Massive language fashions (LLMs) have demonstrated proficiency in fixing complicated issues throughout arithmetic, scientific analysis, and software program engineering. Chain-of-thought (CoT) prompting is pivotal in guiding fashions by means of intermediate reasoning steps earlier than reaching conclusions. Reinforcement studying (RL) is one other important element that allows structured reasoning, permitting fashions to acknowledge and proper errors effectively. Regardless of these developments, the problem stays in extending CoT lengths whereas sustaining accuracy, significantly in specialised domains the place structured reasoning is important.
A key subject in enhancing reasoning talents in LLMs lies in producing lengthy and structured chains of thought. Current fashions battle with high-complexity duties that require iterative reasoning, comparable to PhD-level scientific problem-solving and aggressive arithmetic. Merely scaling the mannequin measurement and coaching knowledge doesn’t assure improved CoT capabilities. Moreover, RL-based coaching calls for exact reward shaping, as improper reward mechanisms may end up in counterproductive studying behaviors. The analysis goals to determine the basic components influencing CoT emergence and design optimum coaching methods to stabilize and enhance long-chain reasoning.
Beforehand, researchers have employed supervised fine-tuning (SFT) and reinforcement studying to boost CoT reasoning in LLMs. SFT is usually used to initialize fashions with structured reasoning examples, whereas RL is utilized to fine-tune and prolong reasoning capabilities. Nonetheless, conventional RL approaches lack stability when growing CoT size, usually resulting in inconsistent reasoning high quality. Verifiable reward indicators, comparable to ground-truth accuracy, are important for stopping fashions from participating in reward hacking, the place the mannequin learns to optimize for rewards with out genuinely bettering reasoning efficiency. Regardless of these efforts, present coaching methodologies lack a scientific strategy to successfully scaling and stabilizing lengthy CoTs.
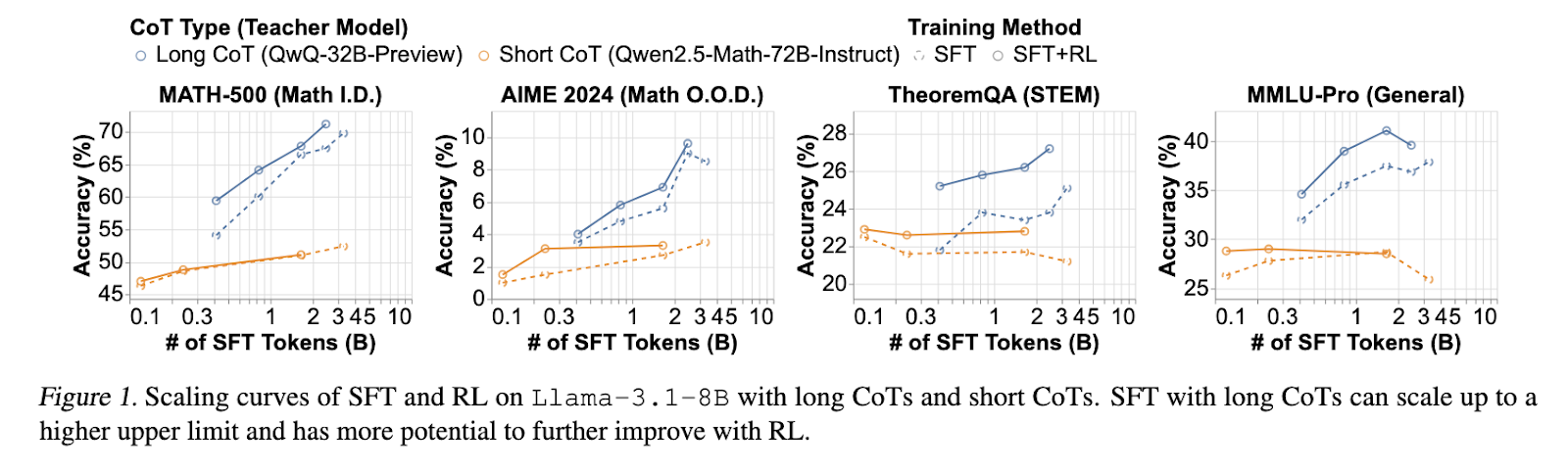
Researchers from Carnegie Mellon College and IN.AI launched a complete framework to research and optimize lengthy CoT reasoning in LLMs. Their strategy centered on figuring out the underlying mechanics of long-chain reasoning, experimenting with numerous coaching methodologies to evaluate their impression. The staff systematically examined SFT and RL methods, emphasizing the significance of structured reward shaping. A novel cosine length-scaling reward with a repetition penalty was developed to encourage fashions to refine their reasoning methods, comparable to branching and backtracking, resulting in simpler problem-solving processes. Additional, the researchers explored incorporating web-extracted options as verifiable reward indicators to boost the educational course of, significantly for out-of-distribution (OOD) duties like STEM problem-solving.
The coaching methodology concerned in depth experimentation with totally different base fashions, together with Llama-3.1-8B and Qwen2.5-7B-Math, every representing general-purpose and mathematics-specialized fashions, respectively. The researchers used a dataset of seven,500 coaching pattern prompts from MATH, making certain entry to verifiable ground-truth options. Preliminary coaching with SFT offered the muse for lengthy CoT improvement, adopted by RL optimization. A rule-based verifier was employed to match generated responses with appropriate solutions, making certain stability within the studying course of. The staff launched a repetition penalty mechanism to refine reward shaping additional, discouraging fashions from producing redundant reasoning paths whereas incentivizing environment friendly problem-solving. The staff additionally analyzed knowledge extracted from net corpora, assessing the potential of noisy however numerous supervision indicators in refining CoT size scaling.

The analysis findings revealed a number of important insights into lengthy CoT reasoning. Fashions skilled with lengthy CoT SFT constantly achieved superior accuracy than these initialized with brief CoT SFT. On the MATH-500 benchmark, lengthy CoT SFT fashions noticed a big enchancment, with accuracy exceeding 70%, whereas brief CoT SFT fashions stagnated under 55%. RL fine-tuning additional enhanced lengthy CoT fashions, offering an extra 3% absolute accuracy acquire. The introduction of the cosine length-scaling reward proved efficient in stabilizing reasoning trajectories, stopping extreme or unstructured CoT development. Furthermore, fashions incorporating filtered web-extracted options demonstrated improved generalization capabilities, significantly in OOD benchmarks comparable to AIME 2024 and TheoremQA, the place accuracy positive factors of 15-50% had been recorded. The analysis additionally confirmed that core reasoning expertise, comparable to error validation and correction, are inherently current in base fashions. Nonetheless, efficient RL coaching is important to strengthen these talents effectively.
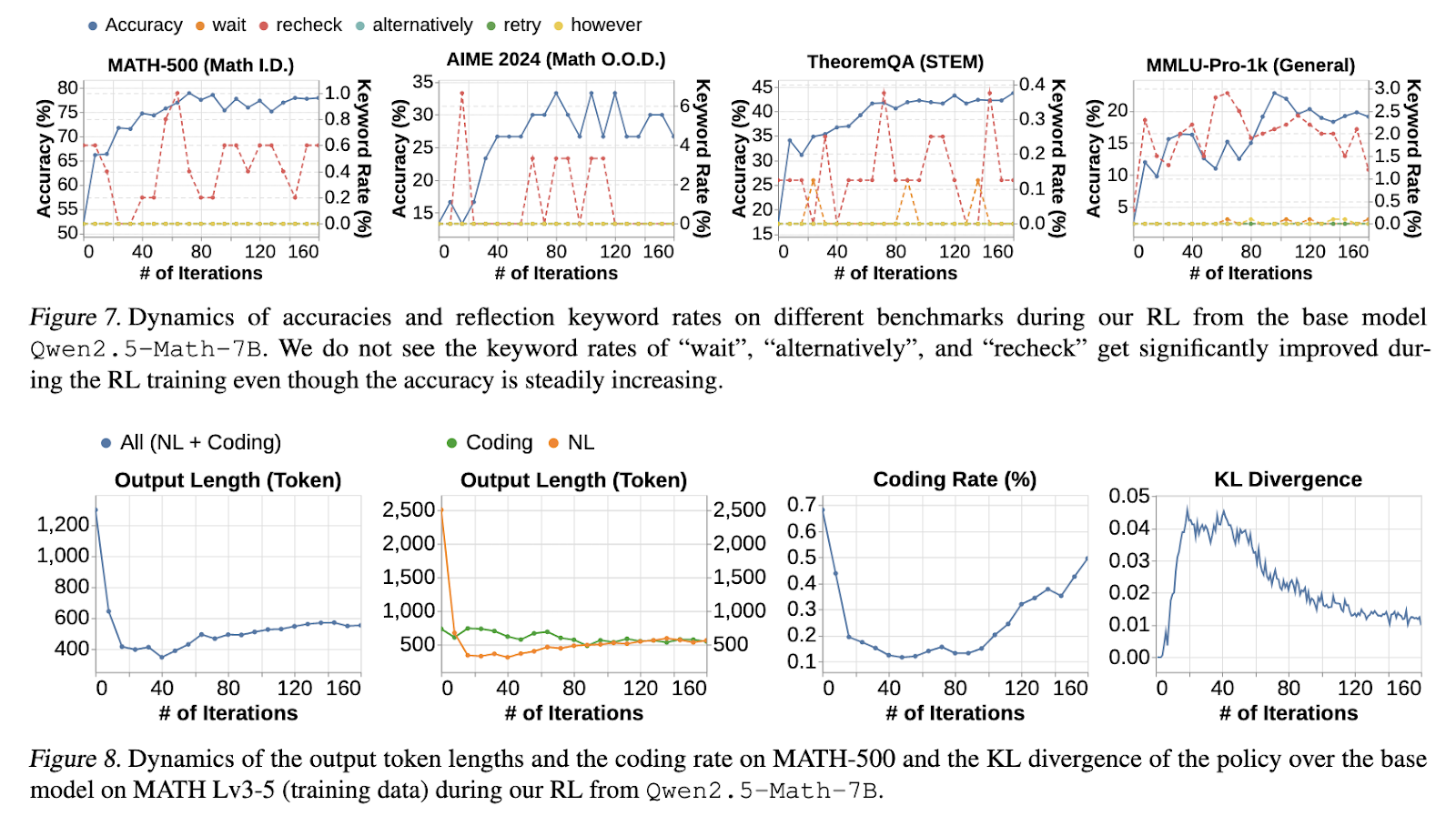
The examine considerably advances understanding and optimizing lengthy CoT reasoning in LLMs. The researchers efficiently recognized key coaching components that improve structured reasoning, emphasizing the significance of supervised fine-tuning, verifiable reward indicators, and thoroughly designed reinforcement studying methods. The findings spotlight the potential for additional analysis in refining RL methodologies, optimizing reward-shaping mechanisms, and leveraging numerous knowledge sources to boost mannequin reasoning capabilities. The examine’s contributions supply priceless insights for the long run improvement of AI fashions with sturdy, interpretable, and scalable reasoning talents.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 75k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.