Regardless of their superior reasoning capabilities, the most recent LLMs usually miss the mark when deciphering relationships. On this article, we discover the Reversal Curse, a pitfall that impacts LLMs throughout duties akin to comprehension and era. To grasp the underlying problem, it’s a phenomenon that happens when coping with two entities, denoted as a and b, linked by their relation R and its inverse. LLMs excel at dealing with sequences akin to “aRb” however battle with “b R inverse a.” Whereas LLMs can rapidly reply questions like “Who’s the mom of Tom Cruise?” when requested, they’re extra more likely to hallucinate and falter when requested, “Who’s Mary Lee Pfeiffer’s son?” This appears simple, on condition that the mannequin already is aware of the connection between Tom Cruise and Mary Lee Pfeiffer.
Researchers from the Renmin College of China have offered the reversal curse of LLMs to the analysis neighborhood, shedding gentle on its possible causes and suggesting potential mitigation methods. They establish the Coaching Goal Perform as one of many key elements influencing the extent of the reversal curse.
To completely grasp the reversal curse, we should first perceive the coaching strategy of LLMs. Subsequent-token prediction (NTP) is the dominant pre-training goal for present massive language fashions, akin to GPT and Llama. In fashions like GPT and Llama, consideration masks throughout coaching rely upon the previous tokens, which means every token focuses solely on its prior context, making it inconceivable to account for subsequent tokens. In consequence, if a happens earlier than b within the coaching corpus, the mannequin maximizes the likelihood of b given over the chance of a given b. Due to this fact, there isn’t a assure that LLMs can present a excessive likelihood for a when offered with b. In distinction, GLM fashions are pre-trained with autoregressive clean in-filling goals, the place the masked token controls each previous and succeeding tokens, making them extra sturdy to the reversal curse. The authors argue that this distinction in sequence coaching is the basis reason for LLMs’ underperformance with inverse relations.
To check this speculation, the authors fine-tuned GLMs on “Title to Description” information, utilizing fictitious names and feeding descriptions to retrieve details about the entities.
The GLMs achieved roughly 80% accuracy on this process, whereas Llama’s accuracy was 0%.
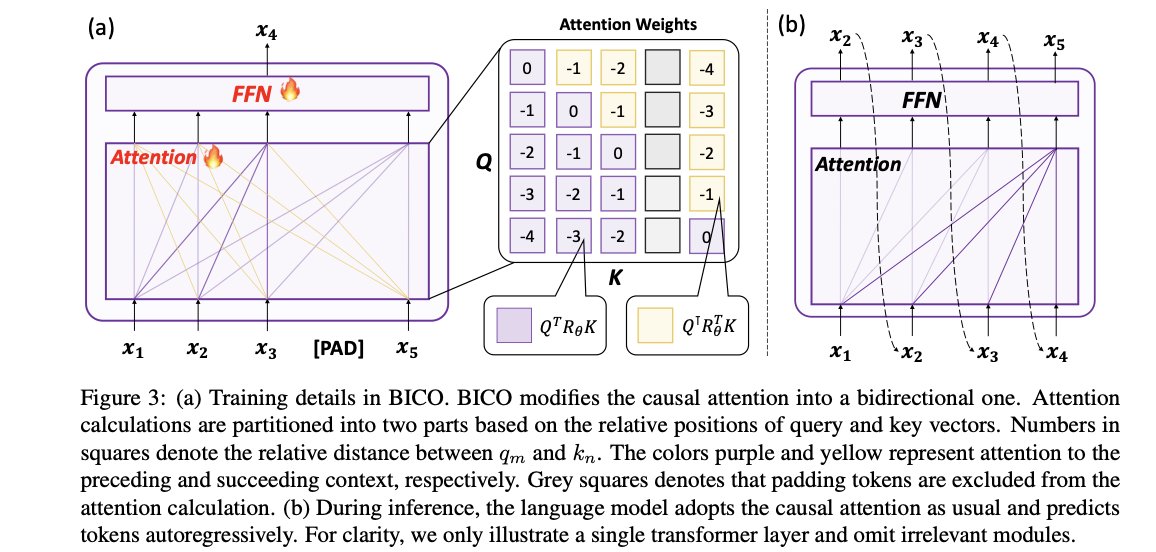
To handle this problem, the authors suggest a technique that adapts the coaching goal of LLMs to one thing just like ABI. They fine-tuned fashions utilizing Bidirectional Causal Language Mannequin Optimization (BICO) to reverse-engineer mathematical duties and translation issues. BICO adopts an autoregressive clean infilling goal, just like GLM, however with tailor-made modifications designed explicitly for causal language fashions. The authors launched rotary (relative) place embeddings and modified the eye operate to make it bidirectional. This fine-tuning methodology improved the mannequin’s accuracy in reverse translation and mathematical problem-solving duties.
In conclusion, the authors analyze the reversal curse and suggest a fine-tuning technique to mitigate this pitfall. By adopting a causal language mannequin with an ABI-like goal, this research sheds gentle on the reversal underperformance of LLMs. This work could possibly be additional expanded to look at the impression of superior strategies, akin to RLHF, on the reversal curse.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
Adeeba Alam Ansari is presently pursuing her Twin Diploma on the Indian Institute of Know-how (IIT) Kharagpur, incomes a B.Tech in Industrial Engineering and an M.Tech in Monetary Engineering. With a eager curiosity in machine studying and synthetic intelligence, she is an avid reader and an inquisitive particular person. Adeeba firmly believes within the energy of expertise to empower society and promote welfare by way of modern options pushed by empathy and a deep understanding of real-world challenges.