Massive Language Fashions (LLMs) have revolutionized pure language processing (NLP) however face important challenges in sensible functions attributable to their massive computational calls for. Whereas scaling these fashions improves efficiency, it creates substantial useful resource constraints in real-time functions. Present options like MoE Combination of Consultants (MoE) improve coaching effectivity by way of selective parameter activation however endure slower inference instances attributable to elevated reminiscence entry necessities. One other resolution, Product Key Reminiscence (PKM) maintains constant reminiscence entry with fewer worth embeddings however delivers subpar efficiency in comparison with MoE. MoE fashions, regardless of having 12 instances extra parameters than dense fashions, function 2 to six instances slower throughout inference.
Varied approaches have emerged to handle the computational challenges in LLMs. Researchers have centered on enhancing MoE’s gating capabilities by way of improved token alternative mechanisms and professional choice methods to fight professional imbalance. Current developments contain slicing consultants into smaller segments whereas activating a number of consultants per token. PKM represents one other strategy, implementing the smallest potential professional configuration, with subsequent enhancements together with parallel operation with MLPs and modified worth activation strategies. Lastly, tensor decomposition methods have been explored to interrupt down massive tensors into smaller elements, with product quantization enabling vector reconstruction utilizing fewer sub-vectors to cut back mannequin parameters.
A group from Seed-Basis-Mannequin at ByteDance has proposed UltraMem, a novel structure that revolutionizes the implementation of large-scale reminiscence layers in language fashions. It’s constructed upon the inspiration of PKM whereas introducing ultra-sparse reminiscence layers that dramatically enhance computational effectivity and cut back inference latency. UltraMem achieves superior efficiency in comparison with each PKM and MoE fashions at equal scales, making it significantly appropriate for resource-constrained environments. UltraMem demonstrates outstanding scaling capabilities, outperforming MoE in inference velocity by as much as 6 instances beneath widespread batch sizes, whereas sustaining computational effectivity corresponding to dense fashions.
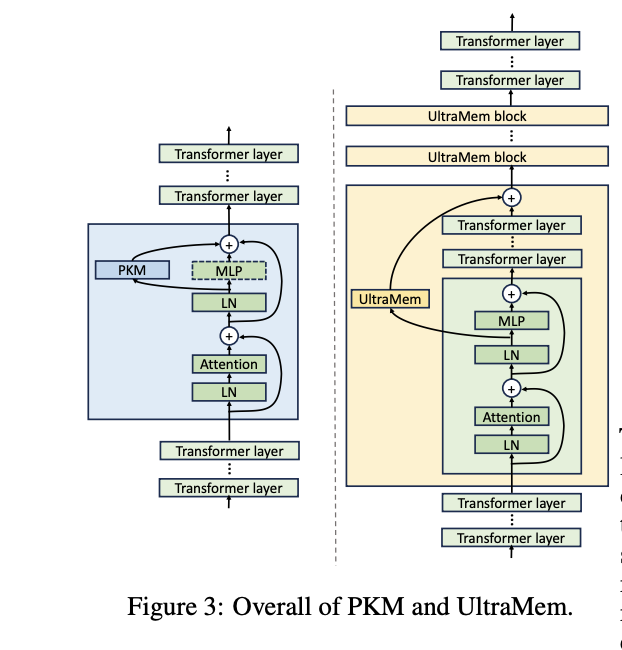
UltraMem adopts a Pre-LayerNorm Transformer structure with important modifications to handle the constraints of conventional PKM constructions. The structure distributes a number of smaller reminiscence layers at fastened intervals all through the transformer layers, changing the one massive reminiscence layer utilized in PKM. This distribution tackles the problem find right values when worth dimension will increase and the unbalanced computation throughout a number of GPUs throughout large-scale coaching. The design additionally addresses the inherent bias in product key decomposition, the place conventional top-k retrieval is constrained by row and column positions. Furthermore, the skip-layer construction optimizes the memory-bound operations throughout coaching and improves total computational effectivity.
The efficiency analysis of UltraMem throughout varied mannequin sizes reveals spectacular outcomes towards current architectures. With equal parameters and computation prices, UltraMem outperforms PKM and MoE fashions as capability will increase. UltraMem mannequin with 12 instances the parameters matches the efficiency of a 6.5B dense mannequin whereas sustaining the computational effectivity of a 1.6B dense mannequin. Scaling experiments reveal that UltraMem maintains steady inference instances even with exponential parameter progress, offered the activated parameters stay fixed. This contrasts sharply with MoE fashions, which present important efficiency degradation, highlighting UltraMem’s superior effectivity in managing sparse parameters.
This paper introduces UltraMem which represents a major development in LLM structure, exhibiting superior efficiency traits in comparison with current approaches. It achieves as much as six instances sooner processing speeds than MoE fashions whereas sustaining minimal reminiscence entry necessities. UltraMem reveals enhanced scaling capabilities as mannequin capability will increase, outperforming MoE fashions with equal parameters and computational sources. These spectacular outcomes set up UltraMem as a promising basis for growing extra environment friendly and scalable language fashions, revolutionizing the sector of NLP by enabling the creation of extra highly effective fashions whereas sustaining sensible useful resource necessities.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 75k+ ML SubReddit.

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.