In right now’s world, Graph similarity computation (GSC) performs an vital position in varied functions corresponding to code detection, molecular graph similarity, picture matching, and many others., by evaluating the similarity between two graphs, and it’s based mostly on Graph similarity studying. Graph Edit Distance (GED) and Most Frequent Subgraph (MCS) are broadly used to measure graph similarity. GED refers back to the minimal variety of operations that convert one graph to the opposite, and MCS is the most important subgraph that’s concurrently isomorphic(structurally similar) to each graphs. Nonetheless, calculating GED and MCS is troublesome due to issues that belong to a class referred to as NP-complete, which means they’re extraordinarily arduous to unravel effectively, particularly because the graphs get bigger. Conventional algorithms like Hungar and A* can compute GED precisely however at the price of excessive computational complexity. Computing graph similarity scores precisely is vital, as this could considerably influence its functions.
The prevailing strategies to compute graph similarity have two main drawbacks:
1. Illustration limitation: A complete illustration permits matching from a number of views. Most strategies solely use easy node embeddings with out highlighting the sting illustration, which is essential for precisely evaluating buildings.
2. Matching inadequacy: Some latest GSC strategies use Graph neural networks (GNNs) to benefit from intra-graph buildings in message passing. Nonetheless, most of them want to totally make the most of the data introduced by edges to spice up the illustration of the related nodes. Furthermore, earlier cross-graph node embedding matching wants to incorporate the larger image of the general construction of the graph pair as a result of the node representations from GNNs solely give attention to the intra-graph construction, inflicting an unreasonable similarity rating.
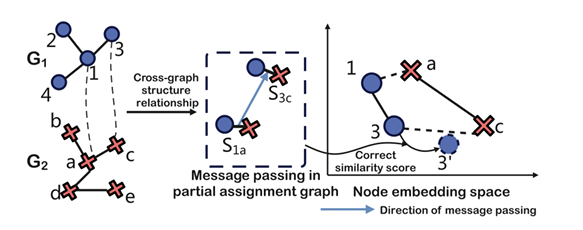
To beat the drawbacks of earlier works, researchers from Nanjing College of Posts and Telecommunications proposed a Construction Enhanced Graph Matching Community (SEGMN) framework. Geared up with a twin embedding studying module and a construction notion matching module, SEGMN achieves construction enhancement in each embedding studying and cross-graph matching. This proposed framework consists of 4 modules: Twin embedding studying, Cross-graph interplay, Construction notion matching, and Similarity matrix studying.
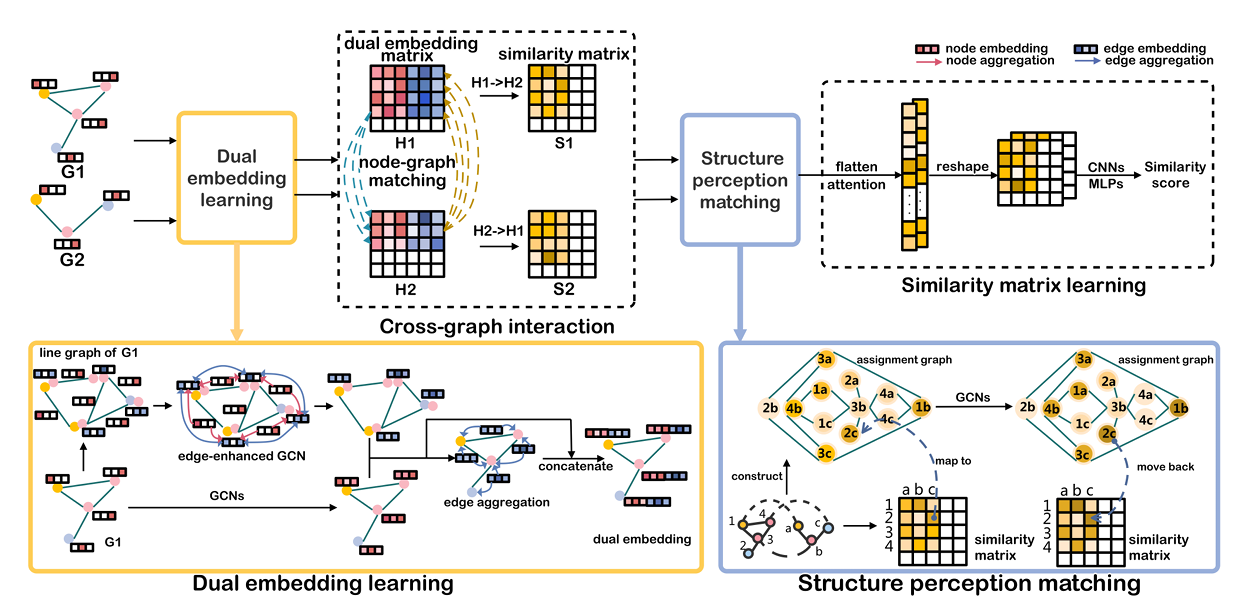
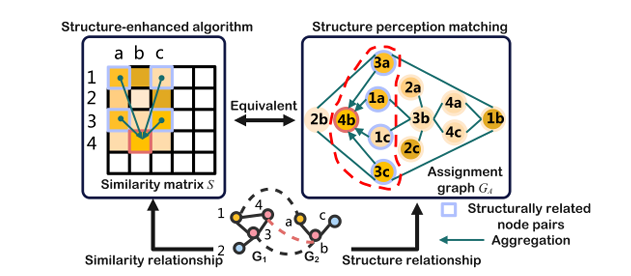
The twin embedding studying module will be divided into three steps. An edge-enhanced GCN is utilized to the road graph for edge embedding. Secondly, a GCN with residual connections is utilized to the node graph for embedding. Thirdly, every node aggregates the related edge embeddings to generate the final word twin embedding. This twin embedding is used for cross-graph matching on the node stage, the place node-graph consideration is adopted to calculate every node pair’s similarity rating. The construction notion matching improves these scores by contemplating the structural relationships between node pairs throughout graphs. Lastly, the similarity matrix is refined utilizing convolution and self-attention to provide correct similarity scores, with a loss perform based mostly on Imply Squared Error to optimize the mannequin’s predictions.
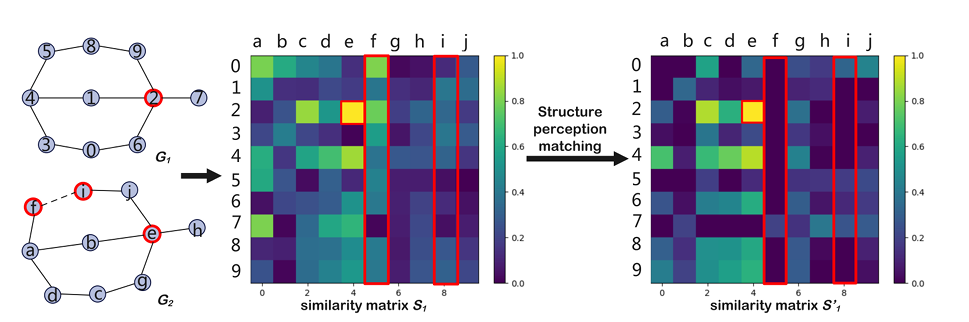
Researchers evaluated SEGMN utilizing three benchmark real-world datasets: AIDS, LINUX, and IMDB, and in contrast it to different teams of baselines corresponding to GCN, GIN, GAT, SimGNN, and GraphSim. Upon analysis, the proposed technique outperformed different fashions when it comes to Imply Sq. Error (MSE), Spearman’s Rank Correlation (ρ), Kendall’s Tau (τ), and precision at high 10 (p@10), with the construction notion matching module additional enhancing efficiency by as much as 25%.
In conclusion, the proposed framework is predicated on a twin embedding studying module and a structure-matching notion module, which carry out higher than conventional strategies and mitigate their points. It additionally provides a strong resolution for graph similarity computation by offering a robust method to calculate it extra precisely. This analysis marks an important step towards understanding graph similarity computation and might function a baseline for future analysis on this area!
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and clear up challenges.