LLMs face challenges in continuous studying as a result of limitations of parametric data retention, resulting in the widespread adoption of RAG as an answer. RAG allows fashions to entry new info with out modifying their inner parameters, making it a sensible strategy for real-time adaptation. Nevertheless, conventional RAG frameworks rely closely on vector retrieval, which limits their capability to seize advanced relationships and associations in data. Current developments have built-in structured knowledge, equivalent to data graphs, to boost reasoning capabilities, bettering sense-making and multi-hop connections. Whereas these strategies supply enhancements in contextual understanding, they usually compromise efficiency on less complicated factual recall duties, highlighting the necessity for extra refined approaches.
Continuous studying methods for LLMs usually fall into three classes: continuous fine-tuning, mannequin modifying, and non-parametric retrieval. Fantastic-tuning periodically updates mannequin parameters with new knowledge however is computationally costly and susceptible to catastrophic forgetting. Mannequin modifying modifies particular parameters for focused data updates, however its results stay localized. In distinction, RAG dynamically retrieves related exterior info at inference time, permitting for environment friendly data updates with out altering the mannequin’s parameters. Superior RAG frameworks, equivalent to GraphRAG and LightRAG, improve retrieval by structuring data into graphs, bettering the mannequin’s capability to synthesize advanced info. HippoRAG 2 refines this strategy by leveraging structured retrieval whereas minimizing errors from LLM-generated noise, balancing sense-making and factual accuracy.
HippoRAG 2, developed by researchers from The Ohio State College and the College of Illinois Urbana-Champaign, enhances RAG by bettering factual recall, sense-making, and associative reminiscence. Constructing upon HippoRAG’s Personalised PageRank algorithm, it integrates passages extra successfully and refines on-line LLM utilization. This strategy achieves a 7% enchancment in associative reminiscence duties over main embedding fashions whereas sustaining robust factual and contextual understanding. In depth evaluations present its robustness throughout numerous benchmarks, outperforming present structure-augmented RAG strategies. HippoRAG 2 considerably advances non-parametric continuous studying, bringing AI methods nearer to human-like long-term reminiscence capabilities.
HippoRAG 2 is a neurobiologically impressed long-term reminiscence framework for LLMs, enhancing the unique HippoRAG by bettering context integration and retrieval. It includes a synthetic neocortex (LLM), a parahippocampal area encoder, and an open data graph (KG). Offline, an LLM extracts triples from passages, linking synonyms and integrating conceptual and contextual info. On-line, queries are mapped to related triples utilizing embedding-based retrieval, adopted by Personalised PageRank (PPR) for context-aware choice. HippoRAG 2 introduces recognition reminiscence for filtering triples and deeper contextualization by linking queries to triples, enhancing multi-hop reasoning and bettering retrieval accuracy for QA duties.
The experimental setup consists of three baseline classes: (1) classical retrievers equivalent to BM25, Contriever, and GTR, (2) massive embedding fashions like GTE-Qwen2-7B-Instruct, GritLM-7B, and NV-Embed-v2, and (3) structure-augmented RAG fashions, together with RAPTOR, GraphRAG, LightRAG, and HippoRAG. The analysis spans three key problem areas: easy QA (factual recall), multi-hop QA (associative reasoning), and discourse understanding (sense-making). Metrics embrace passage recall@5 for retrieval and F1 scores for QA. HippoRAG 2, leveraging Llama-3.3-70B-Instruct and NV-Embed-v2, outperforms prior fashions, notably in multi-hop duties, demonstrating enhanced retrieval and response accuracy with its neuropsychology-inspired strategy.
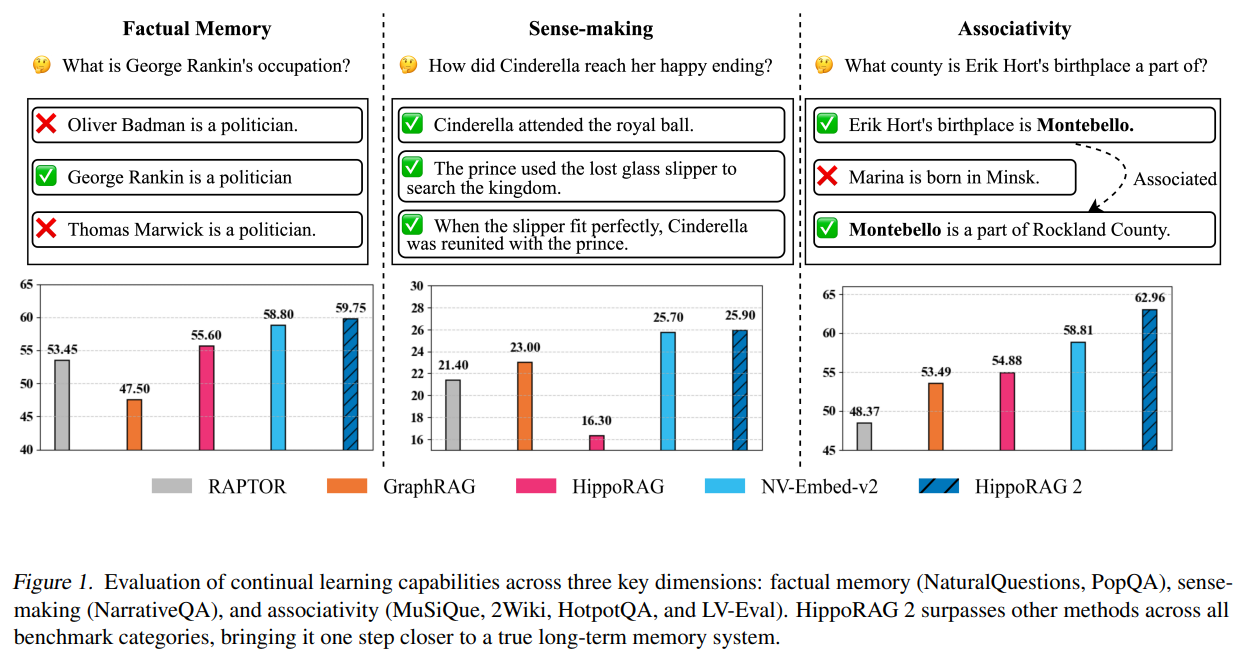
In conclusion, the ablation research evaluates the influence of linking, graph building, and triple filtering strategies, exhibiting that deeper contextualization considerably improves HippoRAG 2’s efficiency. The query-to-triple strategy outperforms others, enhancing Recall@5 by 12.5% over NER-to-node. Adjusting reset chances in PPR balances phrase and passage nodes, optimizing retrieval. HippoRAG 2 integrates seamlessly with dense retrievers, persistently outperforming them. Qualitative evaluation highlights superior multi-hop reasoning. Total, HippoRAG 2 enhances retrieval and reasoning by leveraging Personalised PageRank, deeper passage integration, and LLMs, providing developments in long-term reminiscence modeling. Future work could discover graph-based retrieval for improved episodic reminiscence in conversations.
Check out the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.
🚨 Really helpful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Handle Authorized Issues in AI Datasets
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.