Massive Language Fashions (LLMs) have turn out to be an indispensable a part of modern life, shaping the way forward for practically each conceivable area. They’re extensively acknowledged for his or her spectacular efficiency throughout duties of various complexity. Nonetheless, cases have arisen the place LLMs have been criticized for producing surprising and unsafe responses. Consequently, ongoing analysis goals to align LLMs extra intently with human preferences whereas absolutely leveraging their intensive coaching information.
Strategies akin to Reinforcement Studying from Human Suggestions (RLHF) and Direct Desire Optimization (DPO) have confirmed efficient. Nonetheless, they nonetheless require iterative coaching, which is usually impractical. Researchers are due to this fact specializing in modifying inference approaches to match the efficiency of training-based optimization strategies. This text explores the most recent analysis that enhances human desire alignment throughout inference time.
Researchers from Shanghai AI Laboratory have launched Check-Time Desire Optimization (TPO), a novel framework designed to align LLM outputs with human preferences throughout inference. This framework may be conceptualized as a web-based, on-policy studying paradigm, the place the coverage mannequin repeatedly interacts with a novel reward mannequin to refine its outputs.
TPO incorporates a mechanism to leverage interpretable textual suggestions for desire optimization as a substitute of typical numerical scoring. To realize this, authors translate reward alerts into textual rewards by critiques. The mannequin then generates strategies by the remodeled rewards and updates its outputs to align with the alerts throughout testing.
Throughout the precise check, the newly generated responses are scored at every inference-time optimization step, and the intense ends of response high quality are labeled as “chosen” or “rejected” outputs. The mannequin then learns the power from the very best or “chosen” outputs and the shortfalls of rejected responses to compile a “textual loss.” The mannequin then generates strategies or “ textual gradients” for the subsequent iteration. TPO thus improves the output iteratively primarily based on interactions with textual content rewards.
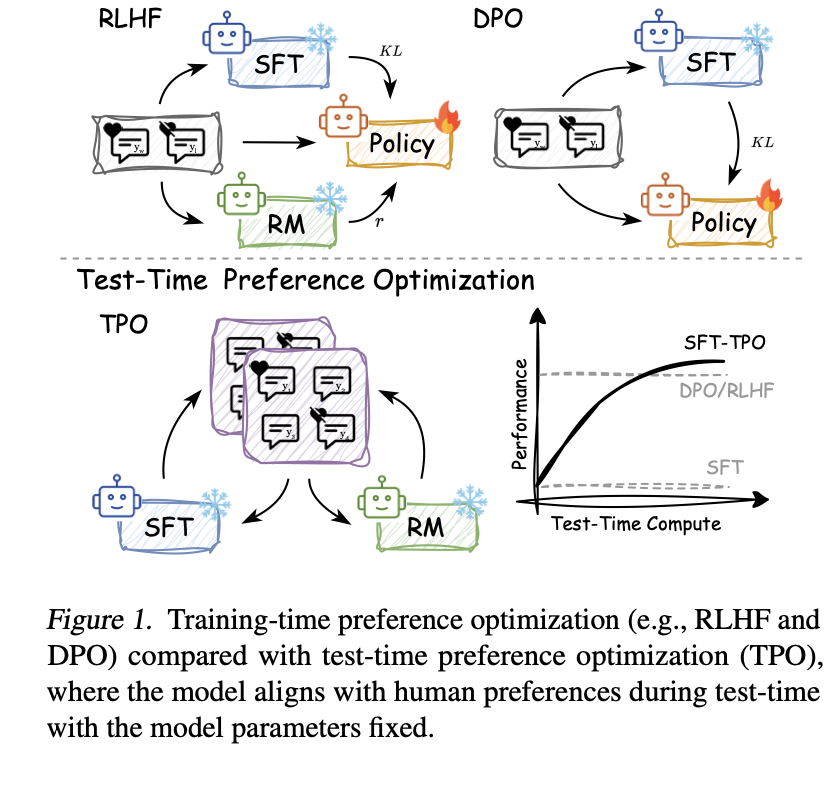
The authors used aligned and unaligned coverage fashions to validate the idea and decide whether or not the mannequin had undergone desire optimization throughout coaching. Two key fashions included within the examine had been Llama-3.1-70B-SFT, an unaligned mannequin that didn’t bear desire optimization throughout coaching, and Llama-3.1-70B-Instruct, an aligned mannequin educated with desire optimization. Moreover, experiments spanned many datasets to judge instruction following, desire alignment, security, and mathematical reasoning.
Outcomes from these experiments confirmed that just a few TPO optimization steps considerably improved efficiency in each aligned and unaligned fashions. When evaluating TPO-based inference optimization with conventional coaching optimization approaches, researchers discovered that the unaligned Llama-3.1-70B-SFT mannequin outperformed its aligned counterpart Llama-3.1-70B-Instruct after present process TPO epochs. Moreover, making use of TPO to an aligned mannequin with as few as 22 billion parameters achieved an LC rating of 53.4% and a WR rating of 72.2%
Conclusion: The analysis crew launched TPO, a web-based, on-policy studying framework to align outputs from LLMs by human desire. This framework optimized the responses in inference time and eradicated the trouble of retraining and weight updates. Moreover, TPO provided excessive scalability and suppleness, making it a promising strategy for future LLM works.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Adeeba Alam Ansari is at present pursuing her Twin Diploma on the Indian Institute of Know-how (IIT) Kharagpur, incomes a B.Tech in Industrial Engineering and an M.Tech in Monetary Engineering. With a eager curiosity in machine studying and synthetic intelligence, she is an avid reader and an inquisitive particular person. Adeeba firmly believes within the energy of expertise to empower society and promote welfare by revolutionary options pushed by empathy and a deep understanding of real-world challenges.