Massive language fashions (LLMs) course of in depth datasets to generate coherent outputs, specializing in refining chain-of-thought (CoT) reasoning. This system allows fashions to interrupt down intricate issues into sequential steps, carefully emulating human-like logical reasoning. Producing structured reasoning responses has been a significant problem, usually requiring in depth computational assets and large-scale datasets to attain optimum efficiency. Latest efforts purpose to boost the effectivity of LLMs, guaranteeing they require much less knowledge whereas sustaining excessive reasoning accuracy.
One of many main difficulties in bettering LLM reasoning is coaching them to generate lengthy CoT responses with structured self-reflection, validation, and backtracking. Whereas current fashions have demonstrated progress, the coaching course of usually calls for costly fine-tuning on in depth datasets. Moreover, most proprietary fashions preserve their methodologies closed-source, stopping wider accessibility. The necessity for data-efficient coaching methods that protect reasoning capabilities has grown, pushing researchers to discover new strategies that optimize efficiency with out overwhelming computational prices. Understanding how LLMs can successfully purchase structured reasoning with fewer coaching samples is important for future developments.

Conventional approaches to bettering LLM reasoning depend on totally supervised fine-tuning (SFT) and parameter-efficient methods like Low-Rank Adaptation (LoRA). These methods assist fashions refine their reasoning processes with out requiring complete retraining on huge datasets. A number of fashions, together with OpenAI’s o1-preview and DeepSeek R1, have made strides in logical consistency however nonetheless require important coaching knowledge.
A analysis crew from UC Berkeley launched a novel coaching strategy designed to boost LLM reasoning with minimal knowledge. As a substitute of counting on hundreds of thousands of coaching samples, they applied a fine-tuning methodology that makes use of solely 17,000 CoT examples. The crew utilized their methodology to the Qwen2.5-32B-Instruct mannequin, leveraging each SFT and LoRA fine-tuning to attain substantial efficiency enhancements. Their strategy emphasizes optimizing the structural integrity of reasoning steps relatively than the content material itself. By refining logical consistency and minimizing pointless computational overhead, they efficiently educated LLMs to cause extra successfully whereas utilizing considerably fewer knowledge samples. The crew’s strategy additionally improves price effectivity, making it accessible for a broader vary of functions with out requiring proprietary datasets.
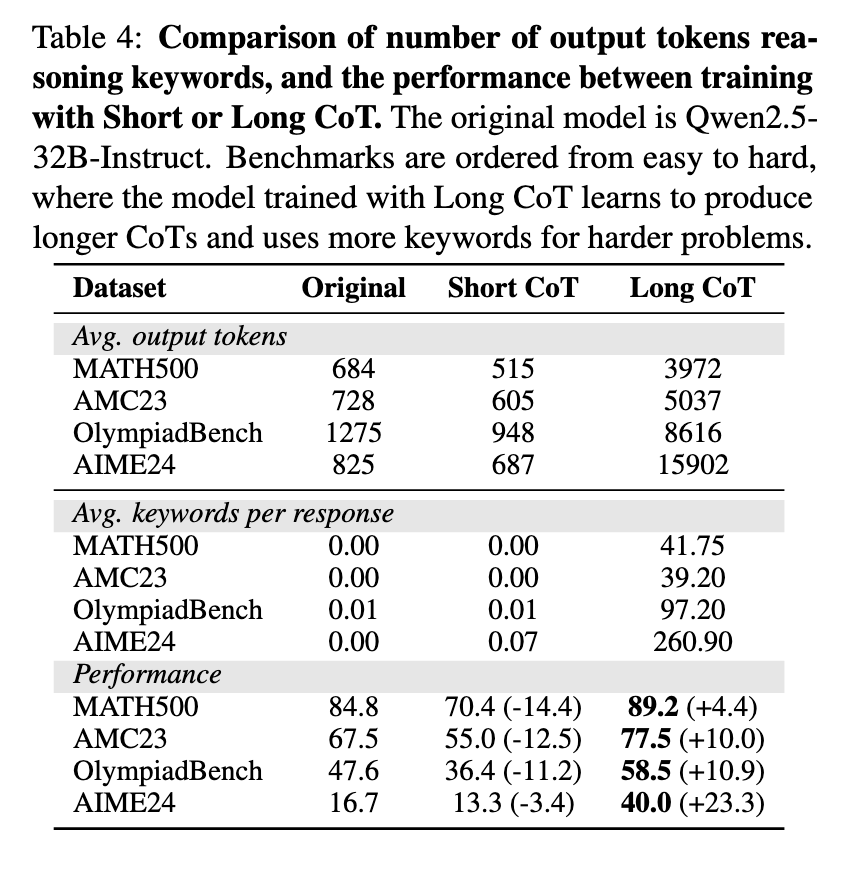
The analysis demonstrates that the construction of CoT performs an important position in enhancing LLM reasoning efficiency. Experiments revealed that altering the logical construction of coaching knowledge considerably impacted mannequin accuracy, whereas modifying particular person reasoning steps had minimal impact. The crew performed managed trials the place they randomly shuffled, deleted, or inserted reasoning steps to look at their affect on efficiency. Outcomes indicated that disrupting the logical sequence of CoT considerably degraded accuracy whereas preserving its construction and sustaining optimum reasoning capabilities. LoRA fine-tuning allowed the mannequin to replace fewer than 5% of its parameters, providing an environment friendly different to full fine-tuning whereas sustaining aggressive efficiency.
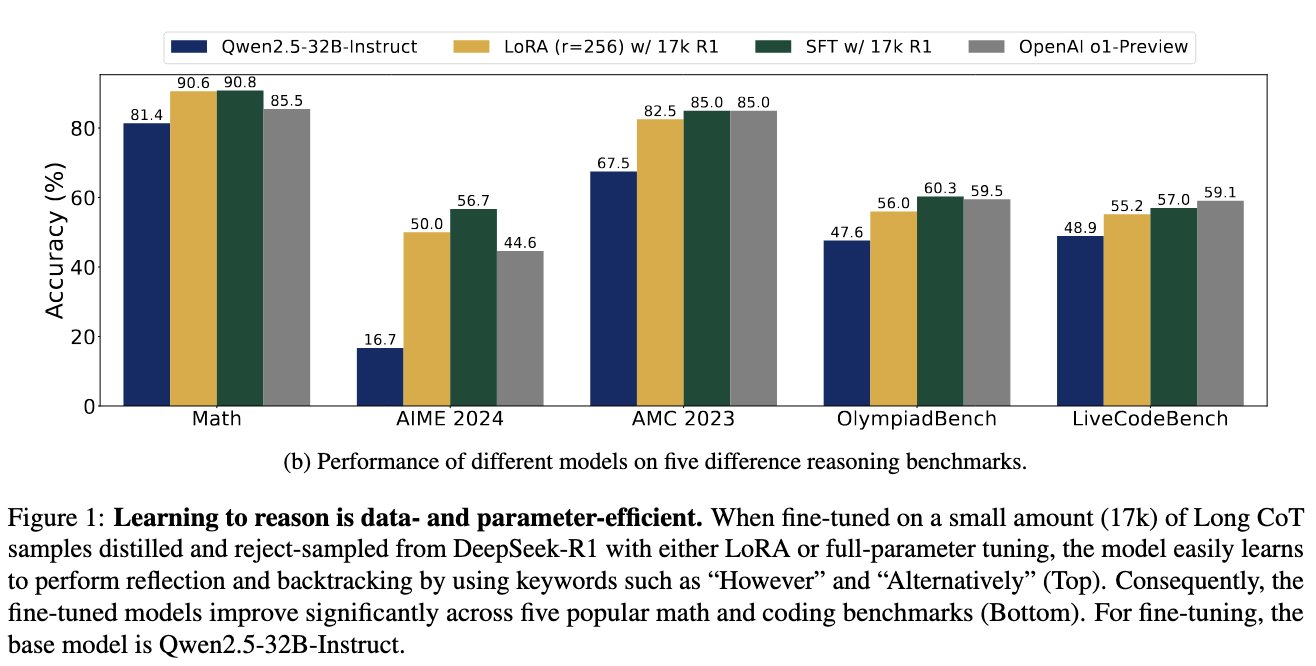
Efficiency evaluations showcased exceptional enhancements in reasoning capabilities. The Qwen2.5-32B-Instruct mannequin educated with 17,000 CoT samples achieved a 56.7% accuracy fee on AIME 2024, marking a 40.0% enchancment. The mannequin additionally scored 57.0% on LiveCodeBench, reflecting an 8.1% enhance. On Math-500, it attained 90.8%, a 6.0% rise from earlier benchmarks. Equally, it achieved 85.0% on AMC 2023 (+17.5%) and 60.3% on OlympiadBench (+12.7%). These outcomes display that environment friendly fine-tuning methods can allow LLMs to attain aggressive outcomes akin to proprietary fashions like OpenAI’s o1-preview, which scored 44.6% on AIME 2024 and 59.1% on LiveCodeBench. The findings reinforce that structured reasoning coaching permits fashions to boost efficiency with out extreme knowledge necessities.
The examine highlights a big breakthrough in bettering LLM reasoning effectivity. By shifting the main target from large-scale knowledge reliance to structural integrity, the researchers have developed a coaching methodology that ensures robust logical coherence with minimal computational assets. The strategy reduces the dependence on in depth datasets whereas sustaining strong reasoning capabilities, making LLMs extra accessible and scalable. The insights gained from this analysis pave the best way for optimizing future fashions, demonstrating that structured fine-tuning methods can successfully improve LLM reasoning with out compromising effectivity. This growth marks a step ahead in making refined AI reasoning fashions extra sensible for widespread use.
Try the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 75k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.