The Rising Function of AI in Biomedical Analysis
The sector of biomedical synthetic intelligence is evolving quickly, with rising demand for brokers able to performing duties that span genomics, medical diagnostics, and molecular biology. These brokers aren’t merely designed to retrieve details; they’re anticipated to motive by complicated organic issues, interpret affected person knowledge, and extract significant insights from huge biomedical databases. In contrast to general-purpose AI fashions, biomedical brokers should interface with domain-specific instruments, comprehend organic hierarchies, and simulate workflows just like these of researchers to successfully help trendy biomedical analysis.
The Core Problem: Matching Skilled-Degree Reasoning
Nevertheless, attaining expert-level efficiency in these duties is much from trivial. Most massive language fashions fall brief when coping with the nuance and depth of biomedical reasoning. They could succeed on surface-level retrieval or sample recognition duties, however usually fail when challenged with multi-step reasoning, uncommon illness analysis, or gene prioritization, areas that require not simply knowledge entry, however contextual understanding and domain-specific judgment. This limitation has created a transparent hole: find out how to practice biomedical AI brokers that may suppose and act like area consultants.
Why Conventional Approaches Fall Quick
Whereas some options leverage supervised studying on curated biomedical datasets or retrieval-augmented era to floor responses in literature or databases, these approaches have drawbacks. They usually depend on static prompts and pre-defined behaviors that lack adaptability. Moreover, many of those brokers wrestle to successfully execute exterior instruments, and their reasoning chains collapse when confronted with unfamiliar biomedical buildings. This fragility makes them ill-suited for dynamic or high-stakes environments, the place interpretability and accuracy are non-negotiable.
Biomni-R0: A New Paradigm Utilizing Reinforcement Studying
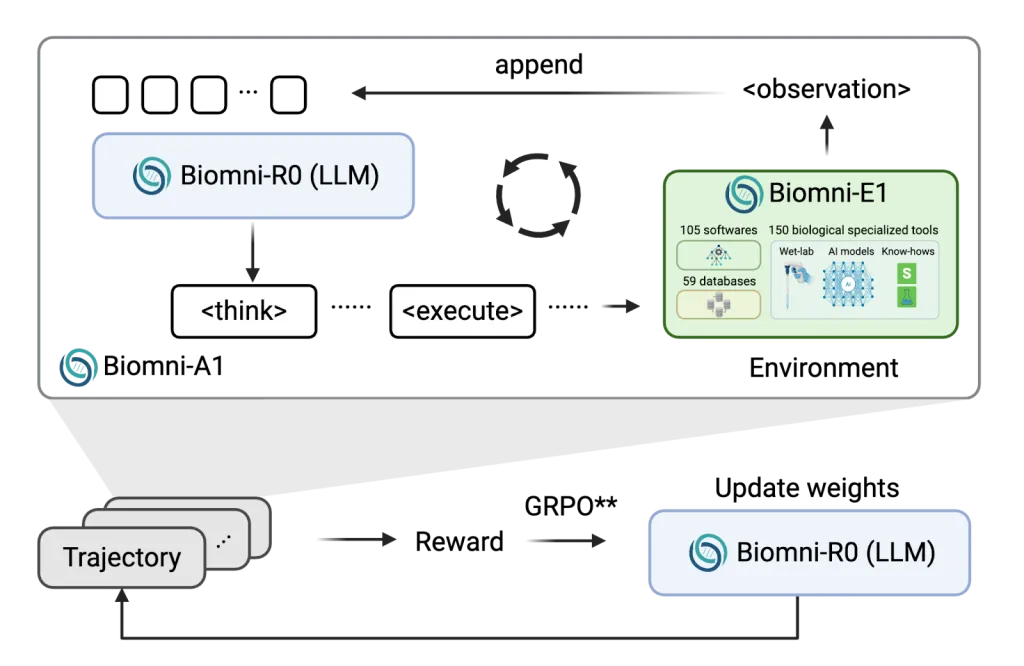
Researchers from Stanford College and UC Berkeley launched a brand new household of fashions referred to as Biomni-R0, constructed by making use of reinforcement studying (RL) to a biomedical agent basis. These fashions, Biomni-R0-8B and Biomni-R0-32B, have been educated in an RL surroundings particularly tailor-made for biomedical reasoning, utilizing each expert-annotated duties and a novel reward construction. The collaboration combines Stanford’s Biomni agent and surroundings platform with UC Berkeley’s SkyRL reinforcement studying infrastructure, aiming to push biomedical brokers previous human-level capabilities.
Coaching Technique and System Design
The analysis launched a two-phase coaching course of. First, they used supervised fine-tuning (SFT) on high-quality trajectories sampled from Claude-4 Sonnet utilizing rejection sampling, successfully bootstrapping the agent’s potential to comply with structured reasoning codecs. Subsequent, they fine-tuned the fashions utilizing reinforcement studying, optimizing for 2 sorts of rewards: one for correctness (e.g., choosing the proper gene or analysis), and one other for response formatting (e.g., utilizing structured
To make sure computational effectivity, the crew developed asynchronous rollout scheduling that minimized bottlenecks brought on by exterior device delays. In addition they expanded the context size to 64k tokens, permitting the agent to handle lengthy multi-step reasoning conversations successfully.
Outcomes That Outperform Frontier Fashions
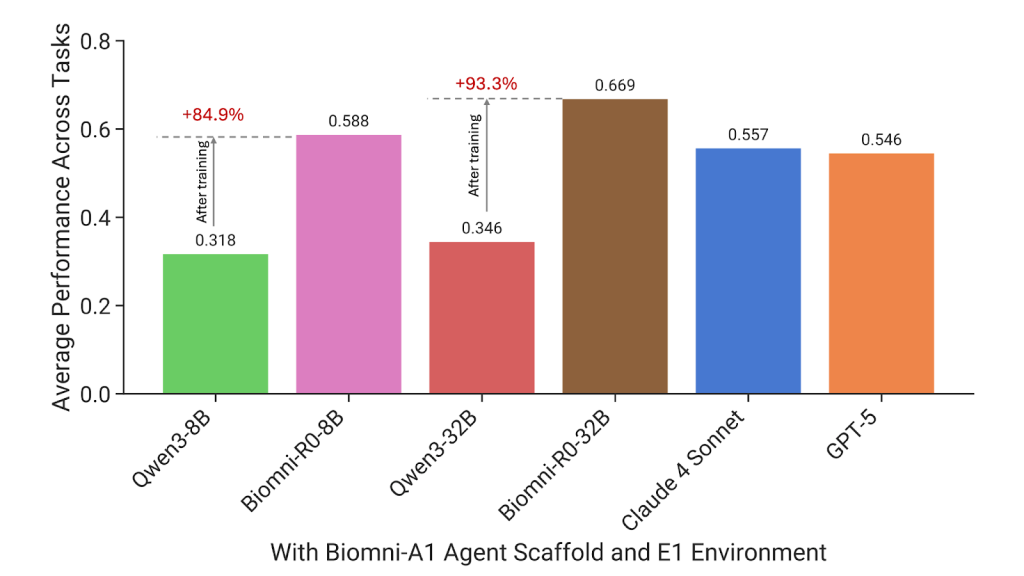
The efficiency positive factors have been vital. Biomni-R0-32B achieved a rating of 0.669, a soar from the bottom mannequin’s 0.346. Even Biomni-R0-8B, the smaller model, scored 0.588, outperforming general-purpose fashions like Claude 4 Sonnet and GPT-5, that are each a lot bigger. On a task-by-task foundation, Biomni-R0-32B scored highest on 7 out of 10 duties, whereas GPT-5 led in 2, and Claude 4 in simply 1. One of the crucial placing outcomes was in uncommon illness analysis, the place Biomni-R0-32B reached 0.67, in comparison with Qwen-32B’s 0.03, a greater than 20× enchancment. Equally, in GWAS variant prioritization, the mannequin’s rating elevated from 0.16 to 0.74, demonstrating the worth of domain-specific reasoning.
Designing for Scalability and Precision
Coaching massive biomedical brokers requires coping with resource-heavy rollouts involving exterior device execution, database queries, and code analysis. To handle this, the system decoupled surroundings execution from mannequin inference, permitting extra versatile scaling and lowering idle GPU time. This innovation ensured environment friendly use of assets, even with instruments that had various execution latencies. Longer reasoning sequences additionally proved helpful. The RL-trained fashions persistently produced lengthier, structured responses, which strongly correlated with higher efficiency, highlighting that depth and construction in reasoning are key indicators of expert-level understanding in biomedicine.
Key Takeaways from the analysis embrace:
- Biomedical brokers should carry out deep reasoning, not simply retrieval, throughout genomics, diagnostics, and molecular biology.
- The central downside is attaining expert-level activity efficiency, primarily in complicated areas equivalent to uncommon illnesses and gene prioritization.
- Conventional strategies, together with supervised fine-tuning and retrieval-based fashions, usually fall brief by way of robustness and adaptableness.
- Biomni-R0, developed by Stanford and UC Berkeley, makes use of reinforcement studying with expert-based rewards and structured output formatting.
- The two-phase coaching pipeline, SFT adopted by RL, proved extremely efficient in optimizing efficiency and reasoning high quality.
- Biomni-R0-8B delivers robust outcomes with a smaller structure, whereas Biomni-R0-32B units new benchmarks, outperforming Claude 4 and GPT-5 on 7 of 10 duties.
- Reinforcement studying enabled the agent to generate longer, extra coherent reasoning traces, a key trait of skilled habits.
- This work lays the muse for super-expert biomedical brokers, able to automating complicated analysis workflows with precision.
Take a look at the Technical details. Be at liberty to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.