LLMs have demonstrated distinctive efficiency throughout a number of duties by using few-shot inference, also called in-context studying (ICL). The primary downside lies in choosing essentially the most consultant demonstrations from massive coaching datasets. Early strategies chosen demonstrations based mostly on relevance utilizing similarity scores between every instance and the enter query. Present strategies counsel utilizing extra choice guidelines, together with similarity, to reinforce the effectivity of demonstration choice. These enhancements introduce vital computational overhead when the variety of photographs will increase. The effectiveness of chosen demonstrations also needs to think about the precise LLM in use, as completely different LLMs exhibit various capabilities and information domains.
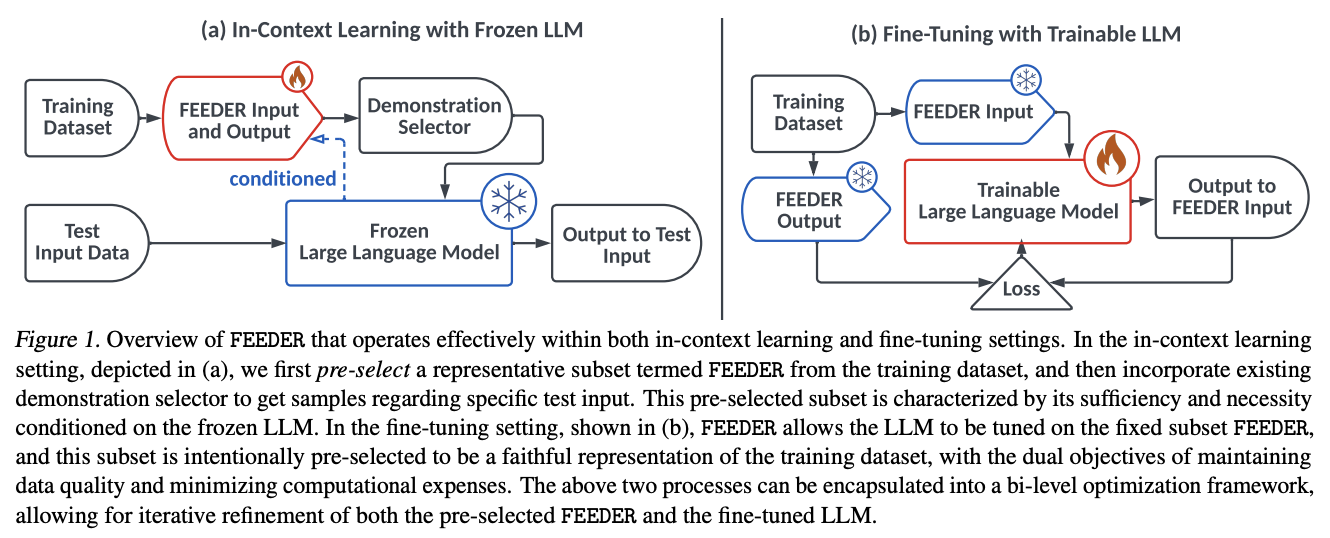
Researchers from Shanghai Jiao Tong College, Xiaohongshu Inc., Carnegie Mellon College, Peking College, No Affiliation, College Faculty London, and College of Bristol have proposed FEEDER (FEw but Important Demonstration prE-selectoR), a way to establish a core subset of demonstrations containing essentially the most consultant examples in coaching information, adjusted to particular LLMs. To assemble this subset, “sufficiency” and “necessity” metrics are launched within the pre-selection stage, together with a tree-based algorithm. Furthermore, FEEDER reduces coaching information dimension by 20% whereas sustaining efficiency and seamlessly integrating with numerous downstream demonstration choice methods in ICL throughout LLMs starting from 300M to 8B parameters.
FEEDER is evaluated on 6 textual content classification datasets: SST-2, SST-5, COLA, TREC, SUBJ, and FPB, overlaying duties from sentiment classification and linguistic evaluation to textual entailment. It is usually evaluated on the reasoning dataset GSM8K, the semantic-parsing dataset SMCALFlow, and the scientific question-answering dataset GPQA. The official splits for every dataset are straight adopted to get the coaching and check information. Furthermore, a number of LLM variants are utilized to judge the efficiency of the tactic, together with two GPT-2 variants, GPT-neo with 1.3B parameters, GPT-3 with 6B parameters, Gemma-2 with 2B parameters, Llama-2 with 7B parameters, Llama-3 with 8B parameters, and Qwen-2.5 with 32B parameters because the LLM base.
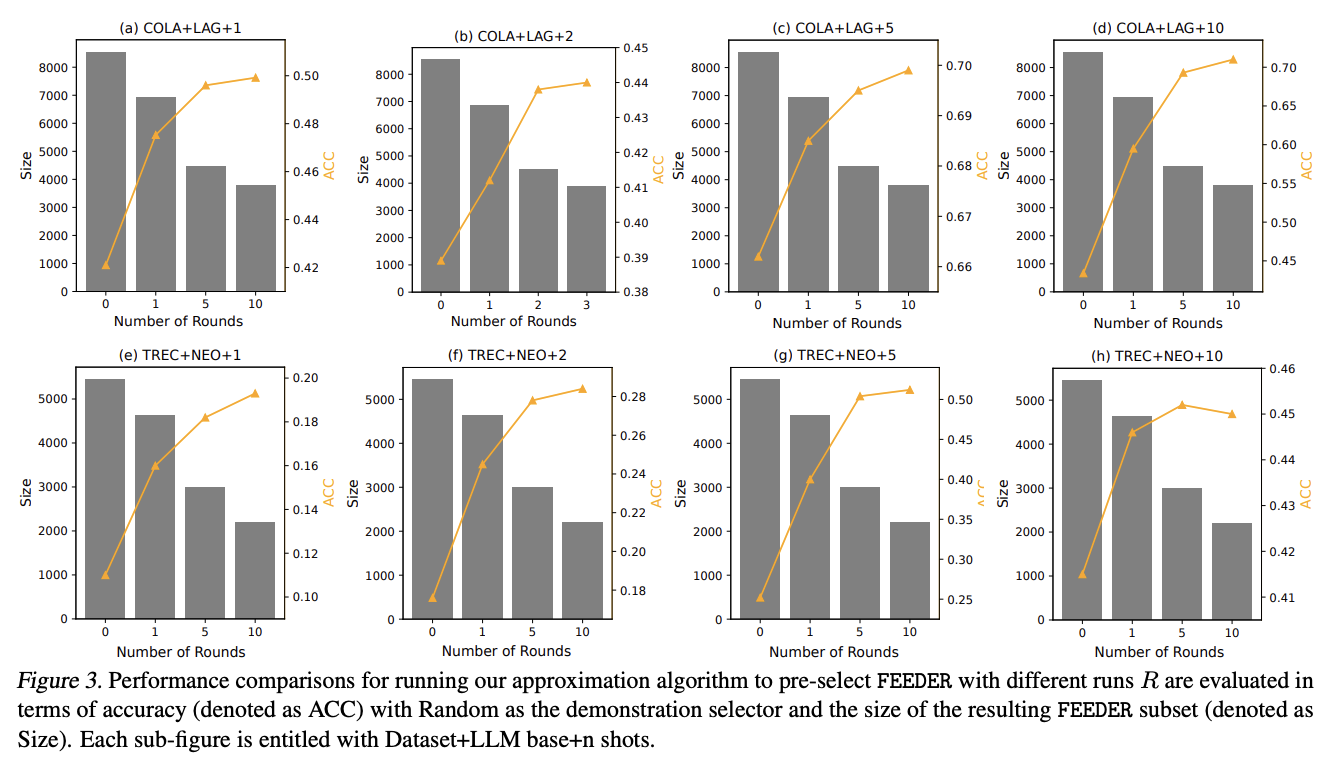
Outcomes relating to in-context studying efficiency present that FEEDER permits retention of just about half the coaching samples whereas reaching superior or comparable efficiency. Analysis of few-shot efficiency on complicated duties utilizing LLMs like Gemma-2 exhibits that FEEDER improves efficiency even when LLMs battle with difficult duties. It performs successfully with massive numbers of photographs, dealing with conditions the place LLM efficiency often drops when the variety of examples will increase from 5 to 10 attributable to noisy or repeated demonstrations. Furthermore, FEEDER minimizes unfavourable influence on LLM efficiency by evaluating the sufficiency and necessity of every demonstration, and helps within the efficiency stability of LLMs
On bi-level optimization, FEEDER achieves improved efficiency by using a small but high-quality dataset for fine-tuning whereas concurrently lowering computational bills, aligning with the core-set choice precept. Outcomes point out that fine-tuning LLMs supplies better efficiency enhancements in comparison with augmenting LLMs with contexts, with FEEDER reaching even higher efficiency beneficial properties in fine-tuning settings. Efficiency evaluation reveals that FEEDER’s effectiveness first rises after which drops with rising variety of runs or rounds (R and Ok, respectively), confirming that figuring out consultant subsets from coaching datasets enhances LLM efficiency. Nonetheless, overly slim subsets could restrict potential efficiency beneficial properties.
In conclusion, researchers launched FEEDER, an indication pre-selector designed to make use of LLM capabilities and area information to establish high-quality demonstrations via an environment friendly discovery strategy. It reduces coaching information necessities whereas sustaining comparable efficiency, providing a sensible answer for environment friendly LLM deployment. Future analysis instructions embody exploring purposes with bigger LLMs and lengthening FEEDER’s capabilities to areas corresponding to information security and information administration. FEEDER makes a beneficial contribution to demonstration choice, offering researchers and practitioners with an efficient device for optimizing LLM efficiency whereas lowering computational overhead.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge.
Meet the AI Dev E-newsletter learn by 40k+ Devs and Researchers from NVIDIA, OpenAI, DeepMind, Meta, Microsoft, JP Morgan Chase, Amgen, Aflac, Wells Fargo and 100s extra [SUBSCRIBE NOW]

Sajjad Ansari is a remaining 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.