Transformer-based language fashions course of textual content by analyzing phrase relationships moderately than studying so as. They use consideration mechanisms to give attention to key phrases, however dealing with longer textual content is difficult. The Softmax operate, which distributes consideration, weakens because the enter dimension grows, inflicting consideration fading. This reduces the mannequin’s give attention to vital phrases, making it tougher to study from lengthy texts. As the eye values get smaller, the small print develop into unclear, thus rendering the mannequin ineffective for bigger inputs. Until there’s a modification within the consideration mechanism, the mannequin doesn’t give attention to important data and, subsequently, fails to work properly on bigger textual content inputs.
Present strategies to enhance size generalization in Transformer-based fashions embody positional encoding, sparse consideration, prolonged coaching on longer texts, and enhanced consideration mechanisms. These strategies are usually not scalable and require a whole lot of computational sources, making them inefficient for dealing with lengthy inputs. The Softmax operate, used within the case of consideration distribution in Transformers, degrades because the enter dimension grows. For extra tokens, Softmax generates extra flat distributions of chances that result in lowering the emphasis on key phrases. Such a phenomenon is named consideration fading, severely limiting the mannequin’s means to course of lengthy textual content.
To mitigate consideration fading in Transformers, a researcher from The College of Tokyo proposed Scalable-Softmax (SSMax), which modifies the Softmax operate to keep up consideration on vital tokens even when the enter dimension will increase. Not like Softmax, which causes consideration to unfold thinly because the enter grows, SSMax adjusts the scaling issue based mostly on the enter dimension, guaranteeing that the very best worth stays dominant. This avoids lack of give attention to key data in bigger contexts. This framework incorporates a scaling issue that entails the scale of the enter, which alters the method for calculating consideration through the use of a logarithm. The mannequin dynamically adapts to focus on related parts when variations apply and distributes consideration when related values are used. SSMax integrates simply into present architectures with minimal modifications, requiring solely a easy multiplication within the consideration computation.
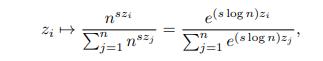
To guage the affect of changing Softmax with Scalable-Softmax (SSMax) in consideration layers, the researcher performed experiments on coaching effectivity, long-context generalization, key data retrieval, and a focus allocation. They examined six configurations, together with customary Softmax, SSMax with and with out a scaling parameter, SSMax with a bias parameter, and two fashions the place Softmax was changed with SSMax after or throughout pretraining. SSMax persistently improved coaching effectivity and long-context generalization, lowering take a look at loss throughout prolonged sequence lengths. The Needle-In-A-Haystack take a look at revealed that SSMax considerably enhanced key data retrieval in lengthy contexts. Nevertheless, eradicating the scaling parameter or including a bias degraded efficiency. Fashions the place Softmax was changed with SSMax post-training or late in pretraining, confirmed partial enhancements however did not match absolutely educated SSMax fashions.
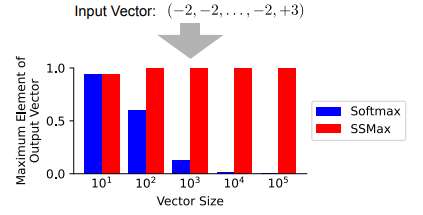
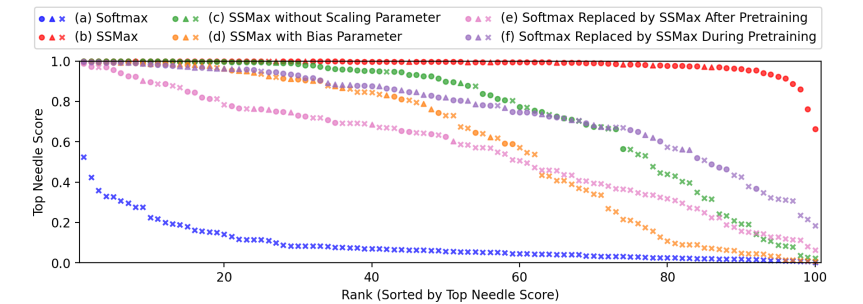
In abstract, this proposed methodology improved transformer consideration, which defeats consideration fading and strengthens size generalization, making fashions simpler in long-context duties. Its adaptability benefited newly educated and present fashions, positioning it as a robust different to Softmax. The long run can optimize SSMax for effectivity and combine it into rising Transformer fashions to boost long-context understanding in real-world purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 75k+ ML SubReddit.
🚨 Marktechpost is inviting AI Corporations/Startups/Teams to accomplice for its upcoming AI Magazines on ‘Open Supply AI in Manufacturing’ and ‘Agentic AI’.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and remedy challenges.