Transformer architectures have revolutionized Pure Language Processing (NLP), enabling vital language understanding and technology progress. Massive Language Fashions (LLMs), which depend on these architectures, have achieved outstanding efficiency throughout varied functions akin to conversational programs, content material creation, and summarization. Nevertheless, the effectivity of LLMs in real-world deployment stays a problem attributable to their substantial useful resource calls for, significantly in duties requiring sequential token technology.
A crucial concern with LLMs lies of their inference velocity, which is constrained by the excessive reminiscence bandwidth necessities and sequential nature of auto-regressive technology (ARG). These limitations forestall LLMs from being successfully utilized in time-sensitive functions or on units with restricted computational capability, akin to private computer systems or smartphones. As customers more and more demand real-time processing and responsiveness, addressing these bottlenecks has turn out to be a precedence for researchers and trade practitioners.
One promising answer is Speculative Decoding (SD), a way designed to speed up LLM inference with out compromising generated output high quality. SD employs draft fashions to foretell token sequences, which the goal mannequin validates in parallel. Regardless of its potential, the adoption of SD has been hindered by the shortage of environment friendly draft fashions. These fashions should align with the goal LLM’s vocabulary and obtain excessive acceptance charges, a difficult requirement given the incompatibility points in current approaches.
Researchers at Intel Labs launched FastDraft, an environment friendly framework for coaching and aligning draft fashions appropriate with varied goal LLMs, together with Phi-3-mini and Llama-3.1-8B. FastDraft stands out by using a structured method to pre-training and fine-tuning. Pre-training focuses on processing datasets containing as much as 10 billion tokens of pure language and code whereas fine-tuning makes use of sequence-level information distillation to enhance draft-target alignment. This course of ensures that the draft fashions obtain optimum efficiency throughout various duties.
FastDraft’s structure imposes minimal necessities, permitting for flexibility in mannequin design whereas making certain compatibility with the goal LLM’s vocabulary. Throughout pre-training, the draft mannequin predicts the following token in a sequence, utilizing datasets like FineWeb for pure language and The Stack v2 for code. The alignment section employs artificial datasets generated by the goal mannequin, refining the draft mannequin’s capacity to imitate the goal mannequin’s habits. These methods be sure that the draft mannequin maintains excessive effectivity and accuracy.
The efficiency enhancements achieved by FastDraft are vital. As an illustration, the Phi-3-mini draft, skilled on 10 billion tokens, achieved a 67% acceptance charge with as much as a 3x memory-bound speedup in code duties. Equally, the Llama-3.1-8B draft mannequin demonstrated a 2x speedup in summarization and textual content completion duties. FastDraft enabled these draft fashions to be skilled on a single server outfitted with 8 Intel® Gaudi® 2 accelerators in lower than 24 hours. This effectivity makes FastDraft significantly appropriate for resource-constrained environments.
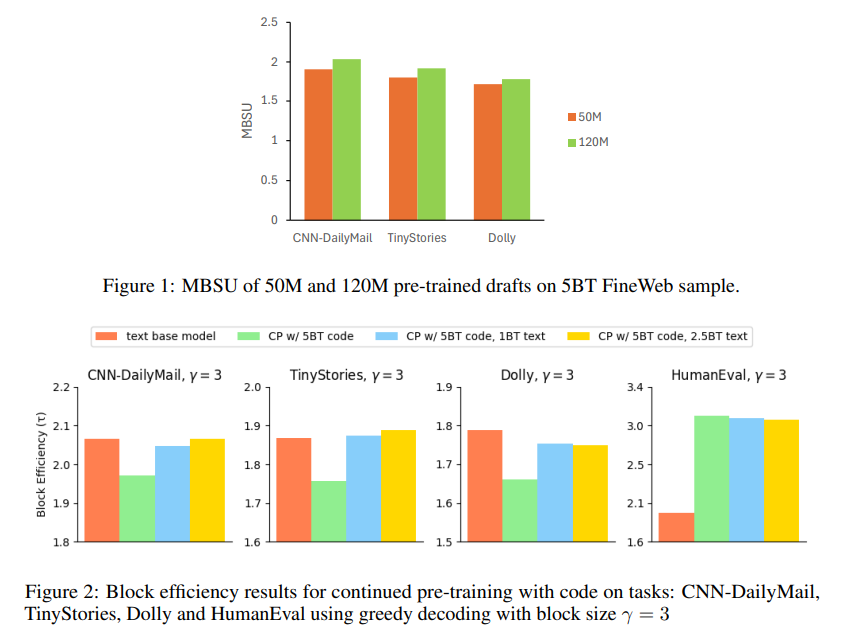
The analysis additionally gives priceless insights for future LLM draft mannequin coaching developments. Key takeaways embrace:
- Acceptance Fee Enhancements: FastDraft achieved a 67% acceptance charge for Phi-3-mini and over 60% for Llama-3.1-8B, reflecting efficient alignment with goal fashions.
- Coaching Effectivity: Coaching the draft fashions required lower than 24 hours on customary {hardware} setups, a notable discount in useful resource calls for.
- Scalability: The framework efficiently skilled fashions for varied duties, together with code completion and textual content summarization, utilizing datasets of as much as 10 billion tokens.
- Efficiency Positive factors: FastDraft delivered as much as a 3x memory-bound speedup in code duties and a 2x enchancment in summarization duties, considerably lowering runtime and reminiscence utilization.
- {Hardware} Adaptability: Benchmarked on Intel® Core™ Extremely processors, the draft fashions achieved substantial speedups whereas lowering reminiscence bandwidth calls for by as much as 3x.
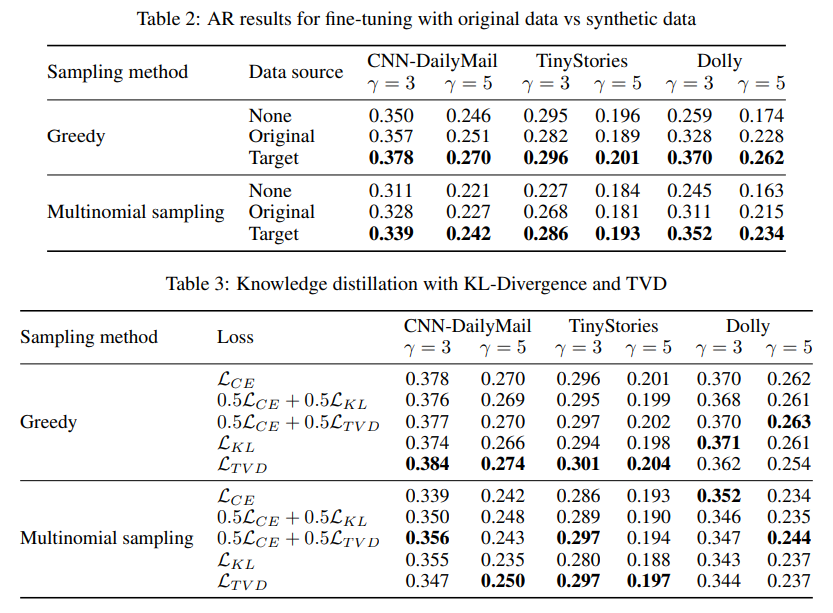

In conclusion, FastDraft addresses the crucial limitations of LLM inference by introducing a scalable, resource-efficient framework for coaching draft fashions. Its progressive strategies of pre-training and alignment considerably improve efficiency metrics, making it a sensible answer for deploying LLMs on edge units. FastDraft lays a robust basis for future developments in NLP know-how by demonstrating substantial enhancements in inference velocity and useful resource effectivity.
Check out the Paper, Model on Hugging Face, and Code on the GitHub Page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.