The fast development of AI applied sciences highlights the essential want for Giant Language Fashions (LLMs) that may carry out successfully throughout various linguistic and cultural contexts. A key problem is the shortage of analysis benchmarks for non-English languages, which limits the potential of LLMs in underserved areas. Most present analysis frameworks are English-centric, creating boundaries to growing equitable AI applied sciences. This analysis hole discourages practitioners from coaching multilingual fashions and widens digital divides throughout completely different language communities. Technical challenges additional compound these points, together with restricted dataset variety, translation-based knowledge assortment strategies, and so on.
Current analysis efforts have made vital enhancements in growing analysis benchmarks for LLMs. Pioneering frameworks like GLUE and SuperGLUE superior language understanding duties, whereas subsequent benchmarks equivalent to MMLU, HellaSwag, ARC, GSM8K, and BigBench enhanced data comprehension and reasoning. Nevertheless, these benchmarks predominantly targeted on English-based knowledge, creating substantial limitations for multilingual mannequin improvement. Datasets like Exams and Aya try broader language protection, however they’re restricted in scope both specializing in particular academic curricula or missing region-specific analysis depth. Cultural understanding benchmarks discover language and societal nuances however don’t present holistic approaches to multilingual mannequin evaluation.
Researchers from EPFL, Cohere For AI, ETH Zurich, and the Swiss AI Initiative have proposed a complete multilingual language understanding benchmark referred to as INCLUDE. The benchmark addresses the essential gaps in present analysis methodologies by gathering regional assets immediately from native language sources. Researchers designed an revolutionary pipeline to seize genuine linguistic and cultural nuances utilizing academic, skilled, and sensible checks particular to completely different international locations. The benchmark consists of 197,243 multiple-choice question-answer pairs from 1,926 examinations throughout 44 languages and 15 distinctive scripts. These examinations are collected from native sources in 52 international locations.
The INCLUDE benchmark makes use of a fancy annotation methodology to analyze elements driving multilingual efficiency. The researchers developed a complete categorization strategy that addresses the challenges of sample-level annotation by labeling examination sources as a substitute of particular person questions. This technique permits for a nuanced understanding of the dataset’s composition whereas managing the prohibitive prices of detailed annotation. The annotation framework consists of two major categorization schemes. Area-agnostic questions, comprising 34.4% of the dataset, cowl common matters like arithmetic and physics. Area-specific questions are additional subdivided into specific, cultural, and implicit regional data classes.
The analysis of the INCLUDE benchmark reveals detailed insights into multilingual LLM efficiency throughout 44 languages. GPT-4o emerge as the highest performer, reaching a formidable accuracy of roughly 77.1% throughout all domains. Chain-of-Thought (CoT) prompting reveals average efficiency enhancements in Skilled and STEM-related examinations, with minimal good points in Licenses and Humanities domains. Bigger fashions like Aya-expanse-32B and Qwen2.5-14B present substantial enhancements over their smaller counterparts, with 12% and seven% efficiency good points respectively. Gemma-7B reveals the very best efficiency amongst smaller fashions, excelling within the Humanities and Licenses classes, whereas Qwen fashions present superiority in STEM and Skilled domains.
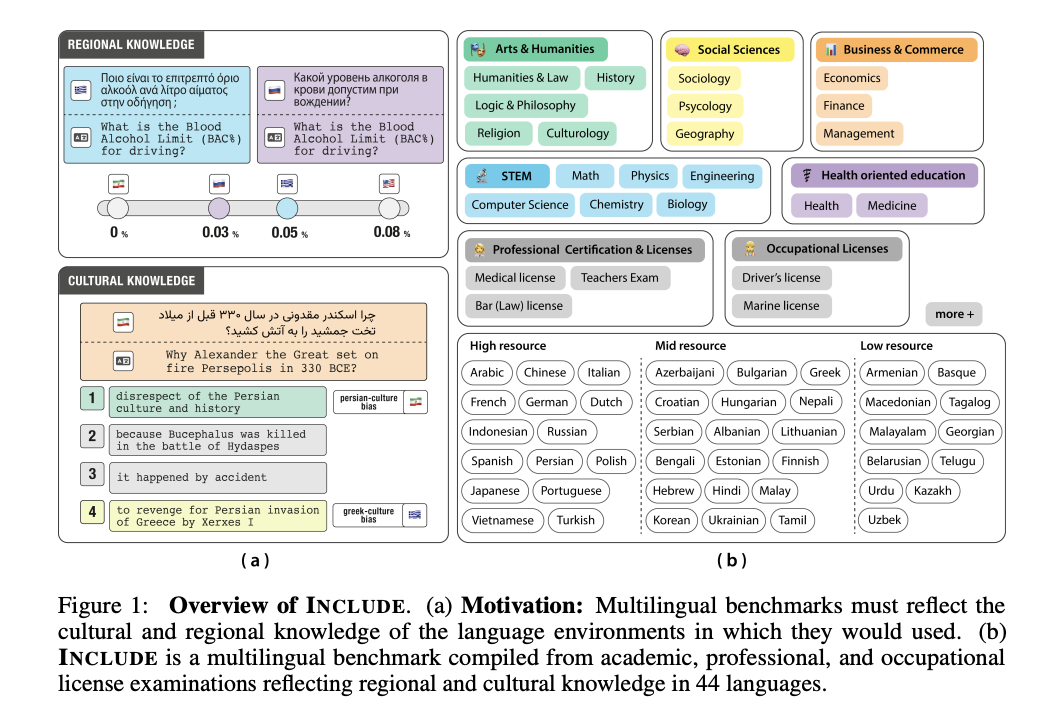
In conclusion, researchers launched the INCLUDE benchmark which represents an development in multilingual LLM analysis. By compiling 197,243 multiple-choice question-answer pairs from 1,926 examinations throughout 44 languages and 15 scripts, the researchers present a framework for evaluating regional and cultural data understanding in AI methods. The analysis of 15 completely different fashions reveals vital variability in multilingual efficiency and highlights alternatives for enchancment in regional data comprehension. This benchmark units a brand new normal for multilingual AI evaluation and underscores the necessity for continued innovation in creating extra equitable, culturally conscious synthetic intelligence applied sciences.
Take a look at the Paper and Dataset. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our newsletter.. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 [Partner with us]: ‘Subsequent Journal/Report- Open Supply AI in Manufacturing’

Sajjad Ansari is a last 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a give attention to understanding the influence of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.