Lexicon-based embeddings are one of many good options to dense embeddings, but they face quite a few challenges that restrain their wider adoption. One key drawback is tokenization redundancy, whereby subword tokenization breaks semantically equal tokens, inflicting inefficiencies and inconsistencies in embeddings. The opposite limitation of causal LLMs is unidirectional consideration; this implies tokens can’t totally leverage the encircling context whereas pretraining. These challenges confine the adaptability and effectivity of lexicon-based embeddings, particularly in duties past info retrieval, thereby making it essential to make the most of a stronger method than the earlier ones to make them extra helpful.
A number of methods have been proposed to analyze the potential for usages by lexicon-based embeddings. SPLADE makes use of bidirectional consideration and aligns the embeddings with language modeling targets, whereas PromptReps makes use of immediate engineering to supply lexicon-based embeddings in causal LLMs. SPLADE is proscribed to smaller fashions and a particular retrieval process, limiting its applicability. The PromptReps mannequin lacks contextual understanding with unidirectional consideration, and the efficiency obtained is suboptimal. This class of strategies typically has very excessive computational complexity, inefficiency because of fragmenting tokenization, and lacks scope for bigger purposes corresponding to clustering and classification.
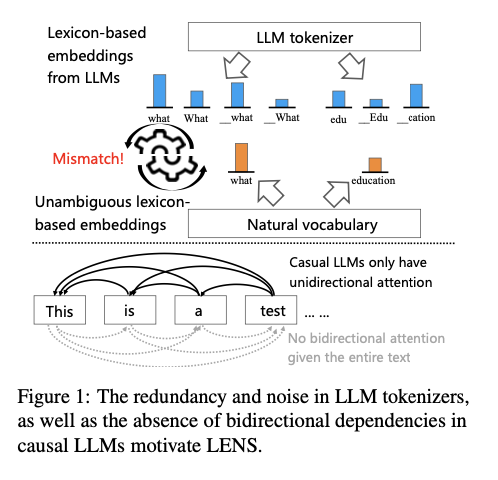
Researchers from the College of Amsterdam, the College of Know-how Sydney, and Tencent IEG suggest LENS (Lexicon-based EmbeddiNgS), a groundbreaking framework designed to deal with the constraints of present lexicon-based embedding methods. By means of making use of KMeans for the clustering of semantically analogous tokens, LENS successfully amalgamates token embeddings, thereby minimizing redundancy and dimensionality. This streamlined illustration facilitates the creation of embeddings characterised by lowered dimensions, all of the whereas sustaining semantic depth. As well as, bidirectional consideration is used to beat the contextual constraints imposed by unidirectional consideration utilized by causal LLMs. It permits tokens to totally make the most of their context on each side. A number of experimental experiments confirmed that max-pooling works one of the best amongst pooling methods for phrase embeddings. Lastly, LENS is used together with dense embeddings. The hybrid embedding makes use of one of the best options of the 2 approaches. Therefore, it performs higher over a variety of duties. These enhancements make LENS a flexible and environment friendly framework for producing interpretable and contextually-aware embeddings that can be utilized for clustering, classification, and retrieval purposes.
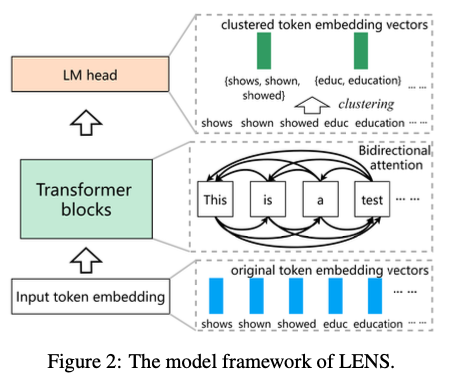
LENS makes use of clustering to switch the unique token embeddings with cluster centroids within the language modeling head, eradicating redundancy and the dimensionality of the embedding. The embeddings are then 4,000 or 8,000 dimensional and as environment friendly and scalable as dense embeddings. Within the fine-tuning stage, the mannequin incorporates bidirectional consideration that improves contextual understanding since tokens could make knowledgeable choices based mostly on their full context. The framework is predicated on the Mistral-7B mannequin; the datasets are public and embrace duties corresponding to retrieval, clustering, classification, and semantic textual similarity. The coaching methodology is optimized utilizing a streamlined single-stage pipeline and InfoNCE loss for enhancing embeddings. This technique ensures ease of use, the power to scale, and robust efficiency on duties, thereby rendering the framework appropriate for a spread of purposes.
LENS displays exceptional efficacy throughout numerous benchmarks, such because the Large Textual content Embedding Benchmark (MTEB) and AIR-Bench. Inside the MTEB framework, LENS-8000 attains the very best imply rating amongst fashions educated publicly, outpacing dense embeddings in six of seven process classifications. The extra compact LENS-4000 mannequin additionally demonstrates aggressive efficiency, highlighting its scalability and effectivity. With dense embeddings, LENS reveals robust benefits, establishing new baselines in retrieval duties and uniformly offering enhancements over a spread of datasets. Qualitative evaluations reveal that LENS flawlessly achieves semantic associations, reduces noise in tokenization, and yields very compact and informative embeddings. The stable generalization capabilities of the framework and aggressive efficiency in out-of-domain duties additional set up its versatility and applicability for all kinds of duties.
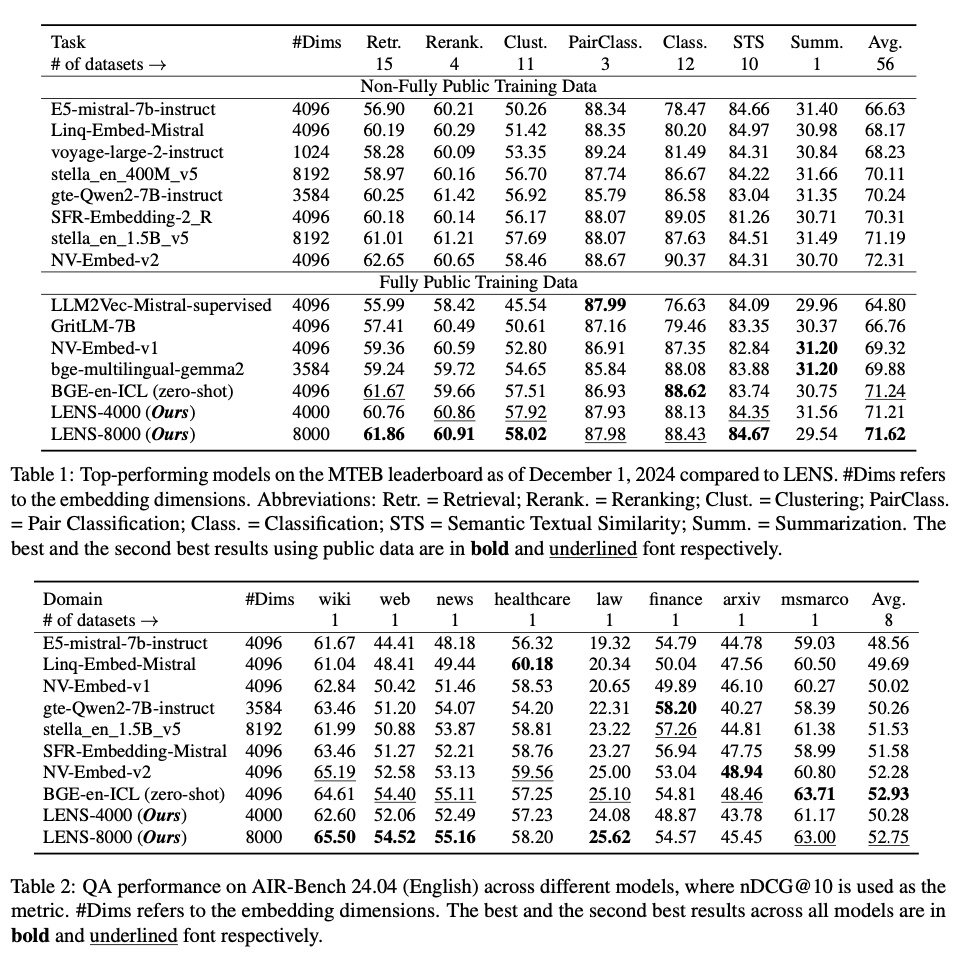
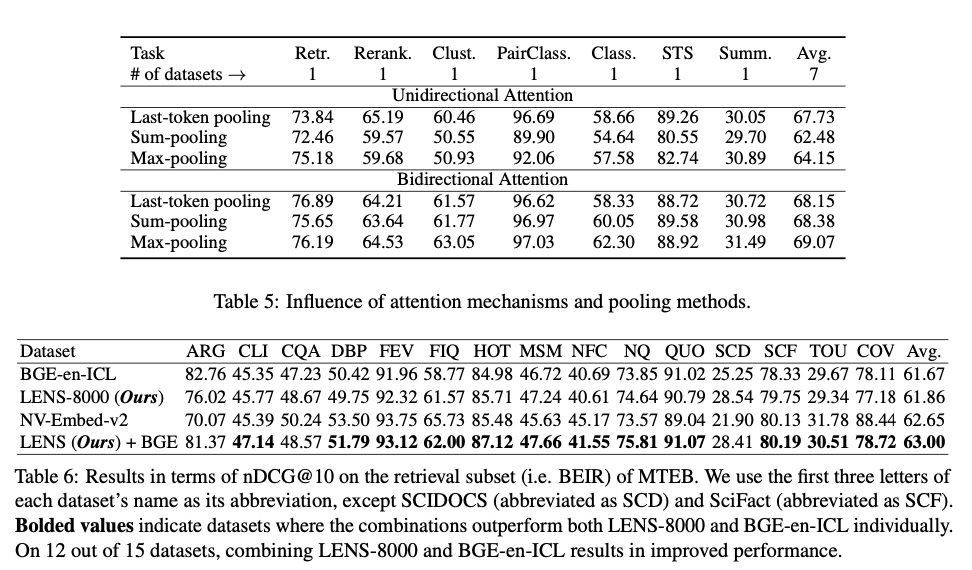
LENS is an thrilling step ahead for lexicon-based embedding fashions as a result of they handle tokenization redundancy whereas being simpler than different approaches that enhance contextual representations by bidirectional consideration mechanisms. The compactness, effectivity, and interpretability of the mannequin are seen throughout a large spectrum of duties: from retrieval to clustering and classification duties, which reveal superior efficiency in opposition to conventional approaches. Furthermore, this effectiveness in dense environments factors in direction of its revolutionary risk in textual content illustration. Future research could prolong this research by including multi-lingual datasets and greater fashions to reinforce its significance and relevance inside the area of synthetic intelligence.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 65k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.