Spatial-temporal information dealing with entails the evaluation of knowledge gathered over time and area, typically by means of sensors. Such information is essential in sample discovery and prediction. Nonetheless, lacking values pose an issue and make it difficult to investigate. Such gaps might typically create inconsistencies with the dataset, inflicting more durable evaluation. The relationships between options, like environmental or bodily components, may be complicated and influenced by a geographic context. Precisely capturing these relationships is important however stays difficult attributable to various function correlations and limitations in current strategies, which battle to handle these complexities successfully.
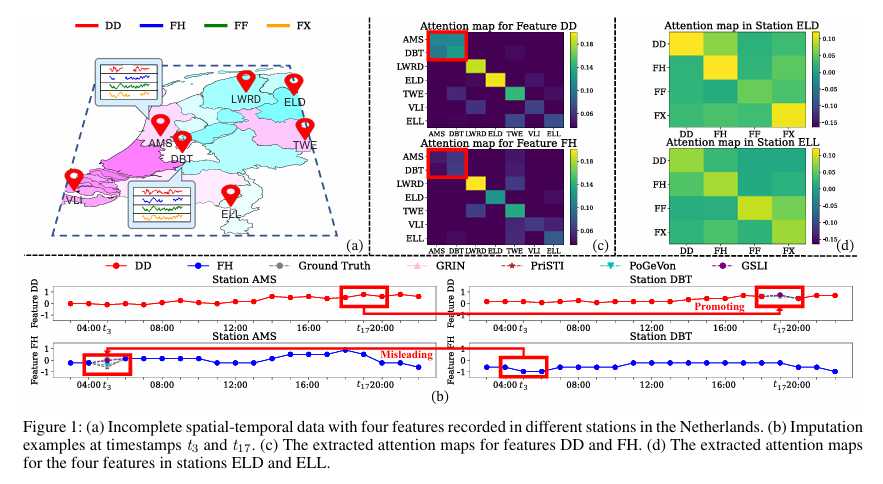
Present strategies for addressing lacking values in spatial-temporal information depend on mounted spatial graphs and graph neural networks (GNNs) to seize spatial dependencies. These approaches assume that the spatial relationships between options are uniform throughout completely different areas. These approaches don’t contemplate that options recorded by sensors typically bear completely different relationships relative to their respective locations and contexts. Subsequently, these approaches don’t correctly handle and symbolize the completely different complicated spatial relations of assorted traits, leading to incorrect estimations about information-missing issues and the mixing of detailed temporal and spatial interconnections.
To deal with spatial-temporal imputation challenges, researchers from Nankai College and Harbin Institute of Expertise, Shenzhen, China, proposed the multi-scale Graph Construction Studying framework (GSLI). This framework adapts to spatial correlations by combining two approaches: node-scale studying and feature-scale studying. Node-scale studying focuses on world spatial dependencies for particular person options, whereas feature-scale studying uncovers spatial relations amongst options inside a node. Not like standard strategies counting on static buildings, this framework targets function heterogeneity and integrates spatial-temporal correlations.
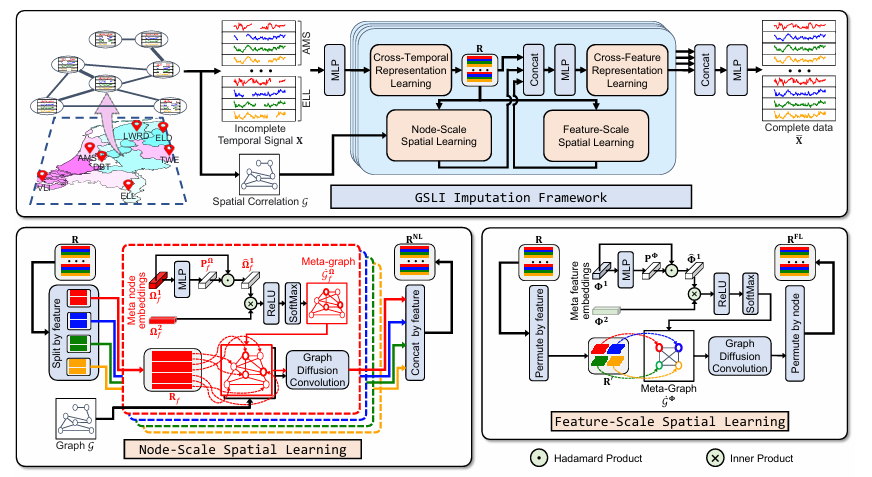
The framework used static graphs to symbolize spatial information and temporal indicators for time-based data, with lacking information indicated by masks. Node-scale studying refines embeddings utilizing meta-nodes to spotlight influential nodes, forming meta-graphs for feature-specific spatial dependencies. Characteristic-scale studying produces meta-graphs that seize spatial relations between options over nodes. This design tries to seize each cross-feature and cross-temporal dependencies however at the price of computational complexity.
Researchers evaluated the efficiency of GSLI utilizing an Intel Xeon Silver 4314 CPU and NVIDIA RTX 4090 GPU on six real-world spatial-temporal datasets with lacking values. Adjacency matrices had been constructed when not supplied, and lacking values missing floor fact had been excluded. Imputation accuracy was assessed utilizing RMSE and MAE metrics underneath varied lacking charges, together with MCAR, MAR, and MNAR. GSLI outperformed state-of-the-art strategies throughout all datasets by successfully capturing spatial dependencies by means of graph buildings. Its potential to mannequin cross-temporal and cross-feature dependencies enabled superior adaptability to numerous situations, with outcomes averaged over 5 trials demonstrating constant accuracy even with growing lacking charges or mechanisms.
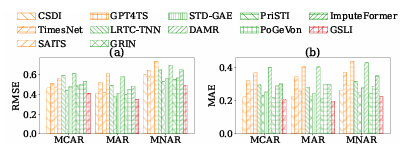
In conclusion, the proposed framework advances spatial-temporal imputation by addressing function heterogeneity and leveraging multi-scale graph construction studying to enhance accuracy. This work has thus proven, throughout six real-world datasets, that it performs higher than extra heuristic static spatial graph-based strategies and is strong to variations. This framework can act as a baseline for future analysis, inspiring developments that cut back computational complexity, deal with bigger datasets, and allow real-time imputation for dynamic methods.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.