In real-world settings, brokers typically face restricted visibility of the setting, complicating decision-making. For example, a car-driving agent should recall highway indicators from moments earlier to regulate its velocity, but storing all observations is unscalable on account of reminiscence limits. As a substitute, brokers should be taught compressed representations of observations. This problem is compounded in ongoing duties, the place important previous data can solely generally be retained effectively. Incremental state building is vital in partially observable on-line reinforcement studying (RL), the place recurrent neural networks (RNNs) like LSTMs deal with sequences successfully, although they’re powerful to coach. Transformers seize long-term dependencies however include larger computational prices.
Numerous approaches have prolonged linear transformers to deal with their limitations in dealing with sequential information. One structure makes use of a scalar gating technique to build up values over time, whereas others add recurrence and non-linear updates to reinforce studying from sequential dependencies, though this could cut back parallelization effectivity. Moreover, some fashions selectively calculate sparse consideration or cache earlier activations, permitting them to take care of longer sequences with out important reminiscence value. Different latest improvements cut back the complexity of self-attention, bettering transformers’ capability to course of lengthy contexts effectively. Although transformers are generally utilized in offline reinforcement studying, their utility in model-free settings remains to be rising.
Researchers from the College of Alberta and Amii developed two new transformer architectures tailor-made for partially observable on-line reinforcement studying, addressing points with excessive inference prices and reminiscence calls for typical of conventional transformers. Their proposed fashions, GaLiTe and AGaLiTe, implement a gated self-attention mechanism to handle and replace data effectively, offering a context-independent inference value and improved efficiency in long-range dependencies. Testing in 2D and 3D environments, like T-Maze and Craftax, confirmed these fashions outperformed or matched the state-of-the-art GTrXL, decreasing reminiscence and computation by over 40%, with AGaLiTe reaching as much as 37% higher efficiency on advanced duties.
The Gated Linear Transformer (GaLiTe) enhances linear transformers by addressing key limitations, notably the dearth of mechanisms to take away outdated data and the reliance on the kernel function map alternative. GaLiTe introduces a gating mechanism to regulate data circulate, permitting selective reminiscence retention and a parameterized function map to compute key and question vectors without having particular kernel capabilities. For additional effectivity, the Approximate Gated Linear Transformer (AGaLiTe) makes use of a low-rank approximation to scale back reminiscence calls for, storing recurrent states as vectors moderately than matrices. This method achieves important area and time financial savings in comparison with different architectures, particularly in advanced reinforcement studying duties.
The examine evaluates the proposed AGaLiTe mannequin throughout a number of partially observable RL duties. In these environments, brokers require reminiscence to deal with completely different ranges of partial observability, equivalent to recalling single cues in T-Maze, integrating data over time in CartPole, or navigating by means of advanced environments like Thriller Path, Craftax, and Reminiscence Maze. AGaLiTe, outfitted with a streamlined self-attention mechanism, achieves excessive efficiency, surpassing conventional fashions like GTrXL and GRU in effectiveness and computational effectivity. The outcomes point out that AGaLiTe’s design considerably reduces operations and reminiscence utilization, providing benefits for RL duties with intensive context necessities.
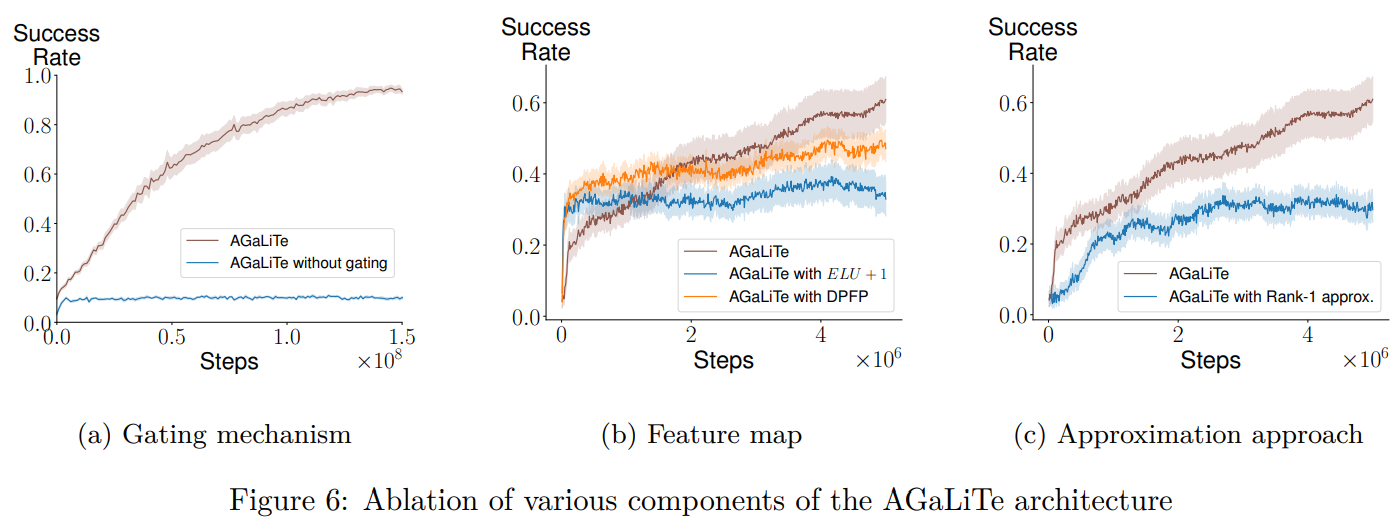
In conclusion, Transformers are extremely efficient for sequential information processing however face limitations in on-line reinforcement studying on account of excessive computational calls for and the necessity to keep all historic information for self-attention. This examine introduces two environment friendly alternate options to transformer self-attention, GaLiTe, and AGaLiTe, that are recurrent-based and designed for partially observable RL duties. Each fashions carry out competitively or higher than GTrXL, with over 40% decrease inference prices and over 50% diminished reminiscence utilization. Future analysis might enhance AGaLiTe with real-time studying updates and functions in model-based RL approaches like Dreamer V3.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.