Optimization principle has emerged as an important discipline inside machine studying, offering exact frameworks for adjusting mannequin parameters effectively to realize correct studying outcomes. This self-discipline focuses on maximizing the effectiveness of methods like stochastic gradient descent (SGD), which types the spine of quite a few fashions in deep studying. Optimization impacts numerous functions, from picture recognition and pure language processing to autonomous techniques. Regardless of its established significance, the theory-practice hole stays, with theoretical optimization fashions generally failing to match the sensible calls for of advanced, large-scale issues totally. Aiming to shut this hole, researchers repeatedly advance optimization methods to spice up efficiency and robustness throughout various studying environments.
Defining a dependable studying charge schedule is difficult in machine studying optimization. A studying charge dictates the mannequin’s step dimension throughout coaching, influencing convergence pace and total accuracy. In most eventualities, schedules are predefined, requiring the consumer to set a coaching length prematurely. This setup limits adaptability, because the mannequin can’t reply dynamically to information patterns or coaching anomalies. Inappropriate studying charge schedules may end up in unstable studying, slower convergence, and degraded efficiency, particularly in high-dimensional, advanced datasets. Thus, the shortage of flexibility in studying charge scheduling nonetheless must be solved, motivating researchers to develop extra adaptable and self-sufficient optimization strategies that may function with out specific scheduling.
The present strategies for studying charge scheduling usually contain decaying methods, reminiscent of cosine or linear decay, which systematically decrease the training charge over the coaching length. Whereas efficient in lots of instances, these approaches require fine-tuning to make sure optimum outcomes, they usually carry out suboptimally if the parameters should be appropriately set. Alternatively, strategies like Polyak-Ruppert averaging have been proposed, which averages over a sequence of steps to succeed in a theoretically optimum state. Nonetheless, regardless of their theoretical benefits, such strategies usually lag behind schedule-based approaches relating to convergence pace and sensible efficacy, significantly in real-world machine studying functions with excessive variance.
Researchers from Meta, Google Analysis, Samsung AI Middle, Princeton College, and Boston College launched a novel optimization technique named Schedule-Free AdamW. Their strategy eliminates the necessity for predefined studying charge schedules, leveraging an revolutionary momentum-based technique that adjusts dynamically all through coaching. The Schedule-Free AdamW combines a brand new theoretical foundation for merging scheduling with iterate averaging, enabling it to adapt with out extra hyper-parameters. By eschewing conventional schedules, this technique enhances flexibility and matches or exceeds the efficiency of schedule-based optimization throughout numerous downside units, together with large-scale deep-learning duties.
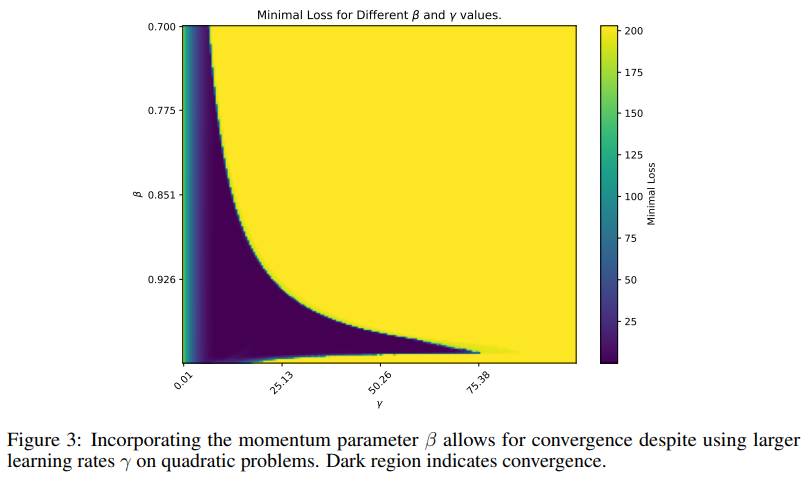
The underlying mechanism of Schedule-Free AdamW depends on a specialised momentum parameter that balances quick convergence with stability, addressing the core challenge of gradient stability, which might decline in high-complexity fashions. By adopting the averaging strategy, Schedule-Free AdamW optimizes and not using a stopping level, bypassing conventional scheduling constraints. This system permits the tactic to take care of sturdy convergence properties and keep away from efficiency points generally related to mounted schedules. The algorithm’s distinctive interpolation of gradient steps ends in improved stability and decreased large-gradient impression, which is often an issue in deep-learning optimizations.

In checks on datasets like CIFAR-10 and ImageNet, the algorithm outperformed established cosine schedules, attaining 98.4% accuracy on CIFAR-10, surpassing the cosine strategy by roughly 0.2%. Additionally, within the MLCommons AlgoPerf Algorithmic Effectivity Problem, the Schedule-Free AdamW claimed the highest place, affirming its superior efficiency in real-world functions. The tactic additionally demonstrated sturdy outcomes throughout different datasets, bettering accuracy by 0.5% to 2% over cosine schedules. Such sturdy efficiency means that Schedule-Free AdamW could possibly be extensively adopted in machine studying workflows, particularly for functions delicate to gradient collapse, the place this technique provides enhanced stability.
Key Takeaways from the Analysis:
- The Schedule-Free AdamW removes the necessity for conventional studying charge schedules, which regularly restrict flexibility in coaching.
- In empirical checks, Schedule-Free AdamW achieved a 98.4% accuracy on CIFAR-10, outperforming the cosine schedule by 0.2% and demonstrating superior stability.
- The tactic gained the MLCommons AlgoPerf Algorithmic Effectivity Problem, verifying its effectiveness in real-world functions.
- This optimizer’s design ensures excessive stability, particularly on datasets liable to gradient collapse, marking it a strong various for advanced duties.
- The algorithm gives quicker convergence than present strategies by integrating a momentum-based averaging method, bridging the hole between principle and follow in optimization.
- Schedule-Free AdamW makes use of fewer hyper-parameters than comparable methods, enhancing its adaptability throughout various machine studying environments.

In conclusion, this analysis addresses the constraints of studying charge schedules by presenting a schedule-independent optimizer that maintains and infrequently exceeds the efficiency of conventional strategies. The Schedule-Free AdamW gives an adaptable, high-performing various, enhancing the practicality of machine studying fashions with out sacrificing accuracy or requiring intensive hyperparameter tuning.
Take a look at the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.