Imaginative and prescient-language fashions (VLMs) have demonstrated spectacular capabilities generally picture understanding, however face important challenges when processing text-rich visible content material similar to charts, paperwork, diagrams, and screenshots. These specialised photographs require complicated reasoning that mixes textual comprehension with spatial understanding—a talent set crucial for analysing scientific literature, enhancing accessibility options, and enabling AI brokers to perform successfully in real-world environments. Present VLMs wrestle with these duties primarily because of the shortage of high-quality coaching information that realistically represents the varied array of text-embedded visible codecs encountered in sensible functions. This information limitation has created a efficiency hole in eventualities requiring nuanced interpretation of structured visible info, hampering the deployment of those fashions in specialised domains the place text-rich picture processing is important.
A number of approaches have been developed to boost vision-language fashions for processing visible content material. Early architectures explored totally different integration methods together with cross-attention mechanisms, Q-Former constructions, and MLP projection layers to bridge visible and linguistic options. Nevertheless, these fashions usually undergo from important imbalance i-e their language elements considerably outweigh visible processing capabilities, resulting in hallucinations when high-quality coaching information is scarce. Current benchmarks for text-rich picture understanding (charts, paperwork, infographics, diagrams, screenshots) stay restricted in measurement, scope, and variety, making them appropriate for analysis however insufficient for complete coaching. Earlier artificial information technology efforts have sometimes targeted on slender domains utilizing small units of chart varieties with handcrafted query templates. Some approaches make the most of text-only LLMs to generate annotations from tables or descriptions, whereas others discover code-based rendering of artificial charts. Regardless of these advances, present artificial datasets stay constrained in subject variety, determine selection, and rendering methodology—crucial limitations that hinder generalization to novel, out-of-distribution duties.
A group of researchers from College of Pennsylvania, and Allen Institute for Synthetic Intelligence launched the Code Guided Artificial Knowledge Era System (CoSyn) which presents a versatile framework to deal with the challenges in text-rich picture processing by creating various artificial multimodal coaching information. This progressive system makes use of the code technology capabilities of text-only LLMS to supply each information and rendering code for numerous text-rich visible codecs utilizing 11 supported rendering instruments together with Python, HTML, and LaTeX. CoSyn generates not solely the pictures but additionally corresponding textual directions grounded within the underlying code illustration, creating complete vision-language instruction-tuning datasets. The researchers used this framework to develop CoSyn-400K, a large-scale various artificial dataset particularly designed for text-rich picture understanding.

The CoSyn system operates via a classy four-stage workflow starting with a pure language question like “generate a dataset of e-book covers.” First, the system selects one in every of 20 technology pipelines constructed on 11 various rendering instruments together with Matplotlib, Plotly, LaTeX, HTML, Mermaid, and specialised instruments like Lilypond for music sheets and RDKit for chemical constructions. The method begins with subject technology guided by sampled personas that improve content material variety, adopted by detailed information technology that populates content material particular to the chosen subject. Subsequent, the system generates executable code that renders the artificial photographs utilizing the suitable software. Lastly, utilizing solely the code as context, the system prompts language fashions to generate corresponding textual directions, together with questions, solutions, and chain-of-thought reasoning explanations. To reinforce variety past what sampling parameters alone can obtain, CoSyn incorporates 200K distinctive personas throughout subject technology, successfully countering the repetitive output tendencies of language fashions. The implementation leverages the DataDreamer library for strong multi-stage technology, utilizing Claude-3.5-Sonnet for code technology and GPT-4o-mini for instruction information technology.
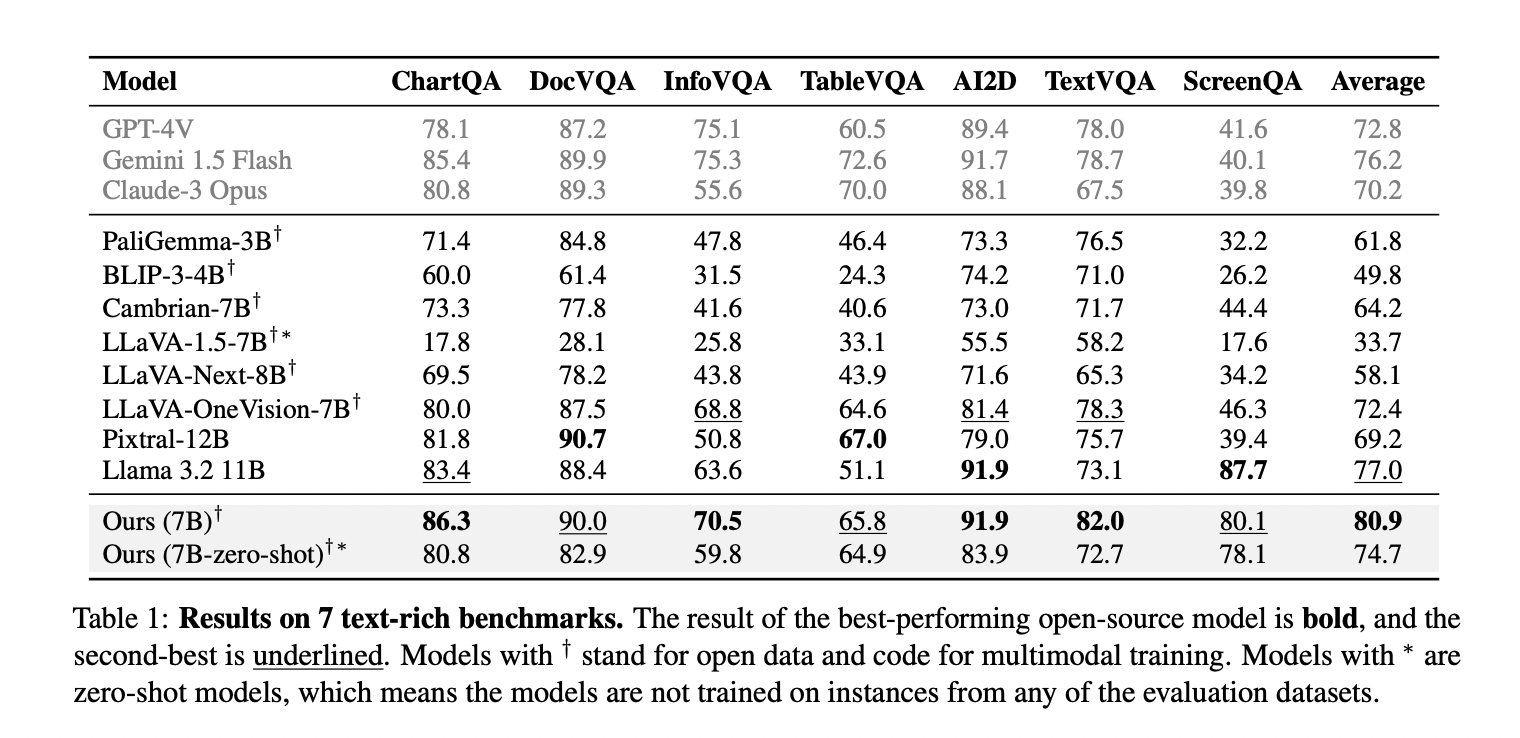
The mannequin educated on CoSyn’s artificial information demonstrates distinctive efficiency throughout text-rich picture understanding benchmarks. When evaluated towards seven specialised datasets, the 7B parameter mannequin achieves the very best common efficiency, surpassing the second-best mannequin (Llama 3.2 11B) by a major margin of three.9%. The mannequin ranks first in 4 out of seven benchmarks and second within the remaining three, highlighting its constant capabilities throughout various text-rich picture duties. Maybe most remarkably, even the zero-shot model of the mannequin with none publicity to coaching situations from analysis datasets outperforms most competing open and closed fashions, together with people who had been fine-tuned on benchmark coaching information. This surprising consequence offers compelling proof that the talents acquired from CoSyn’s artificial information switch successfully to downstream duties with out requiring domain-specific coaching examples. Further ablation research reveal that combining artificial information with auxiliary and analysis datasets yields the very best efficiency (80.9%), considerably outperforming fashions educated on analysis information alone (75.9%).
The CoSyn framework represents a major development in vision-language mannequin growth, using artificial information technology to considerably enhance efficiency on text-rich picture understanding duties. By harnessing the code technology capabilities of text-only LLMs, the system creates various, high-quality coaching information that permits fashions to generalize throughout domains with outstanding effectivity. Evaluation confirms that CoSyn-generated information efficiently mitigates biases current in present datasets, leading to fashions that carry out robustly on reasonable, human-written queries reasonably than simply template-based questions. The demonstrated enhancements in zero-shot studying, multi-hop reasoning, and novel area adaptation spotlight artificial information’s essential function in growing VLMs able to dealing with complicated text-rich visible content material in sensible functions.
Check out the Paper and Dataset right here. All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 80k+ ML SubReddit.
🚨 Really helpful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Handle Authorized Considerations in AI Datasets
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.