Multimodal massive language fashions (MLLMs) have emerged as a promising method in the direction of synthetic basic intelligence, integrating numerous sensing indicators right into a unified framework. Nonetheless, MLLMs face substantial challenges in elementary vision-related duties, considerably underperforming in comparison with human capabilities. Important limitations persist in object recognition, localization, and movement recall, presenting obstacles to complete visible understanding. Regardless of ongoing analysis and scaling efforts, a transparent pathway to attaining human-level visible comprehension stays elusive. The present work highlights the complexity of growing adaptive and clever multimodal programs that may interpret and motive throughout totally different sensory inputs with human-like precision and adaptability.
Present analysis on MLLMs has pursued a number of approaches to handle visible understanding challenges. Present methodologies mix imaginative and prescient encoders, language fashions, and connectors via instruction tuning, enabling complicated duties like picture description and visible question responses. Researchers have explored numerous dimensions together with mannequin structure, mannequin dimension, coaching corpus, and efficiency optimization. Video-capable MLLMs have proven capabilities in processing sequential visuals and comprehending spatiotemporal variations. Nonetheless, current strategies face important limitations in dealing with fine-grained visible duties resembling exact segmentation and temporal grounding, so two methods have emerged to sort out these challenges: the pixel-to-sequence (P2S) methodology, and the pixel-to-embedding (P2E) method.
Researchers from Shanghai AI Laboratory, Nanjing College, and Shenzhen Institutes of Superior Expertise, Chinese language Academy of Sciences have proposed a brand new model of InternVideo2.5, a novel method to enhance video MLLM via lengthy and wealthy context (LRC) modeling. It addresses limitations in perceiving fine-grained video particulars and capturing complicated temporal buildings. The proposed technique focuses on integrating dense imaginative and prescient job annotations into MLLMs utilizing direct choice optimization and growing compact spatiotemporal representations via adaptive hierarchical token compression. The researchers goal to develop the mannequin’s capabilities in video understanding, enabling extra strong efficiency throughout numerous benchmarks.
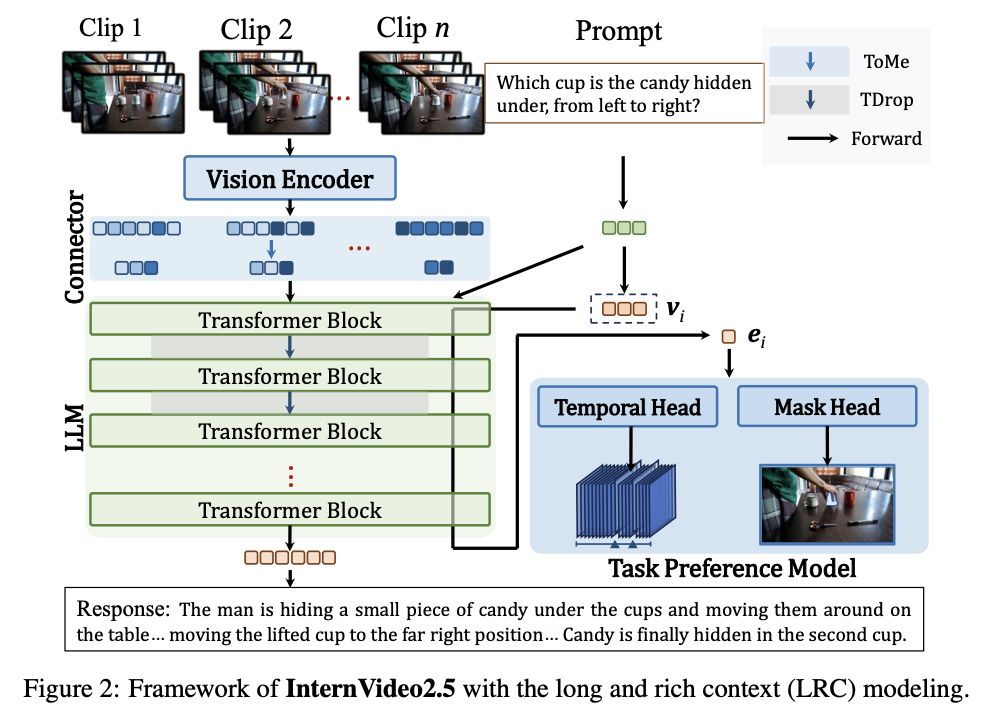
The proposed structure presents a posh multimodal framework that integrates superior video processing and language modeling methods. The system makes use of dynamic video sampling, processing between 64 to 512 frames, with every 8-frame clip compressed to 128 tokens, leading to 16 tokens per body illustration. Key architectural elements embody a Temporal Head primarily based on CG-DETR structure and a Masks Head using SAM2’s pre-trained weights. For temporal processing, the framework makes use of InternVideo2 for video characteristic extraction, with question options processed via the language mannequin. The system implements two-layer MLPs for positioning prompts and spatial enter encoding into the multimodal language mannequin to optimize spatiotemporal capabilities.
InternVideo2.5 demonstrates exceptional efficiency throughout video understanding benchmarks briefly and lengthy video question-answering duties. In comparison with its base mannequin InternVL2.5, the proposed method reveals important enhancements, with notable will increase of over 3 factors on MVBench and Notion Check for brief video predictions. InternVideo2.5 reveals superior efficiency in short-duration spatiotemporal understanding, in comparison with fashions like GPT4-o and Gemini-1.5-Professional. The Needle-In-The-Haystack (NIAH) analysis additional validates the mannequin’s enhanced implicit reminiscence capabilities, efficiently displaying superior recall in a posh 5,000-frame single-hop job.
In conclusion, researchers launched a brand new model of InternVideo2.5, a novel video MLLM designed to boost notion and understanding via lengthy and wealthy context (LRC) modeling. The tactic makes use of direct choice optimization to switch dense visible annotations and adaptive hierarchical token compression for environment friendly spatiotemporal illustration. The analysis highlights important enhancements in visible capabilities, together with object monitoring, and underscores the essential significance of multimodal context decision in advancing MLLM efficiency. Nonetheless, the research reveals limitations resembling excessive computational prices and the necessity for additional analysis in extending context processing methods, presenting thrilling alternatives for future investigation within the multimodal AI discipline.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)

Sajjad Ansari is a last yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.