Multimodal Giant Language Fashions (MLLMs) have gained important consideration for his or her means to deal with complicated duties involving imaginative and prescient, language, and audio integration. Nonetheless, they lack the great alignment past fundamental Supervised Effective-tuning (SFT). Present state-of-the-art fashions usually bypass rigorous alignment phases, leaving essential features like truthfulness, security, and human choice alignment inadequately addressed. Present approaches goal solely particular domains reminiscent of hallucination discount or conversational enhancements, falling in need of enhancing the mannequin’s general efficiency and reliability. This slender focus raises questions on whether or not human choice alignment can enhance MLLMs throughout a broader spectrum of duties.
Latest years have witnessed substantial progress in MLLMs, constructed upon superior LLM architectures like GPTs, LLaMA, Alpaca, Vicuna, and Mistral. These fashions have developed via end-to-end coaching approaches, tackling complicated multimodal duties involving image-text alignment, reasoning, and instruction following. A number of open-source MLLMs, together with Otter, mPLUG-Owl, LLaVA, Qwen-VL, and VITA, have emerged to deal with elementary multimodal challenges. Nonetheless, alignment efforts have remained restricted. Whereas algorithms like Truth-RLHF and LLAVACRITIC have proven promise in decreasing hallucinations and enhancing conversational talents, they haven’t enhanced normal capabilities. Analysis frameworks reminiscent of MME, MMBench, and Seed-Bench have been developed to evaluate these fashions.
Researchers from KuaiShou, CASIA, NJU, USTC, PKU, Alibaba, and Meta AI have proposed MM-RLHF, an revolutionary method that includes a complete dataset of 120k fine-grained, human-annotated choice comparability pairs. This dataset represents a major development by way of measurement, variety, and annotation high quality in comparison with current sources. The tactic introduces two key improvements: a Critique-Based mostly Reward Mannequin that generates detailed critiques earlier than scoring outputs, and Dynamic Reward Scaling that optimizes pattern weights primarily based on reward alerts. It enhances each the interpretability of mannequin selections and the effectivity of the alignment course of, addressing the restrictions of conventional scalar reward mechanisms in multimodal contexts.
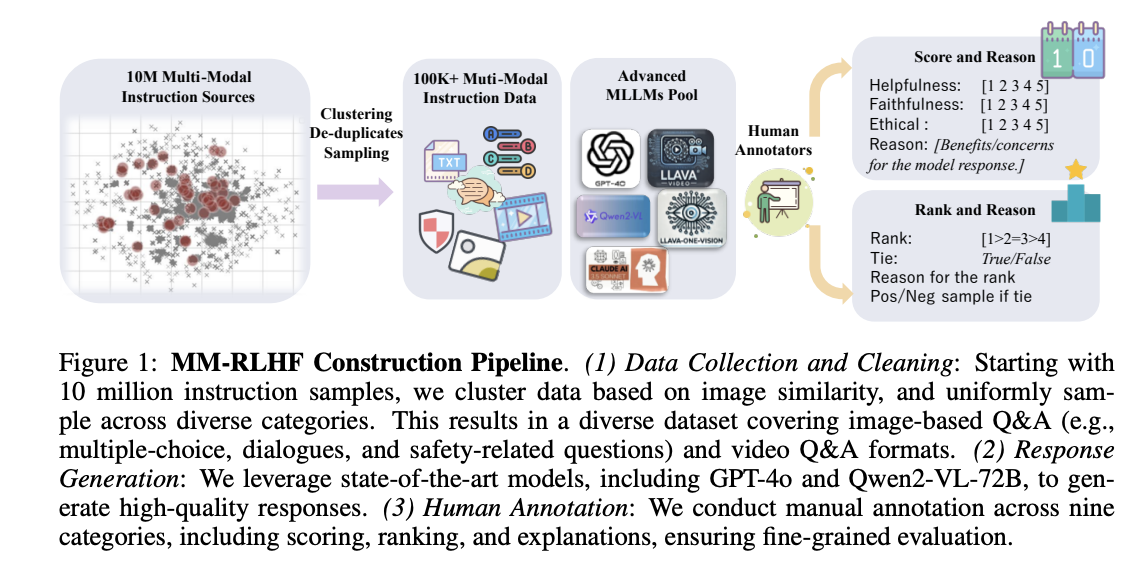
The MM-RLHF implementation entails a fancy information preparation and filtering course of throughout three important domains: picture understanding, video understanding, and multimodal security. The picture understanding part integrates information from a number of sources together with LLaVA-OV, VLfeedback, and LLaVA-RLHF, with multi-turn dialogues transformed to single-turn format. This compilation ends in over 10 million dialogue samples overlaying various duties from fundamental dialog to complicated reasoning. The information filtering course of makes use of predefined sampling weights categorized into three sorts: multiple-choice questions for testing reasoning and notion, long-text questions for evaluating conversational talents, and short-text questions for fundamental picture evaluation.
The analysis of MM-RLHF and MM-DPO reveals important enhancements throughout a number of dimensions when utilized to fashions like LLaVA-OV-7B, LLaVA-OV-0.5B, and InternVL-1B. Conversational talents improved by over 10%, whereas unsafe behaviors decreased by at the least 50%. The aligned fashions present higher ends in hallucination discount, mathematical reasoning, and multi-image understanding, even with out particular coaching information for some duties. Nonetheless, model-specific variations are noticed, with completely different fashions requiring distinct hyperparameter settings for optimum efficiency. Additionally, high-resolution duties present restricted features attributable to dataset constraints and filtering methods that don’t goal decision optimization.
On this paper, researchers launched MM-RLHF, a dataset and alignment method that reveals important development in MLLM improvement. Not like earlier task-specific approaches, this methodology takes a holistic method to enhance mannequin efficiency throughout a number of dimensions. The dataset’s wealthy annotation granularity, together with per-dimension scores and rating rationales, affords untapped potential for future improvement. Future analysis instructions will give attention to using this granularity via superior optimization strategies, addressing high-resolution information limitations, and increasing the dataset via semi-automated strategies, probably establishing a basis for extra strong multimodal studying frameworks.
Check out the Paper and Project Page. All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 75k+ ML SubReddit.
🚨 Beneficial Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Tackle Authorized Issues in AI Datasets

Sajjad Ansari is a remaining 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.
