Diffusion Insurance policies in Imitation Studying (IL) can generate numerous agent behaviors, however as fashions develop in measurement and functionality, their computational calls for enhance, resulting in slower coaching and inference. This challenges real-time purposes, particularly in environments with restricted computing energy, like cell robots. These insurance policies want many parameters and denoising steps and, thus, are unsuitable to be used in such situations. Though such fashions will be scaled with better quantities of knowledge, their massive computational value poses a major limitation.
Present strategies in robotics, comparable to Transformer-based Diffusion Fashions, are used for duties like Imitation Studying, Offline Reinforcement Studying, and robotic design. These fashions depend on Convolutional Neural Networks (CNNs) or transformers with conditioning methods like FiLM. Whereas able to producing multimodal conduct, they’re computationally costly on account of massive parameters and plenty of denoising steps, slowing coaching and inference, making them impractical for real-time purposes. Moreover, Combination-of-Consultants (MoE) fashions face points like skilled collapse and inefficient capability use. Regardless of load-balancing options, these fashions battle to optimize the router and consultants, resulting in suboptimal efficiency.
To deal with the restrictions of present strategies, researchers from the Karlsruhe Institute of Know-how and MIT launched MoDE, a Combination-of-Consultants (MoE) Diffusion Coverage designed for duties comparable to Imitation Studying and robotic design. MoDE improves effectivity by utilizing noise-conditioned routing and a self-attention mechanism for simpler denoising at numerous noise ranges. Not like conventional strategies that depend on a posh denoising course of, MoDE computes and integrates solely the mandatory consultants at every noise stage, decreasing latency and computational value. This structure permits sooner and extra environment friendly inference whereas sustaining efficiency, attaining vital computational financial savings by using solely a subset of the mannequin’s parameters throughout every ahead go.
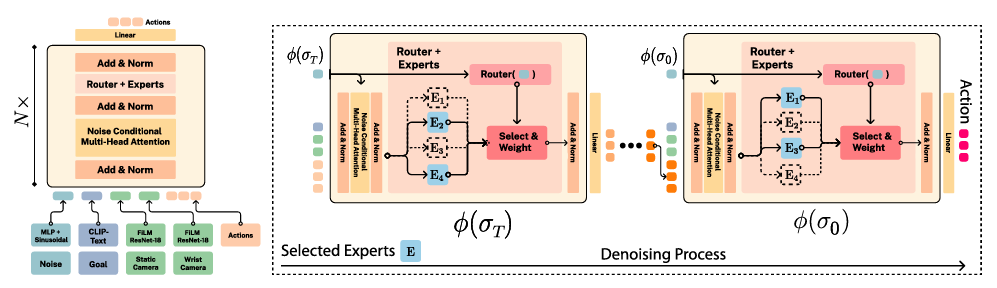
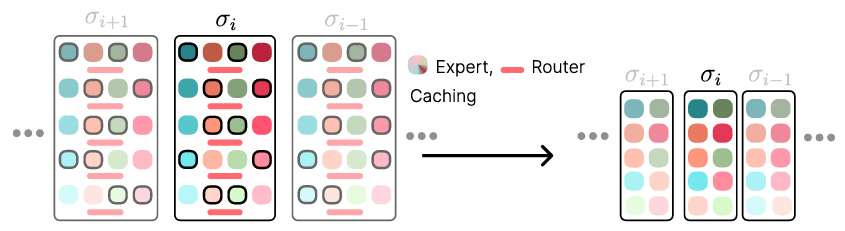
The MoDE framework employs a noise-conditioned strategy the place the routing of consultants is decided by the noise stage at every step. It makes use of a frozen CLIP language encoder for language conditioning and FiLM-conditioned ResNets for picture encoding. The mannequin incorporates a sequence of transformer blocks, every accountable for totally different denoising phases. By introducing noise-aware positional embeddings and skilled caching, MoDE ensures that solely the mandatory consultants are used, decreasing computational overhead. The researchers carried out in depth analyses of MoDE’s parts, which offer helpful insights for designing environment friendly and scalable transformer architectures for diffusion insurance policies. Pretraining on numerous multi-robot datasets permits MoDE to outperform current generalist insurance policies.
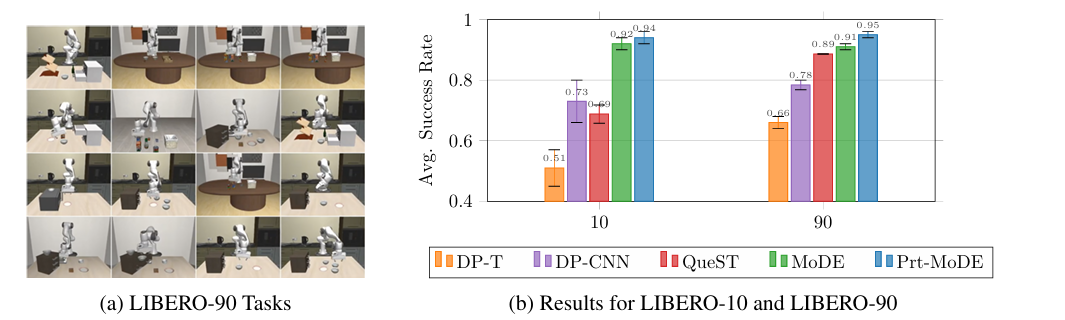
Researchers carried out experiments to guage MoDE on a number of key questions, together with its efficiency in comparison with different insurance policies and diffusion transformer architectures, the impact of large-scale pretraining on its efficiency, effectivity, and velocity, and the effectiveness of token routing methods in several environments. The experiments in contrast MoDE with prior diffusion transformer architectures, making certain equity by utilizing an identical variety of energetic parameters, and examined it on each long-horizon and short-horizon duties. MoDE achieved the very best efficiency in benchmarks comparable to LIBERO–90, outperforming different fashions like Diffusion Transformer and QueST. Pretraining MoDE boosted its efficiency, demonstrating its potential to study long-horizon duties and its effectivity in computational use. MoDE additionally confirmed superior efficiency on the CALVIN Language-Abilities Benchmark, surpassing fashions like RoboFlamingo and GR-1 whereas sustaining greater computational effectivity. MoDE outperformed all baselines in zero-shot generalization duties and demonstrated robust generalization capabilities.
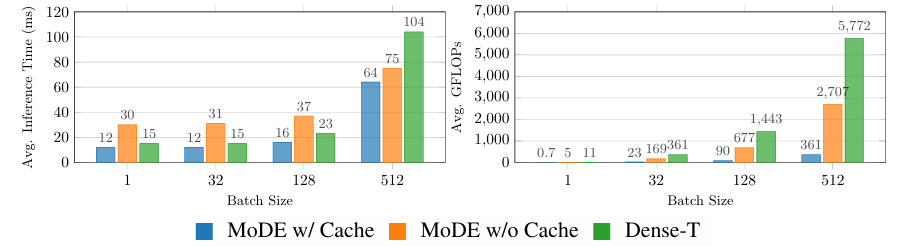
In conclusion, the proposed framework improves efficiency and effectivity utilizing a mix of consultants, a Transformer, and a noise-conditioned routing technique. The mannequin outperformed earlier Diffusion Insurance policies, requiring fewer parameters and lowered computational prices. Due to this fact, this framework can be utilized as a baseline to enhance the mannequin’s scalability in future analysis research. Future research may focus on the applying of MoDE throughout different domains as a result of it has to date been attainable to proceed scaling up whereas sustaining high-performance ranges in machine studying duties.
Check out the Paper and Model on Hugging Face. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.