Bettering how giant language fashions (LLMs) deal with advanced reasoning duties whereas preserving computational prices low is a problem. Producing a number of reasoning steps and choosing the right reply will increase accuracy, however this course of calls for a number of reminiscence and computing energy. Coping with lengthy reasoning chains or large batches is computationally costly and slows down fashions, rendering them inefficient underneath bounded computational sources. Different fashions of various architectures have sooner data processing and fewer reminiscence, however their efficiency functionality in reasoning duties is unknown. Understanding whether or not these fashions can match or exceed present ones underneath restricted sources is necessary for making LLMs extra environment friendly.
At the moment, strategies to enhance reasoning in giant language fashions depend on producing a number of reasoning steps and choosing the right reply utilizing strategies like majority voting and skilled reward fashions. The strategies enhance accuracy ranges, though they want giant computation methods, which makes them ill-suited for large knowledge processing. The processing energy necessities and the reminiscence wants of Transformer fashions decelerate inference operations. Recurrent fashions and linear consideration strategies work sooner in processing however lack effectiveness in reasoning operations. Information distillation helps switch data from giant to smaller fashions, however whether or not robust reasoning skills switch throughout completely different mannequin varieties is unclear.
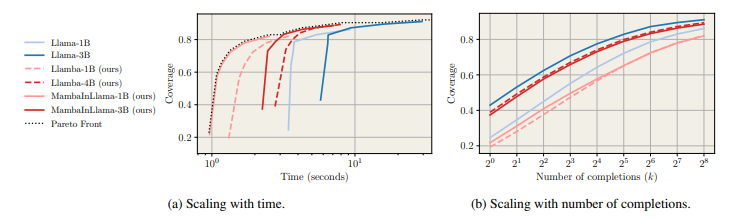
To mitigate these points, researchers from College of Geneva, Collectively AI, Cornell College, EPFL, Carnegie Mellon College, Cartesia.ai, META and Princeton College proposed a distillation methodology to create subquadratic fashions with robust reasoning expertise, bettering effectivity whereas preserving reasoning capabilities. The distilled fashions outperformed their Transformer lecturers on MATH and GSM8K duties, attaining comparable accuracy with 2.5× decrease inference time. This demonstrated that reasoning and mathematical expertise may switch throughout architectures whereas lowering computational prices.
The framework included two mannequin varieties: pure Mamba fashions (Llamba) and hybrid fashions (MambaInLlama). Llamba used the MOHAWK distillation methodology, aligning matrices, matching hidden states, and transferring weights whereas coaching on an 8B-token dataset. MambaInLlama retained Transformer consideration layers however changed others with Mamba layers, utilizing reverse KL divergence for distillation. Experiments demonstrated dataset alternative had a big impact on efficiency, with sure datasets decreasing Llamba-1B accuracy by 10% and displaying a poor correlation between normal benchmarks and mathematical reasoning, emphasizing the significance of improved coaching knowledge.
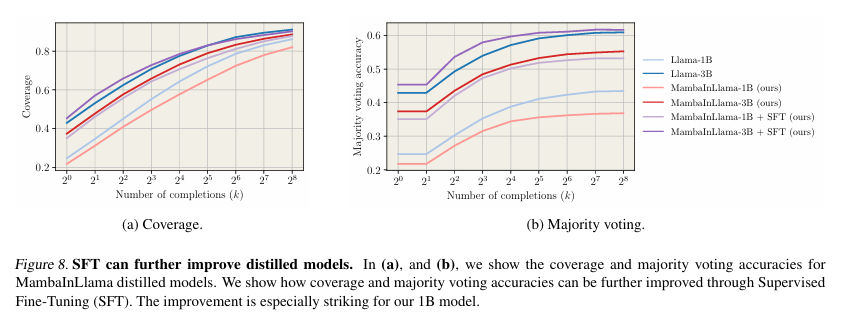
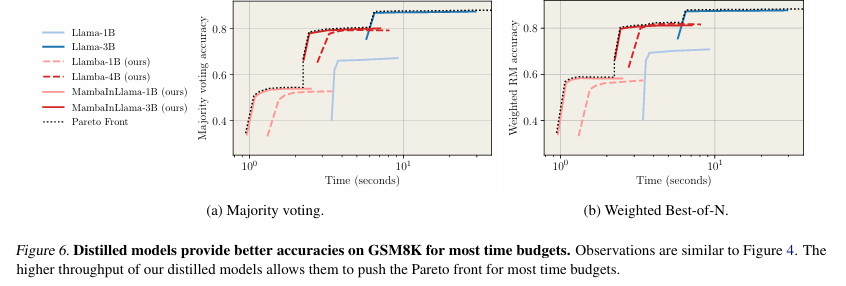
Researchers evaluated distilled fashions for producing a number of chains of thought (CoTs) in math problem-solving, specializing in instruction-following retention. They measured protection utilizing move@okay, estimated the likelihood of discovering an accurate answer amongst okay samples, and assessed accuracy via majority voting and Finest-of-N choice with a Llama-3.1 8B-primarily based reward mannequin. Benchmarks confirmed distilled fashions carried out as much as 4.2× sooner than Llama fashions whereas sustaining comparable protection, producing extra completions inside fastened compute budgets, and outperforming smaller transformer baselines in pace and accuracy. Moreover, supervised fine-tuning (SFT) after distillation enhanced efficiency, validating their effectiveness in structured reasoning duties equivalent to coding and formal proofs.
In abstract, the proposed Distilled Mamba fashions enhanced reasoning effectivity by retaining accuracy whereas chopping inference time and reminiscence consumption. When computational budgets have been fastened, the fashions outperformed Transformers; therefore, they’re appropriate for scalable inference. This methodology can function a foundation for future analysis in coaching good reasoning fashions, bettering distillation strategies, and constructing reward fashions. Inference scaling developments would additional improve their utility in AI methods that demand sooner and more practical reasoning.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 80k+ ML SubReddit.
🚨 Really helpful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Deal with Authorized Issues in AI Datasets
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and clear up challenges.