Mannequin effectivity is vital within the age of enormous language and imaginative and prescient fashions, however they face vital effectivity challenges in real-world deployments. Important metrics akin to coaching compute necessities, inference latency, and reminiscence footprint impression deployment prices and system responsiveness. These constraints usually restrict the sensible implementation of high-quality fashions in manufacturing environments. The necessity for environment friendly deep studying strategies has turn out to be vital, specializing in optimizing the trade-off between mannequin high quality and useful resource footprint. Whereas varied approaches together with algorithmic methods, environment friendly {hardware} options, and greatest practices have emerged, architectural enhancements stay elementary to effectivity positive aspects.
A number of approaches have emerged to deal with mannequin effectivity challenges, every with distinct focuses and limitations. Current strategies like LoRA introduce low-rank adapter weights throughout fine-tuning whereas conserving different weights fixed, and AltUp creates parallel light-weight transformer blocks to simulate bigger mannequin dimensions. Different strategies like compression methods, embrace quantization and pruning to scale back mannequin measurement and latency however can impression mannequin high quality. Information distillation methods switch information from bigger trainer fashions to smaller scholar fashions, and progressive studying approaches like Stacking and RaPTr develop networks steadily. Nonetheless, these strategies contain advanced coaching or trade-offs between effectivity and efficiency.
Researchers from Google Analysis, Mountain View, CA, and Google Analysis, New York, NY have proposed a novel technique known as Discovered Augmented Residual Layer (LAUREL), which revolutionizes the normal residual connection idea in neural networks. It serves as a direct alternative for standard residual connections whereas enhancing each mannequin high quality and effectivity metrics. LAUREL exhibits outstanding versatility, with vital enhancements throughout imaginative and prescient and language fashions. When carried out in ResNet-50 for ImageNet 1K classification, LAUREL achieves 60% of the efficiency positive aspects related to including a whole further layer, with solely 0.003% further parameters. This effectivity interprets to matching full-layer efficiency with 2.6 occasions fewer parameters.
LAUREL’s implementation is examined in each imaginative and prescient and language domains, specializing in the ResNet-50 mannequin for ImageNet-1K classification and a 3B parameter decoder-only transformer for language duties. The structure seamlessly integrates with current residual connections, requiring minimal modifications to straightforward mannequin architectures. For imaginative and prescient duties, the implementation entails incorporating LAUREL into ResNet-50’s skip connections and coaching on ImageNet 1K utilizing 16 Cloud TPUv5e chips with information augmentation. Within the language area, two variants of LAUREL (LAUREL-RW and LAUREL-LR) are carried out in a 3B parameter transformer mannequin and educated from scratch on textual content tokens utilizing 1024 Cloud TPU v5e chips over two weeks.
The outcomes exhibit LAUREL’s superior effectivity in comparison with conventional scaling strategies. In imaginative and prescient duties, including an additional layer to ResNet-50 enhances accuracy by 0.25% with 4.37% extra parameters, however LAUREL-RW achieves 0.15% enchancment with simply 0.003% parameter improve. The LAUREL-RW+LR variant matches the efficiency of the extra-layer strategy whereas utilizing 2.6 occasions fewer parameters, and LAUREL-RW+LR+PA outperforms it with 1.82 occasions fewer parameters. Furthermore, in language fashions, LAUREL exhibits constant enhancements throughout duties together with Q&A, NLU, Math, and Code with solely a 0.012% parameter improve. This minimal parameter addition makes LAUREL environment friendly for large-scale fashions.
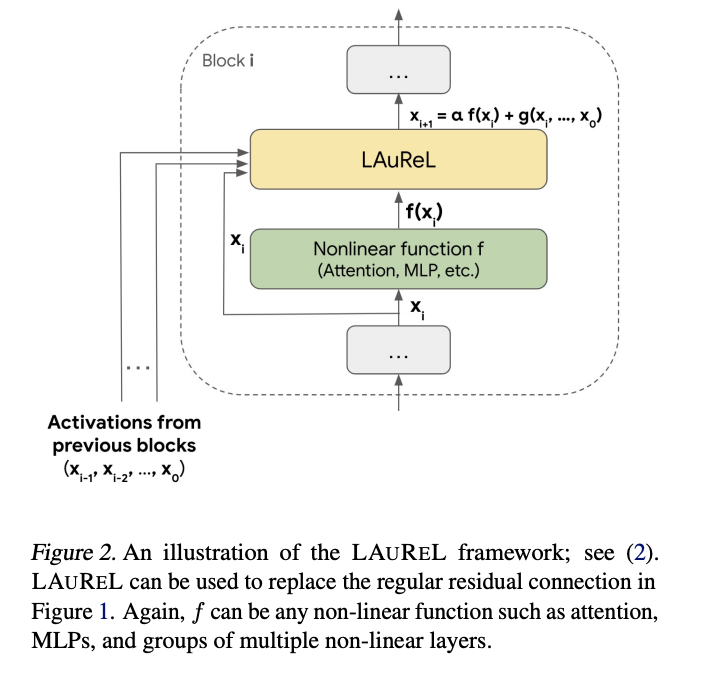
In conclusion, researchers launched the LAUREL framework which represents a major development in neural community structure, providing a posh various to conventional residual connections. Its three variants – LAUREL-RW, LAUREL-LR, and LAUREL-PA – might be flexibly mixed to optimize efficiency throughout completely different purposes. The framework’s success in each imaginative and prescient and language duties, together with its minimal parameter overhead exhibits its potential as a superior various to standard mannequin scaling approaches. The flexibility and effectivity of LAUREL make it a promising candidate for future purposes in different architectures like Imaginative and prescient Transformers (ViT).
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production

Sajjad Ansari is a last yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.