Entire Slide Picture (WSI) classification in digital pathology presents a number of crucial challenges as a result of immense dimension and hierarchical nature of WSIs. WSIs comprise billions of pixels and therefore direct commentary is computationally infeasible. Present methods primarily based on a number of occasion studying (MIL) are efficient in efficiency however significantly depending on massive quantities of bag-level annotated knowledge, whose acquisition is troublesome, notably within the case of uncommon illnesses. Furthermore, present methods are strongly primarily based on picture insights and encounter generalization points on account of variations within the knowledge distribution throughout hospitals. Current enhancements in Imaginative and prescient-Language Fashions (VLMs) introduce linguistic prior by means of large-scale pretraining from image-text pairs; nonetheless, present methods fall brief in addressing domain-specific insights associated to pathology. Furthermore, the computationally costly nature of pretraining fashions and their inadequate adaptability with the hierarchical attribute particular to pathology are extra setbacks. It’s important to transcend these challenges to advertise AI-based most cancers prognosis and correct WSI classification.
MIL-based strategies usually undertake a three-stage pipeline: patch cropping from WSIs, function extraction with a pre-trained encoder, and patch-level to slide-level function aggregation to make predictions. Though these strategies are efficient for pathology-related duties like most cancers subtyping and staging, their dependency on massive annotated datasets and knowledge distribution shift sensitivity renders them much less sensible to make use of. VLM-based fashions like CLIP and BiomedCLIP attempt to faucet into language priors by using large-scale image-text pairs gathered from on-line databases. These fashions, nonetheless, depend upon basic, handcrafted textual content prompts that lack the subtlety of pathological prognosis. As well as, information switch from vision-language fashions to WSIs is inefficient owing to the hierarchical and large-scale nature of WSIs, which calls for astronomical computational prices and dataset-specific fine-tuning.
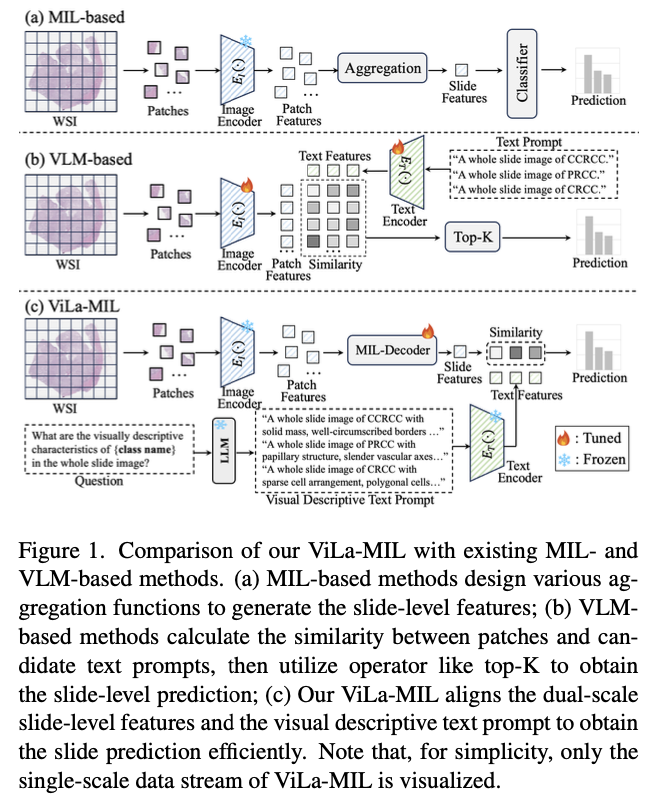
Researchers from Xi’an Jiaotong College, Tencent YouTu Lab, and Institute of Excessive-Efficiency Computing Singapore introduce a dual-scale vision-language a number of occasion studying mannequin able to effectively transferring vision-language mannequin information to digital pathology by means of descriptive textual content prompts designed particularly for pathology and trainable decoders for picture and textual content branches. In distinction to generic class-name-based prompts for conventional vision-language strategies, the mannequin makes use of a frozen massive language mannequin to generate domain-specific descriptions at two resolutions. The low-scale immediate highlights world tumor buildings, and the high-scale immediate highlights finer mobile particulars, with improved function discrimination. A prototype-guided patch decoder progressively accumulates patch options by clustering comparable patches into learnable prototype vectors, minimizing computational complexity and enhancing function illustration. A context-guided textual content decoder additional improves textual content descriptions by utilizing multi-granular picture context, facilitating a simpler fusion of visible and textual modalities.
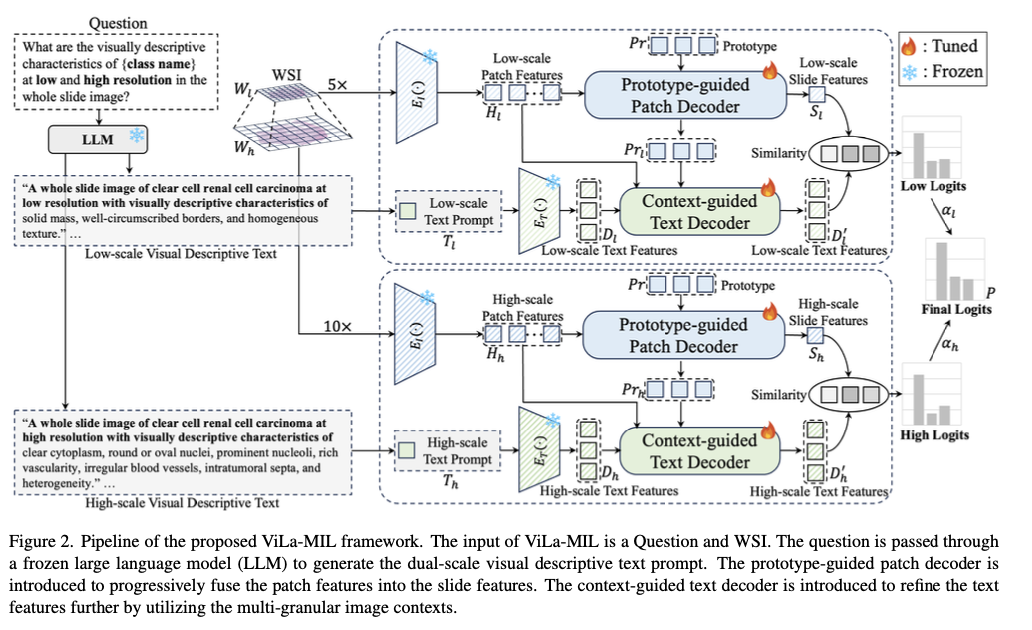
The mannequin proposed depends on CLIP as its underlying mannequin and makes use of a number of additions to adapt it for pathology duties. Entire-slide pictures are patchily segmented on the 5× and 10× magnification ranges, whereas function extraction makes use of a frozen ResNet-50 picture encoder. A frozen massive GPT-3.5 language mannequin can be used to generate class-specific descriptive prompts for 2 scales with learnable vectors to facilitate efficient function illustration. Progressive function agglomeration is supported utilizing a set of 16 learnable prototype vectors. The patch and prototype multi-granular options additionally assist help the textual content embeddings, therefore improved cross-modal alignment. Optimizing coaching makes use of the cross-entropy loss with equally weighted low- and high-scale similarity scores for sturdy classification help.
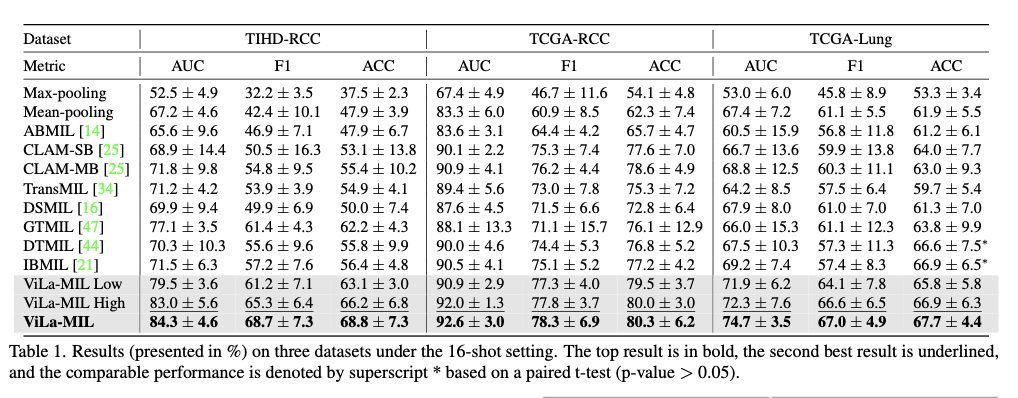
This technique demonstrates higher efficiency on numerous subtyping datasets of most cancers considerably outperforming present MIL-based and VLM-based strategies in few-shot studying eventualities. The mannequin information spectacular good points in AUC, F1 rating, and accuracy over three numerous datasets—TIHD-RCC, TCGA-RCC, and TCGA-Lung—demonstrating the mannequin’s solidity in exams executed in each single-center and multi-center setups. Compared to state-of-the-art approaches, important good points in classification accuracy are noticed with rises of 1.7% to 7.2% in AUC and a pair of.1% to 7.3% in F1 rating. The employment of dual-scale textual content prompts with a prototype-guided patch decoder and context-guided textual content decoder aids the framework in its means to study efficient discriminative morphological patterns regardless of the presence of few coaching cases. Furthermore, wonderful generalization skills throughout a number of datasets counsel enhanced adaptability towards area shift throughout cross-center testing. These observations exhibit the deserves of fusing vision-language fashions with pathology-specialized advances towards complete slide picture classification.
By the event of a brand new dual-scale vision-language studying framework, this analysis makes a considerable contribution to WSI classification with the utilization of enormous language fashions to immediate textual content and prototype-based function aggregation. The strategy enhances few-shot generalization, decreases computational value, and promotes interpretability, fixing core pathology AI challenges. By constructing on the profitable vision-language mannequin switch to digital pathology, this analysis is a useful contribution to most cancers prognosis with AI, with the potential to generalize to different medical picture duties.
Check out the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 75k+ ML SubReddit.
🚨 Really helpful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Tackle Authorized Considerations in AI Datasets
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.
