LLMs have revolutionized software program growth by automating coding duties and bridging the pure language and programming hole. Whereas extremely efficient for general-purpose programming, they battle with specialised domains like Excessive-Efficiency Computing (HPC), significantly in producing parallel code. This limitation arises from the shortage of high-quality parallel code information in pre-training datasets and the inherent complexity of parallel programming. Addressing these challenges is essential, as creating HPC-specific LLMs can considerably improve developer productiveness and speed up scientific discoveries. To beat these hurdles, researchers emphasize the necessity for curated datasets with better-quality parallel code and improved coaching methodologies that transcend merely growing information quantity.
Efforts to adapt LLMs for HPC have included fine-tuning specialised fashions equivalent to HPC-Coder and OMPGPT. Whereas these fashions display promise, many depend on outdated architectures or slender purposes, limiting their effectiveness. Latest developments like HPC-Coder-V2 leverage state-of-the-art methods to enhance efficiency, attaining comparable or superior outcomes to bigger fashions whereas sustaining effectivity. Research spotlight the significance of information high quality over amount and advocate for focused approaches to boost parallel code era. Future analysis goals to develop sturdy HPC-specific LLMs that bridge the hole between serial and parallel programming capabilities by integrating insights from artificial information era and specializing in high-quality datasets.
Researchers from the College of Maryland performed an in depth examine to fine-tune a specialised HPC LLM for parallel code era. They developed an artificial dataset, HPC-INSTRUCT, containing high-quality instruction-answer pairs derived from parallel code samples. Utilizing this dataset, they fine-tuned HPC-Coder-V2, which emerged as the very best open-source code LLM for parallel code era, performing close to GPT-4 ranges. Their examine explored how information illustration, coaching parameters, and mannequin dimension affect efficiency, addressing key questions on information high quality, fine-tuning methods, and scalability to information future developments in HPC-specific LLMs.
Enhancing Code LLMs for parallel programming includes creating HPC-INSTRUCT, a big artificial dataset of 120k instruction-response pairs derived from open-source parallel code snippets and LLM outputs. This dataset consists of programming, translation, optimization, and parallelization duties throughout languages like C, Fortran, and CUDA. We fine-tune three pre-trained Code LLMs—1.3B, 6.7B, and 16B parameter fashions—on HPC-INSTRUCT and different datasets utilizing the AxoNN framework. By way of ablation research, we study the influence of information high quality, mannequin dimension, and immediate formatting on efficiency, optimizing the fashions for the ParEval benchmark to evaluate their means to generate parallel code successfully.
To guage Code LLMs for parallel code era, the ParEval benchmark was used, that includes 420 various issues throughout 12 classes and 7 execution fashions like MPI, CUDA, and Kokkos. Efficiency was assessed utilizing the cross@ok metric, which measures the likelihood of producing at the very least one appropriate resolution inside ok makes an attempt. Ablation research analyzed the influence of base fashions, instruction masking, information high quality, and mannequin dimension. Outcomes revealed that fine-tuning base fashions yielded higher efficiency than instruct variants, high-quality information improved outcomes, and bigger fashions confirmed diminishing returns, with a notable acquire from 1.3B to six.7B parameters.
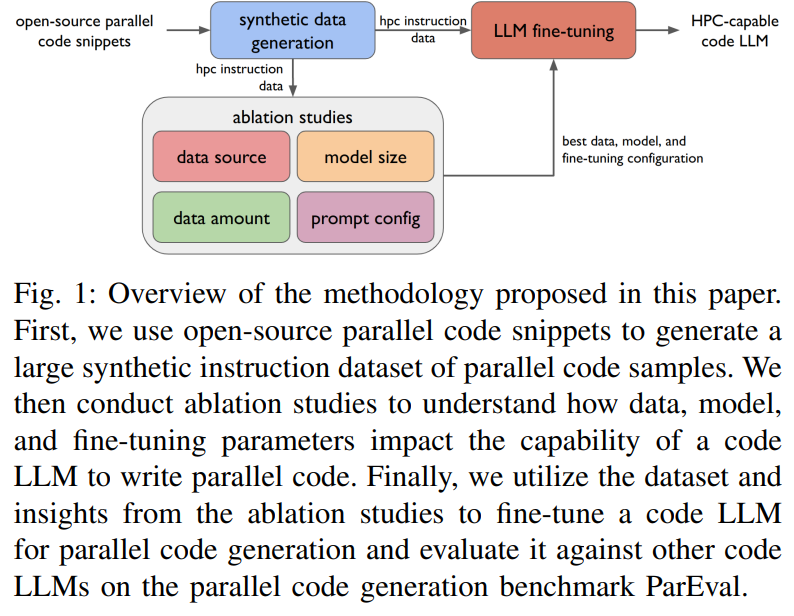
In conclusion, the examine presents HPC-INSTRUCT, an HPC instruction dataset created utilizing artificial information from LLMs and open-source parallel code. An in-depth evaluation was performed throughout information, mannequin, and immediate configurations to determine components influencing code LLM efficiency in producing parallel code. Key findings embody the minimal influence of instruction masking, the benefit of fine-tuning base fashions over instruction-tuned variants, and diminishing returns from elevated coaching information or mannequin dimension. Utilizing these insights, three state-of-the-art HPC-specific LLMs—HPC-Coder-V2 fashions—have been fine-tuned, attaining superior efficiency on the ParEval benchmark. These fashions are environment friendly, outperforming others in parallel code era for high-performance computing.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.