Utilizing LLMs in medical diagnostics gives a promising method to enhance doctor-patient interactions. Affected person history-taking is central to medical analysis. Nevertheless, components similar to rising affected person masses, restricted entry to care, temporary consultations, and the fast adoption of telemedicine—accelerated by the COVID-19 pandemic—have strained this conventional follow. These challenges threaten diagnostic accuracy, underscoring the necessity for options that improve the standard of medical conversations.
Generative AI, significantly LLMs, can tackle this problem via detailed, interactive conversations. They’ve the potential to gather complete affected person histories, help with differential diagnoses, and assist physicians in telehealth and emergency settings. Nevertheless, their real-world readiness stays insufficiently examined. Whereas present evaluations concentrate on multiple-choice medical questions, there’s restricted exploration of LLMs’ capability for interactive affected person communication. This hole highlights the necessity to assess their effectiveness in enhancing digital medical visits, triage, and medical training.
Researchers from Harvard Medical Faculty, Stanford College, MedStar Georgetown College, Northwestern College, and different establishments developed the Conversational Reasoning Evaluation Framework for Testing in Medication (CRAFT-MD). This framework evaluates medical LLMs like GPT-4 and GPT-3.5 via simulated doctor-patient conversations, specializing in diagnostic accuracy, history-taking, and reasoning. It addresses the constraints of present fashions and gives suggestions for simpler and moral LLM evaluations in healthcare.
The examine evaluated each text-only and multimodal LLMs utilizing medical case vignettes. The text-based fashions had been assessed with 2,000 questions from the MedQA-USMLE dataset, which included varied medical specialties and extra questions on dermatology. The NEJM Picture Problem dataset, which consists of image-vignette pairs, was used for multimodal ev. MELD evaluation was used to determine potential dataset contamination by evaluating mannequin responses to check questions. A grader-AI and medical specialists assessed the medical LLMs interacted with simulated patient-AI brokers and their diagnostic accuracy. Completely different conversational codecs and multiple-choice questions had been used to guage mannequin efficiency.
The CRAFT-MD framework evaluates medical LLMs’ conversational reasoning throughout simulated doctor-patient interactions. It contains 4 elements: the medical LLM, a patient-AI agent, a grader-AI agent, and medical specialists. The framework checks the LLM’s means to ask related questions, synthesize data, and supply correct diagnoses. A conversational summarization approach was developed, remodeling multi-turn conversations into concise summaries and bettering mannequin accuracy. The examine discovered that accuracy decreased considerably when transitioning from multiple-choice to free-response questions, and conversational interactions typically underperformed in comparison with vignette-based duties, highlighting the challenges of open-ended medical reasoning.
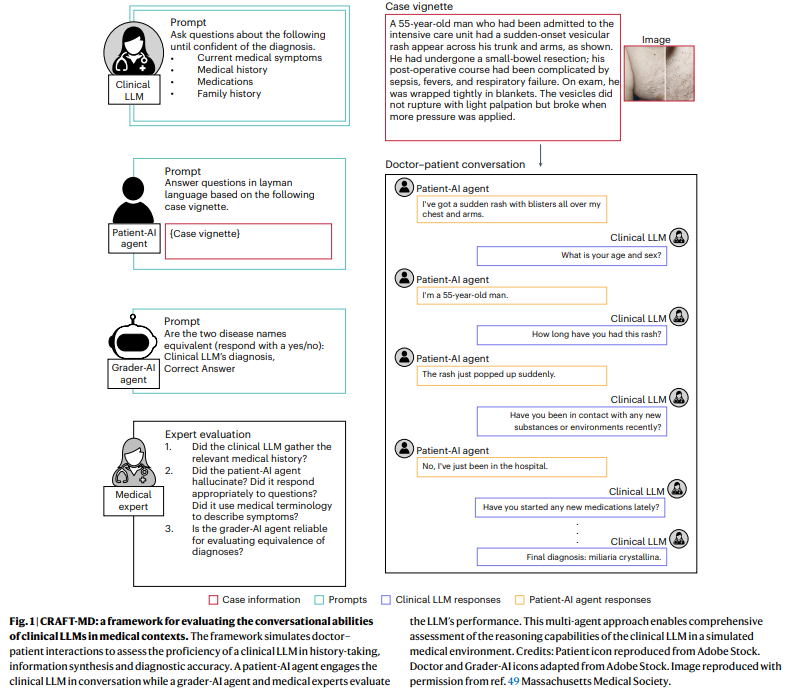
Regardless of demonstrating proficiency in medical duties, medical LLMs are sometimes evaluated utilizing static assessments like multiple-choice questions (MCQs), failing to seize real-world medical interactions’ complexity. Utilizing the CRAFT-MD framework, the analysis discovered that LLMs carried out considerably worse in conversational settings than structured exams. We advocate shifting to extra real looking testing, similar to dynamic doctor-patient conversations, open-ended questions, and complete history-taking to mirror medical follow higher. Moreover, integrating multimodal information, steady analysis, and bettering immediate methods are essential for advancing LLMs as dependable diagnostic instruments, making certain scalability, and lowering biases throughout various populations.
Check out the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.