Pre-trained LLMs require instruction tuning to align with human preferences. Nonetheless, the huge information assortment and speedy mannequin iteration typically result in oversaturation, making environment friendly information choice a vital but underexplored space. Current quality-driven choice strategies, akin to LIMA and AlpaGasus, are likely to overlook the significance of information range and complexity, important for enhancing mannequin efficiency. Whereas scaling LLMs has confirmed useful, optimizing instruction fine-tuning (IFT) depends on coaching information’s high quality, range, and complexity. Nevertheless, measuring these components stays difficult, with current analysis calling for quantifiable metrics to evaluate dataset range reasonably than counting on subjective claims. Sparse autoencoders (SAEs) have not too long ago emerged as efficient instruments for deciphering LLMs by making certain mono-semantic representations, making them priceless for analyzing information choice mechanisms.
Sparse autoencoders have considerably improved LLM interpretability by implementing sparsity in representations, thereby enhancing function independence. Early works in sparse coding and dictionary studying laid the inspiration for structured information representations, later utilized to transformers to decode contextual embeddings. Latest analysis has highlighted the challenges of polysemantic neurons encoding a number of ideas, prompting efforts to develop monosemantic neurons for higher interpretability. In parallel, information choice strategies, akin to ChatGPT-based scoring and gradient-based clustering, have been explored to refine instruction tuning. Regardless of developments, precisely quantifying information high quality, range, and complexity stays complicated, necessitating additional analysis into efficient metrics and choice methods to optimize instruction tuning in LLMs.
Researchers at Meta GenAI introduce a diversity-aware information choice technique utilizing SAEs to enhance instruction tuning. SAEs assist quantify information range and improve mannequin interpretability, explaining strategies like deciding on the longest response. They develop two choice algorithms: SAE-GreedSelect for restricted information and SAE-SimScale for bigger datasets. Experiments on Alpaca and WizardLM_evol_instruct_70k datasets display superior efficiency over prior strategies. Their method refines information choice, reduces coaching prices, and affords deeper insights into mannequin habits, making instruction tuning extra environment friendly and interpretable.
The research introduces two diversity-driven information choice strategies utilizing SAEs. SAE-GreedSelect optimizes function utilization for choosing restricted information, whereas SAE-SimScale scales information choice utilizing similarity-based sampling. Experiments on Llama-2-13b, Gemma-2-9b, and Llama-2-7b-base validate the method utilizing Alpaca-52k and WizardLM_evol_instruct_70k datasets. Comparisons with baselines like Longest-response, #InsTag, and Repr Filter display superior efficiency. Fashions are skilled utilizing standardized settings and evaluated with IFEval, LLM- and Human-as-a-Choose strategies, and benchmarks like MMLU and TruthfulQA. Outcomes spotlight improved instruction tuning effectivity and interpretability whereas sustaining simplicity in parameter tuning.
Choosing the 1,000 longest responses is an efficient baseline for supervised fine-tuning (SFT), possible as a result of longer responses comprise extra learnable data. A powerful correlation (r = 0.92) between textual content size and have richness in an SAE helps this speculation. The proposed information choice strategies, SAE-GreedSelect and SAE-SimScale, outperform present baselines, notably at bigger information scales. SAE-SimScale achieves notable enhancements throughout a number of datasets and analysis metrics, highlighting its robustness. Additional experiments verify its effectiveness throughout mannequin sizes and architectures, reinforcing its potential for optimizing scalable information choice methods.
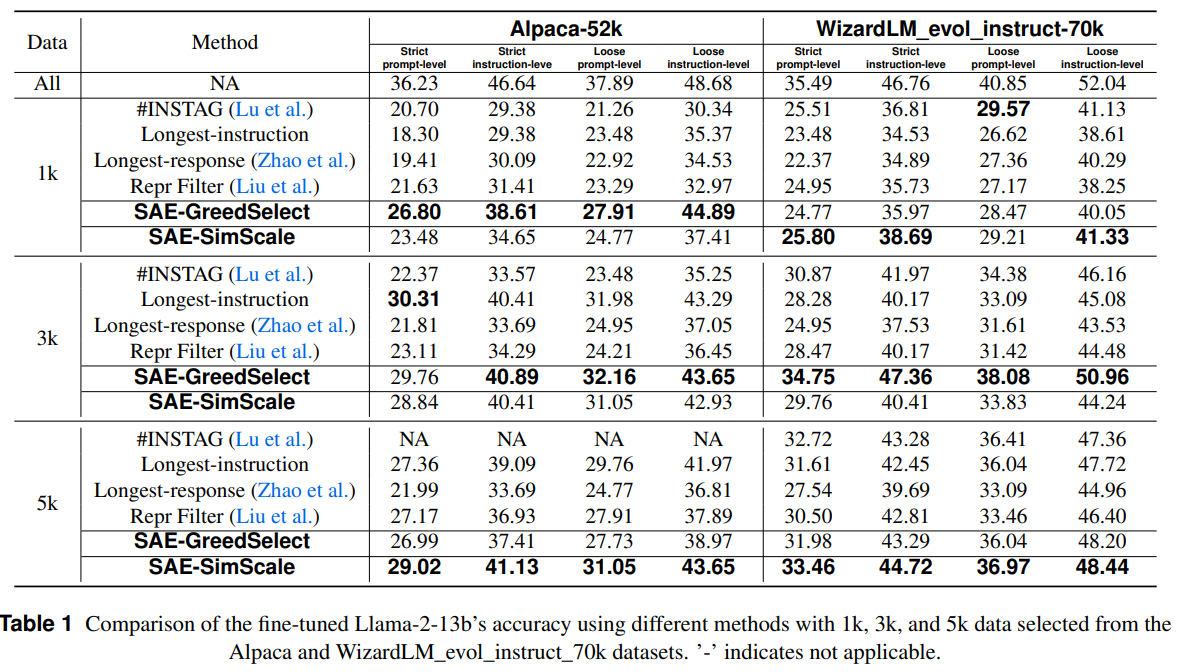
In conclusion, the research introduces an method to measuring information range utilizing discovered monosemanticity in sparse autoencoders. A brand new information choice algorithm for instruction tuning was developed, enhancing mannequin efficiency throughout numerous datasets. The strategy constantly outperforms present choice strategies and demonstrates that longer instruction-response pairs improve mannequin capabilities. The method additionally improves effectivity by decreasing information necessities and coaching prices. Moreover, it affords insights into mannequin habits and will be prolonged to choice information choice or enhancing mannequin security. This technique ensures higher alignment with human preferences whereas sustaining range and complexity in coaching information.
Check out the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.
🚨 Beneficial Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Deal with Authorized Considerations in AI Datasets
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.