Operate calling has emerged as a transformative functionality in AI programs, enabling language fashions to work together with exterior instruments by means of structured JSON object era. Nonetheless, present methodologies face essential challenges in comprehensively simulating real-world interplay eventualities. Current approaches predominantly concentrate on producing tool-specific name messages, overlooking the nuanced necessities of human-AI conversational interactions. The complexity of tool-use dialogs extends past mere mechanical operate invocation, demanding a extra holistic strategy that seamlessly navigates software interactions and person communication. Thus, there’s a want for extra complicated and adaptive function-calling frameworks that bridge the hole between technical precision and pure conversational dynamics.
Latest research have more and more targeted on exploring how language fashions make the most of instruments, resulting in the event of varied benchmarks for evaluating their capabilities. Distinguished analysis frameworks like APIBench, GPT4Tools, RestGPT, and ToolBench have targeting growing systematic evaluation methodologies for software utilization. Current revolutionary approaches like MetaTool examine software utilization consciousness, whereas BFCL introduces operate relevance detection. Regardless of these developments, present methodologies predominantly concentrate on producing software call-type outputs, which don’t immediately work together with customers. This slender analysis strategy reveals a essential hole in comprehensively measuring language fashions’ interactive capabilities.
Researchers from Kakao Corp. / Sungnam, South Korea have proposed FunctionChat-Bench, a way to guage language fashions’ operate calling capabilities throughout numerous interplay eventualities. This methodology addresses the essential limitations in present analysis methodologies by introducing a strong dataset comprising 700 evaluation gadgets and automatic analysis packages. Furthermore, FunctionChat-Bench examines language fashions’ efficiency throughout single-turn and multi-turn dialogue contexts specializing in function-calling capabilities. It critically challenges the belief that prime efficiency in remoted software name eventualities immediately correlates with general interactive proficiency.
The FunctionChat-Bench benchmark introduces a fancy two-subset analysis framework to guage the operate calling capabilities of language fashions, (a) Single name dataset and (b) Dialog dataset. The next circumstances outline analysis gadgets within the Single name dataset:
- The person’s single-turn utterance should comprise all the required data for operate invocation, main on to a software name.
- An appropriate operate for finishing up the person’s request should be given within the accessible software listing.
In distinction, the Dialog dataset simulates extra complicated real-world interplay eventualities, difficult language fashions to navigate numerous enter contexts. Key analysis standards for the proposed methodology embrace the mannequin’s capability to speak software invocation outcomes, request lacking data when obligatory, and deal with person interactions.
Experimental outcomes from the FunctionChat-Bench reveal detailed insights into language fashions’ operate calling efficiency throughout completely different eventualities. The accuracy of fashions didn’t persistently lower by rising the variety of operate candidates between 1 and eight candidates. Notably, the Gemini mannequin demonstrates improved accuracy because the variety of operate candidates will increase. GPT-4-turbo reveals a considerable 10-point accuracy distinction between random and shut operate sort eventualities. Furthermore, the dialog dataset supplies software name generations, conversational outputs, slot-filling questions, and gear name relevance detection throughout multi-turn discourse interactions.
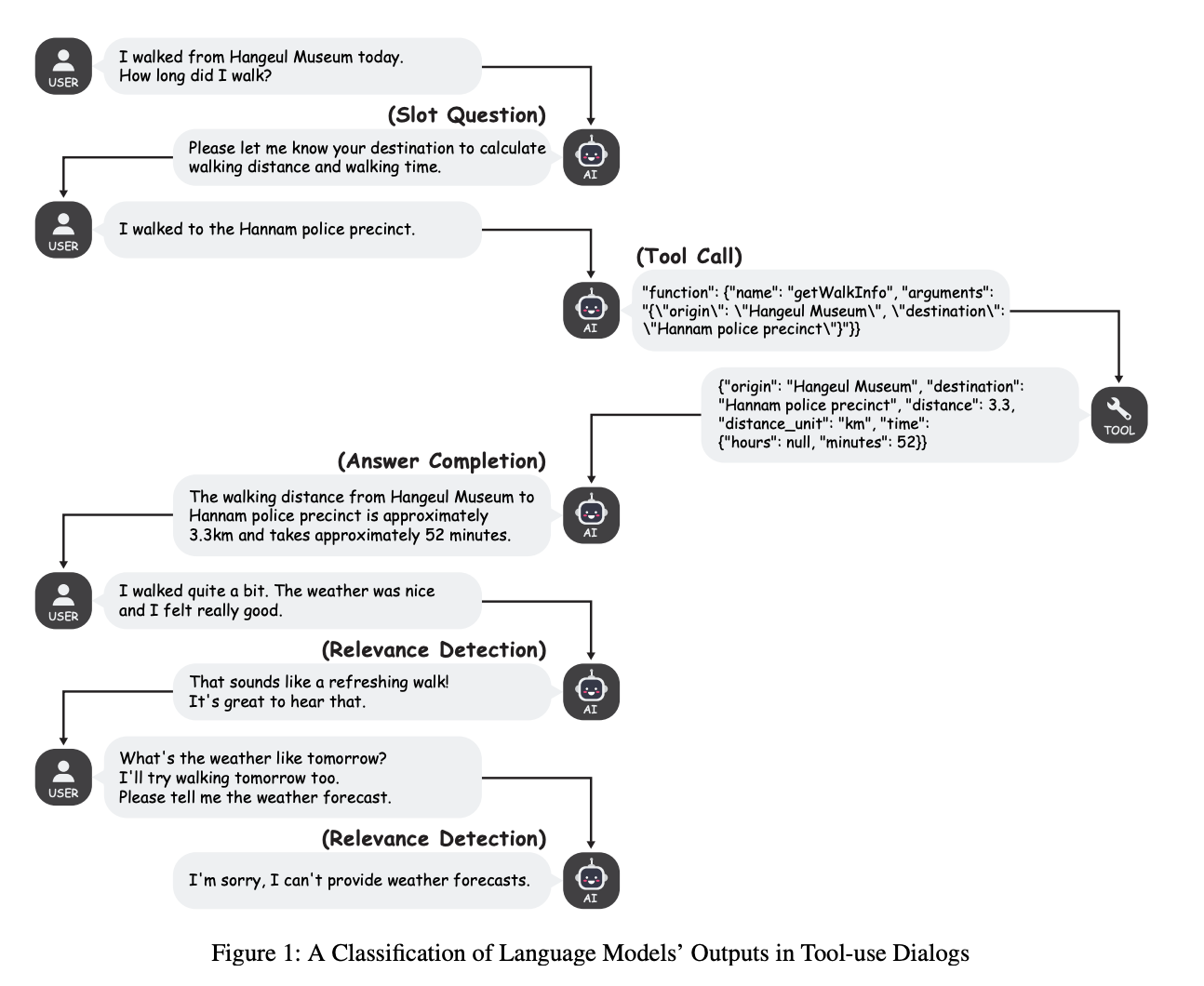
On this paper, researchers launched FunctionChat-Bench, a benchmark that comprehensively evaluates language fashions’ function-calling capabilities, extending past conventional evaluation methodologies. They supply detailed insights into language fashions’ generative efficiency by growing a novel dataset with Single name and Dialog subsets, and an automatic analysis program. Using a sophisticated LLM as an analysis decide with refined rubrics, FunctionChat-Bench gives a fancy framework for evaluating operate calling proficiency. Nonetheless, this benchmark has limitations whereas evaluating superior operate calling purposes. The examine units a basis for future analysis, highlighting the complexity of interactive AI programs.
Take a look at the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.