The sphere of huge language fashions has lengthy been dominated by autoregressive strategies that predict textual content sequentially from left to proper. Whereas these approaches energy immediately’s most succesful AI programs, they face basic limitations in computational effectivity and bidirectional reasoning. A analysis crew from China has now challenged the belief that autoregressive modeling is the one path to attaining human-like language capabilities, introducing an modern diffusion-based structure known as LLaDA that reimagines how language fashions course of info.
Present language fashions function by way of next-word prediction, requiring more and more advanced computations as context home windows develop. This sequential nature creates bottlenecks in processing pace and limits effectiveness on duties requiring reverse reasoning. For example, conventional autoregressive fashions endure from the reversal curse—a phenomenon the place fashions skilled to foretell the following token battle with backward logical duties. Take into account poetry completion:
- Ahead Activity (Autoregressive Energy): Given the immediate “Roses are crimson,” fashions simply proceed with “violets are blue.”
- Reversal Activity (Autoregressive Weak point): Given “violets are blue,” the identical fashions typically fail to recall “Roses are crimson” because the previous line.
This directional bias stems from their coaching to foretell textual content strictly left-to-right. Whereas masked language fashions (like BERT) exist, they historically use mounted masking ratios, limiting their generative capabilities. The researchers suggest LLaDA (Giant Language Diffusion with mAsking), which implements a dynamic masking technique throughout diffusion steps to beat these constraints (Illustrated in Fig. 2). Not like autoregressive fashions, LLaDA processes tokens in parallel by way of a bidirectional framework, studying contextual relationships in all instructions concurrently.
LLaDA’s structure employs a transformer with out causal masking, skilled by way of two phases:
- Pre-training: The mannequin learns to reconstruct randomly masked textual content segments throughout 2.3 trillion tokens. Think about repairing a broken manuscript the place phrases vanish unpredictably—LLaDA practices filling gaps in any order. For instance:
- Begin with a masked sentence: “[MASK] are crimson, [MASK] are blue.”
- Predict “violets” for the second clean first, then “Roses” for the primary.
- Repeated masking/unmasking cycles eradicate directional bias.
- Supervised Superb-Tuning: The mannequin adapts to instruction-response pairs by masking solely the response portion, enabling task-specific refinement whereas retaining bidirectional understanding.
Throughout era, LLaDA begins with absolutely masked output fields and iteratively refines predictions by way of confidence-based remasking:
- At every diffusion step, the mannequin predicts all masked tokens concurrently.
- Low-confidence predictions (e.g., unsure phrases in a poem’s opening line) are remasked for re-evaluation.
- This “semantic annealing” course of repeats till coherent textual content emerges.
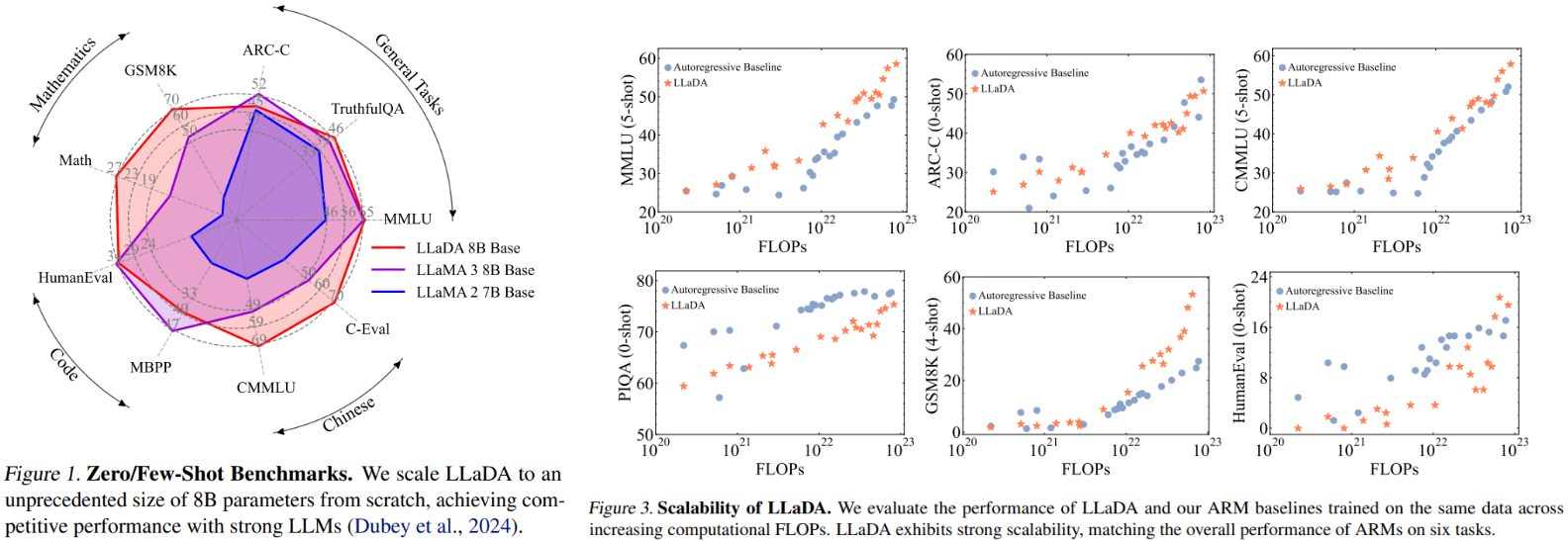
Efficiency evaluations reveal stunning capabilities. When scaled to eight billion parameters, LLaDA matches or exceeds equivalent-sized autoregressive fashions like LLaMA2-7B throughout 15 benchmarks, excelling in mathematical reasoning (GSM8K) and Chinese language duties. Crucially, it overcomes the reversal curse:
- Achieved 42% accuracy on backward poem completion duties vs. GPT-4’s 32%, whereas sustaining parity in ahead era.
- Demonstrated constant efficiency on reversal QA duties (e.g., “Who’s Tom Cruise’s mom?” vs. “Who’s Mary Lee Pfeiffer’s son?”), the place autoregressive fashions typically fail.
The mannequin additionally exhibits environment friendly scaling—computational prices develop comparably to conventional architectures regardless of its novel strategy. Notably, in duties equivalent to MMLU and GSM8K, LLaDA reveals even stronger scalability.
In abstract, this breakthrough suggests key language capabilities emerge from basic generative rules, not autoregressive designs alone. Whereas present implementations lag barely in duties like MMLU (possible resulting from information high quality variances), LLaDA establishes diffusion fashions as viable alternate options. The analysis opens doorways to parallel era and bidirectional reasoning, although challenges stay in inference optimization and alignment with human preferences. As the sector explores these alternate options, we could also be witnessing the early levels of a paradigm shift in how machines course of language—one the place fashions “suppose holistically” reasonably than being constrained to linear prediction.
Check out the Paper and Project Page. All credit score for this analysis goes to the researchers of this mission. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 75k+ ML SubReddit.
🚨 Beneficial Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Tackle Authorized Issues in AI Datasets
Vineet Kumar is a consulting intern at MarktechPost. He’s presently pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s enthusiastic about analysis and the newest developments in Deep Studying, Pc Imaginative and prescient, and associated fields.
