LLMs excel in code era however battle with complicated programming duties requiring deep algorithmic reasoning and complex logic. Conventional end result supervision approaches, which information closing output high quality fashions, are restricted in addressing these challenges. Course of supervision utilizing Course of Reward Fashions (PRMs) has proven promise by specializing in reasoning steps, but it surely calls for in depth annotated knowledge and is vulnerable to inaccuracies in evaluating complicated reasoning. Code era uniquely advantages from execution suggestions, providing verifiable correctness and efficiency insights. Nonetheless, present strategies prioritize debugging and native refinements, overlooking alternatives to discover modern algorithmic methods for enhanced efficiency.
Researchers from Peking College and Microsoft Analysis suggest End result-Refining Course of Supervision (ORPS), a novel framework that supervises the reasoning course of by refining outcomes. In contrast to conventional strategies targeted on iterative suggestions, ORPS makes use of a tree-structured exploration to handle a number of reasoning paths concurrently, enabling various answer methods when preliminary makes an attempt fail. The method leverages execution suggestions as goal verification, eliminating the necessity for coaching PRMs. Experiments present that ORPS considerably improves efficiency, with a mean 26.9% improve in correctness and a 42.2% enhance in effectivity throughout 5 fashions and three datasets, highlighting its scalability and reliability in fixing complicated programming duties.
Conventional end result supervision in machine studying focuses solely on evaluating closing outputs, usually by metrics or language model-based judgments. Whereas these strategies supply richer suggestions than primary evaluations, they fail to evaluate the intermediate reasoning steps essential for complicated duties. In distinction, course of supervision evaluates the standard of every step utilizing PRMs, which information reasoning by assigning rewards primarily based on intermediate progress. Nonetheless, PRMs rely closely on dense human annotations, face generalization points, and might produce unreliable evaluations on account of mannequin hallucinations. These spotlight the necessity for various approaches that floor reasoning in concrete, verifiable alerts slightly than realized judgments.
ORPS addresses these challenges by treating end result refinement as an iterative course of that must be supervised. The framework integrates theoretical reasoning, sensible implementation, and execution suggestions by a tree-structured exploration with beam search, enabling various answer paths. In contrast to conventional PRMs, ORPS makes use of execution outcomes as goal anchors to information and consider reasoning, eliminating the necessity for costly coaching knowledge. A self-critic mechanism additional refines options by analyzing reasoning chains and efficiency metrics, permitting fashions to enhance theoretical methods and implementation effectivity. This method reduces hallucination dangers and considerably enhances success charges and effectivity in fixing complicated programming duties.
The examine evaluates a brand new code era framework to enhance efficiency on programming benchmarks. The framework is examined on three datasets: LBPP, HumanEval, and MBPP, specializing in key questions reminiscent of its effectiveness, contributions of particular person parts, and the connection between reasoning high quality and code era. The outcomes present vital correctness and code high quality enhancements, significantly on extra complicated benchmarks. The tactic outperforms different execution-feedback approaches, and entry to check instances boosts efficiency additional. Ablation research reveal that execution outcomes are extra essential than reasoning alone for optimum efficiency.
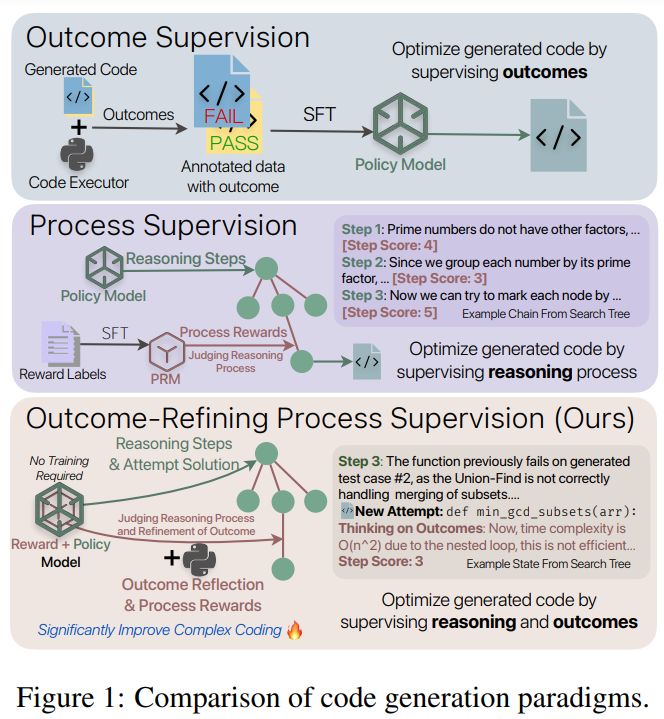
In conclusion, the examine introduces ORPS, an method to enhance code era by integrating structured reasoning with execution-driven suggestions. ORPS employs a tree-structured exploration framework that helps various answer paths, permitting fashions to boost reasoning and implementation concurrently. Experiments throughout a number of benchmarks confirmed vital beneficial properties, with a mean enchancment of 26.9% and a 42.2% discount in runtime, outperforming conventional strategies. ORPS successfully makes use of execution suggestions, lowering dependence on expensive annotated knowledge. This method highlights the significance of structured reasoning and concrete suggestions for complicated programming duties and affords a cost-efficient various for advancing computational intelligence.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 65k+ ML SubReddit.
🚨 Recommended Open-Source AI Platform: ‘Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios.’ (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.