Retrieval Augmented Technology is an environment friendly resolution for knowledge-intensive duties that improves the standard of outputs and makes it extra deterministic with minimal hallucinations. Nonetheless, RAG outputs can nonetheless be noisy and should fail to reply appropriately to advanced queries. To deal with this limitation, iterative retrieval updates have been launched, which replace re-retrieval outcomes to fulfill dynamic info wants. Primarily launched to deal with the problem of data sparsity and necessities throughout advanced question options, it focuses on two W’s – When and What (to retrieve). Regardless of its potential, most current strategies rely closely on human-oriented guidelines and prompts. This dependence calls for important human effort and limits LLMs’ decision-making capabilities, successfully spoon-feeding them as an alternative of enabling autonomy.
To beat these challenges, researchers from the Chinese language Academy of Sciences have proposed Auto-RAG, an autonomous iterative retrieval-augmented system that prioritizes LLM decision-making capabilities. It features a multi-turn dialogue between LLM and the retriever. In distinction to standard outcomes, AutoRag makes use of the reasoning talents of LLMs for planning, information extraction, question rewriting, and iteratively querying the retriever till the specified resolution is offered to the person.Auto-RAG introduces a framework for the automated synthesis of reasoning-based directions, enabling LLMs to make choices independently inside the iterative RAG course of. These directions enable the automation of LLM decision-making in an iterative RAG course of at a minimal value.
The authors conceptualized the iterative course of as a multi-turn interplay between LLM and retriever till the retriever is assured of knowledge sufficiency. After every iteration, the mannequin causes again and adjusts the retrieval method to hunt the suitable info. The central a part of this pipeline is undeniably the reasoning half. The authors add three totally different reasoning factors constituting a Chain of Thought for retrieval.
- Retrieval Planning: This is step one, specializing in major knowledge retrieval pertinent to the question. This part additionally consists of assessing if the mannequin wants extra retrievals or if the acquired info is enough.
- Info Extraction: The second step makes the data extra query-specific. On this step, LLM extracts related info from the retrieved doc for ultimate reply curation. It features a summarization technique of significant info to mitigate inaccuracies.
- Reply Inference: The pipeline’s ultimate step consists of LLM to formulate the ultimate choice primarily based on the extracted info.
Moreover, AutoRag is extremely dynamic as a result of it mechanically adjusts the variety of iterations relying on the complexity of the question, saving one the trouble of computations. One other upside to this framework is that it’s user-friendly and written in pure language, which offers a excessive diploma of interpretability. Now that we now have mentioned what Auto-Rag does and why it is important to bettering mannequin efficiency, allow us to have a look at how this pipeline carried out on precise assessments.
The analysis workforce fine-tune LLMs below a supervised setting to make retrieval autonomous. They synthesized 10,000 reasoning-based directions for this case derived from two datasets-Pure Questions and 2WikiMultihopQA. The fashions used on this pipeline had been Llama-3-8B-Instruct (for reasoning synthesis ) and Qwen1.5-32B-Chat( for rewritten queries). The info was fine-tuned on the Llama Mannequin for its human-free retrieval effectivity.
To check the efficacy of the proposed technique, authors benchmarked the Auto Rag framework on six consultant benchmarks with open area and multi-hop answering Datasets. Multi-Hop QA had numerous subparts and a number of queries, making making use of normal RAG strategies inefficient. The outcomes validated AutoRag’s claims with wonderful ends in data-constrained coaching. A zero-shot prompting technique was chosen because the baseline for RAG with out the pipeline. The authors additionally in contrast Auto Rag with some multi-chain engagement and CoT-based strategies, the place Auto Rag surpassed the opposite fashions.
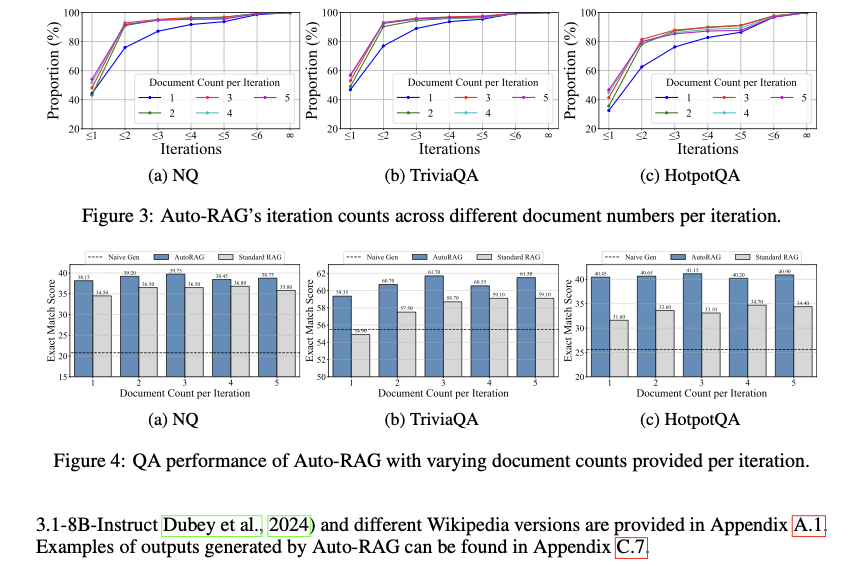
Conclusion: Auto Rag achieved superior efficiency on six benchmarks by automating the multi-step retrieval course of activity with enhanced reasoning in standard RAG setups. Not solely did it ship higher outcomes, but it surely additionally self-adjusted the queries within the retrieval course of to work solely till you get the data.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our newsletter.. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Adeeba Alam Ansari is presently pursuing her Twin Diploma on the Indian Institute of Expertise (IIT) Kharagpur, incomes a B.Tech in Industrial Engineering and an M.Tech in Monetary Engineering. With a eager curiosity in machine studying and synthetic intelligence, she is an avid reader and an inquisitive particular person. Adeeba firmly believes within the energy of know-how to empower society and promote welfare by progressive options pushed by empathy and a deep understanding of real-world challenges.