying. The structure makes use of an environment friendly adapter mechanism to floor non-text modalities into the textual content embedding house. The coaching course of unfolds in three levels: pre-training, alignment, and fine-tuning. This modular method makes use of a various dataset of 697,000 de-identified chest X-ray photos and related radiology reviews from 258,639 sufferers throughout seven completely different datasets, enabling strong unimodal mannequin growth and efficient cross-modal adaptation.
LLaVA-Rad exhibits distinctive efficiency in comparison with similar-sized fashions (7B parameters) like LLaVA-Med, CheXagent, and MAIRA-1. Regardless of being considerably smaller, it outperforms the main mannequin Med-PaLM M in essential metrics, reaching a 12.1% enchancment in ROUGE-L and 10.1% in F1-RadGraph for radiology textual content analysis. The mannequin maintains constant superior efficiency throughout a number of datasets, together with CheXpert and Open-I, even when examined on beforehand unseen knowledge. This efficiency is attributed to LLaVA-Rad’s modular design and data-efficient structure. Whereas Med-PaLM M exhibits marginally higher outcomes (<1% enchancment) in F1-5 CheXbert metrics, LLaVA-Rad’s general efficiency and computational effectivity make it extra sensible for real-world functions.
On this paper, researchers launched LLaVA-Rad which represents a big development in making basis fashions sensible for medical settings, providing an open-source, light-weight resolution that achieves state-of-the-art efficiency in radiology report era. The mannequin’s success stems from its complete coaching on 697,000 chest X-ray photos with related reviews, using GPT-4 for dataset processing and implementing a novel three-stage curriculum coaching technique. Furthermore, the introduction of CheXprompt solves the essential problem of computerized analysis, offering accuracy evaluation corresponding to skilled radiologists. These developments mark a big step towards bridging the hole between technological capabilities and medical wants.
Try the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 75k+ ML SubReddit.

Sajjad Ansari is a remaining yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a give attention to understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.