The o1 mannequin’s spectacular efficiency in advanced reasoning highlights the potential of test-time computing scaling, which reinforces System-2 considering by allocating higher computational effort throughout inference. Whereas deep studying’s scaling results have pushed developments in AI, notably in LLMs like GPT, additional scaling throughout coaching faces limitations because of knowledge shortage and computational constraints. Moreover, present fashions typically fail in robustness and dealing with intricate duties, primarily counting on quick, intuitive System-1 considering. The o1 mannequin, launched by OpenAI in 2024, incorporates System-2 considering, enabling superior efficiency in advanced reasoning duties by way of test-time computing scaling. This method demonstrates that rising computational effort throughout inference improves mannequin accuracy, addressing a number of the limitations of conventional training-phase scaling.
System-1 and System-2 considering, derived from cognitive psychology, are utilized in AI to explain completely different processing methods. System-1 fashions depend on sample recognition and quick, intuitive responses, missing robustness and flexibility to distribution shifts. Earlier efforts to reinforce robustness, equivalent to test-time adaptation (TTA), centered on parameter updates or exterior enter changes. Nonetheless, these fashions have been restricted to weak System-2 capabilities. With the rise of LLMs, System-2 fashions have gained traction, permitting for incremental reasoning and the era of intermediate steps, as seen in Chain-of-Thought (CoT) prompting. Whereas this method improves reasoning in comparison with direct output strategies, it stays liable to cumulative errors. Retrieval-augmented era (RAG) partially addresses factual inaccuracies, however its impression on reasoning talents is proscribed, leaving CoT-enabled fashions at an early stage of System-2 considering.
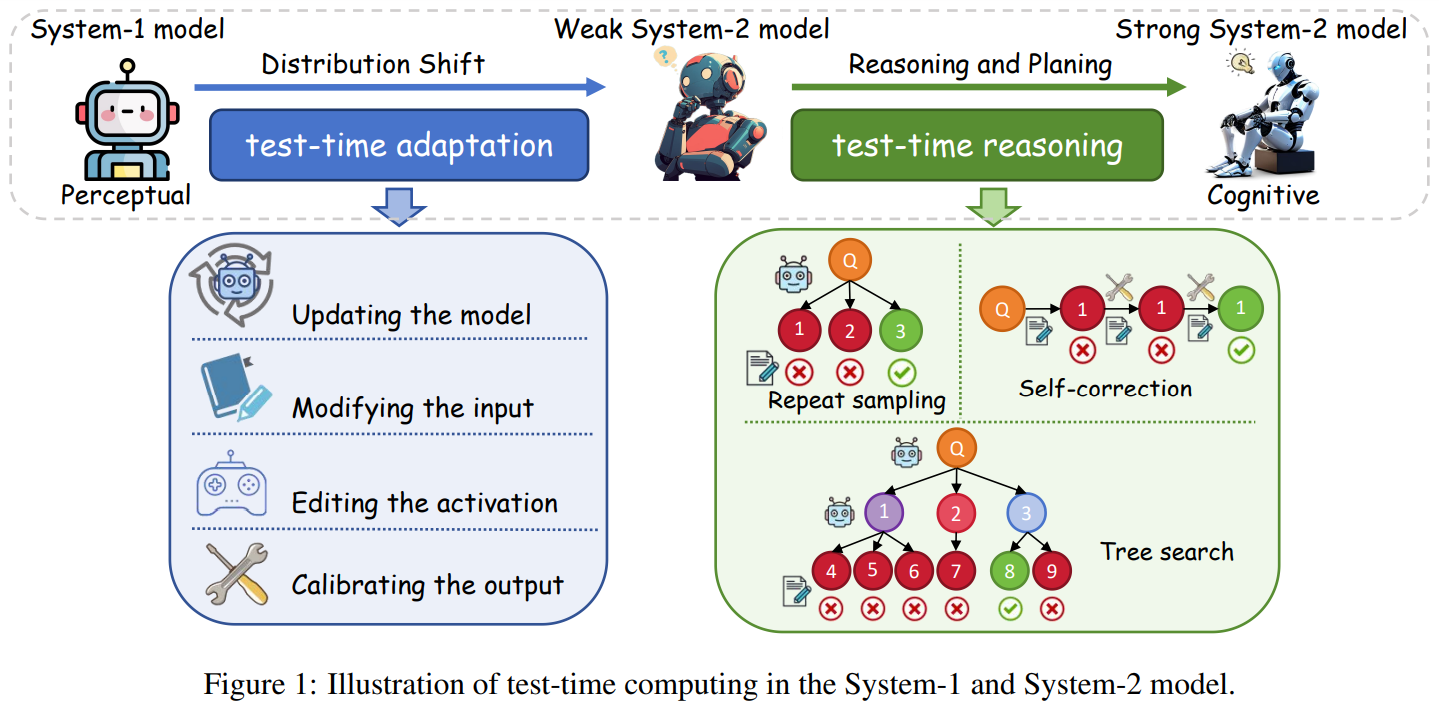
Researchers from Soochow College, the Nationwide College of Singapore, and Ant Group explored test-time computing, tracing its evolution from System-1 to System-2 fashions. Initially utilized to System-1 fashions to deal with distribution shifts and improve robustness by way of parameter updates, enter modifications, and output calibration, test-time computing now strengthens reasoning in System-2 fashions utilizing methods like repeated sampling, self-correction, and tree search. These strategies allow fashions to resolve advanced issues by simulating numerous considering patterns, reflecting on errors, and enhancing reasoning depth. The survey highlights this development and additional discusses future analysis instructions for growing strong, cognitively succesful AI methods.
TTA fine-tunes fashions throughout inference utilizing check pattern info. Key concerns embody studying alerts, parameter updates, and guaranteeing effectivity. Studying alerts like Check-time Coaching (TTT) use auxiliary duties, whereas Totally Check-time Adaptation (FTTA) leverages inner suggestions (e.g., entropy minimization) however requires safeguards towards mannequin collapse. Human suggestions can be utilized for duties like QA and cross-modal retrieval. To enhance effectivity, parameter updates goal particular layers (e.g., normalization or adapters). Strategies equivalent to episodic TTA or exponential shifting averages tackle catastrophic forgetting. Strategies like FOA additional refine adaptation by optimizing prompts with out backpropagation.
Check-time reasoning entails leveraging prolonged inference time to establish human-like reasoning throughout the decoding search house. Its two core elements are suggestions modeling and search methods. Suggestions modeling evaluates outputs by way of score-based and verbal suggestions. Rating-based suggestions makes use of verifiers to attain outputs primarily based on correctness or reasoning course of high quality, with outcome-based and process-based approaches. Verbal suggestions offers interpretability and correction options through pure language critiques, typically using LLMs like GPT-4. Search methods embody repeated sampling and self-correction, the place numerous responses are generated and refined. Multi-agent debates and self-critiques improve reasoning by leveraging exterior suggestions or intrinsic analysis mechanisms.
In conclusion, The way forward for test-time computing entails a number of key instructions. First, enhancing the generalization of System-2 fashions past domain-specific duties like math and code to help scientific discovery and weak-to-strong generalization is significant. Second, increasing multimodal reasoning by integrating modalities like speech and video and aligning processes with human cognition holds promise. Third, balancing effectivity and efficiency by optimizing useful resource allocation and integrating acceleration methods is important. Fourth, establishing common scaling legal guidelines stays difficult because of numerous methods and influencing components. Lastly, combining a number of test-time methods and adaptation strategies can enhance reasoning, advancing LLMs towards cognitive intelligence.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.