Reinforcement studying (RL) has essentially reworked AI by permitting fashions to enhance efficiency iteratively via interplay and suggestions. When utilized to massive language fashions (LLMs), RL opens new avenues for dealing with duties that require advanced reasoning, similar to mathematical problem-solving, coding, and multimodal information interpretation. Conventional strategies rely closely on pretraining with massive static datasets. Nonetheless, their limitations have change into evident as fashions clear up issues that require dynamic exploration and adaptive decision-making.
A essential problem in advancing LLMs lies in scaling their capabilities whereas making certain computational effectivity. Based mostly on static datasets, typical pretraining approaches battle to satisfy the calls for of advanced duties involving intricate reasoning. Additionally, current LLM RL implementations have did not ship state-of-the-art outcomes as a consequence of inefficiencies in immediate design, coverage optimization, and information dealing with. These shortcomings have left a niche in growing fashions able to performing nicely throughout various benchmarks, particularly these requiring simultaneous reasoning over textual content and visible inputs. Fixing this downside necessitates a complete framework that aligns mannequin optimization with task-specific necessities whereas sustaining token effectivity.
Prior options for enhancing LLMs embody supervised fine-tuning and superior reasoning methods similar to chain-of-thought (CoT) prompting. CoT reasoning permits fashions to interrupt down issues into intermediate steps, enhancing their capability to sort out advanced questions. Nonetheless, this technique is computationally costly and infrequently constrained by conventional LLMs’ restricted context window dimension. Equally, Monte Carlo tree search, a preferred method for reasoning enhancement, introduces extra computational overhead and complexity. The absence of scalable RL frameworks for LLMs has additional restricted progress, underscoring the necessity for a novel strategy that balances efficiency enhancements with effectivity.
Researchers from the Kimi Crew have launched Kimi k1.5, a next-generation multimodal LLM designed to beat these challenges by integrating RL with prolonged context capabilities. This mannequin employs progressive methods similar to long-context scaling, which expands the context window to 128,000 tokens, enabling it to course of bigger downside contexts successfully. In contrast to prior approaches, the Kimi k1.5 avoids counting on advanced strategies like Monte Carlo tree search or worth capabilities, choosing a streamlined RL framework. The analysis staff carried out superior RL immediate set curation to reinforce the mannequin’s adaptability, together with various prompts spanning STEM, coding, and basic reasoning duties.
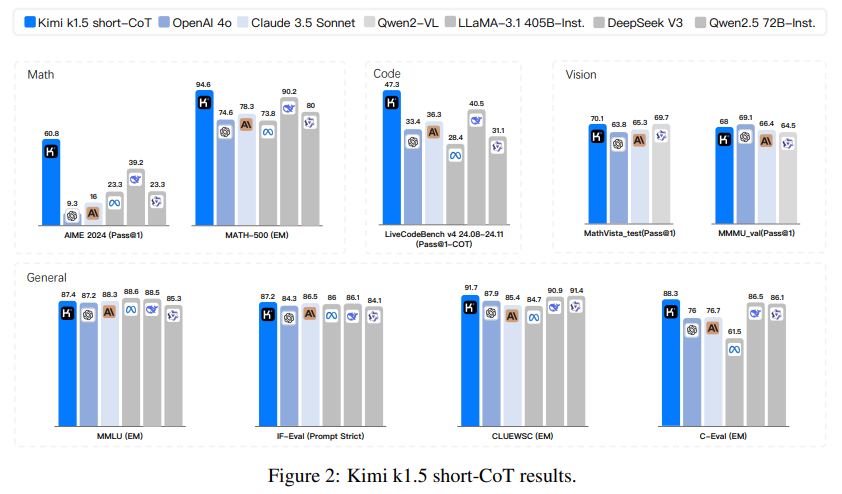
The Kimi k1.5 was developed in two variations:
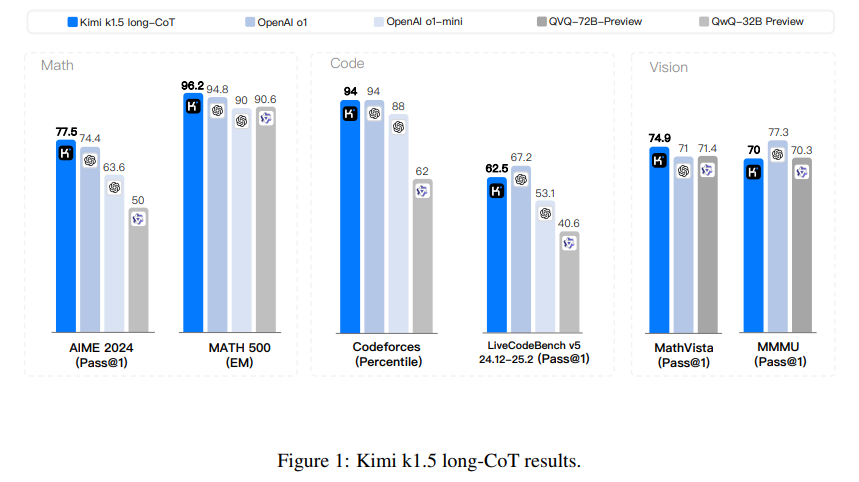
- The long-CoT mannequin: It excels in prolonged reasoning duties, leveraging its 128k-token context window to attain groundbreaking outcomes throughout benchmarks. As an illustration, it scored 96.2% on MATH500 and 94th percentile on Codeforces, demonstrating its capability to deal with advanced, multi-step issues.
- The short-CoT mannequin: The short-CoT mannequin was optimized for effectivity utilizing superior long-to-short context coaching strategies. This strategy efficiently transferred reasoning priors from the long-CoT mannequin, permitting the short-CoT mannequin to take care of excessive efficiency, 60.8% on AIME and 94.6% on MATH500, whereas considerably lowering token utilization.
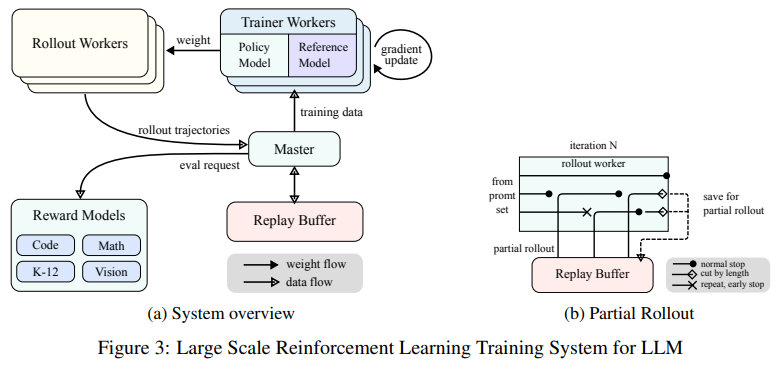
The coaching course of mixed supervised fine-tuning, long-chain reasoning, and RL to create a sturdy framework for problem-solving. Key improvements included partial rollouts, a way that reuses beforehand computed trajectories to enhance computational effectivity throughout long-context processing. Utilizing multimodal information sources, similar to real-world and artificial visible reasoning datasets, additional strengthened the mannequin’s capability to interpret and motive throughout textual content and pictures. Superior sampling methods, together with curriculum and prioritized sampling, ensured coaching targeted on areas the place the mannequin demonstrated weaker efficiency.
Kimi k1.5 demonstrated vital enhancements in token effectivity via its long-to-short context coaching methodology, enabling the switch of reasoning priors from long-context fashions to shorter fashions whereas sustaining excessive efficiency and lowering token consumption. The mannequin achieved distinctive outcomes throughout a number of benchmarks, together with a 96.2% actual match accuracy on MATH500, a 94th percentile on Codeforces, and a cross fee of 77.5% on AIME, surpassing state-of-the-art fashions like GPT-4o and Claude Sonnet 3.5 by substantial margins. Its short-CoT efficiency outperformed GPT-4o and Claude Sonnet 3.5 on benchmarks like AIME and LiveCodeBench by as much as 550%, whereas its long-CoT efficiency matched o1 throughout a number of modalities, together with MathVista and Codeforces. Key options embody long-context scaling with RL utilizing context home windows of as much as 128k tokens, environment friendly coaching via partial rollouts, improved coverage optimization through on-line mirror descent, superior sampling methods, and size penalties. Additionally, Kimi k1.5 excels in joint reasoning over textual content and imaginative and prescient, highlighting its multi-modal capabilities.
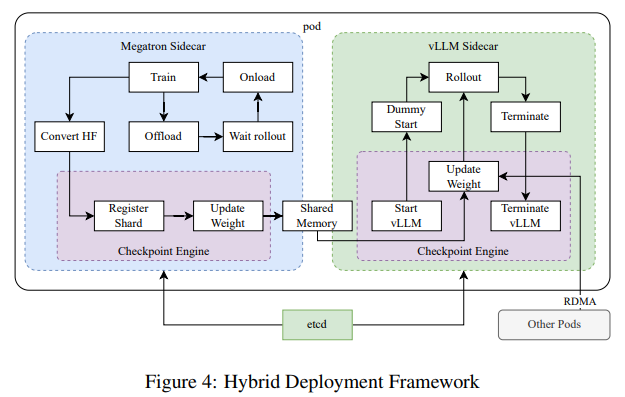
The analysis introduced a number of key takeaways:
- By enabling fashions to discover dynamically with rewards, RL removes the constraints of static datasets, increasing the scope of reasoning and problem-solving.
- Utilizing a 128,000-token context window allowed the mannequin to successfully carry out long-chain reasoning, a vital consider its state-of-the-art outcomes.
- Partial rollouts and prioritized sampling methods optimized the coaching course of, making certain assets have been allotted to essentially the most impactful areas.
- Incorporating various visible and textual information enabled the mannequin to excel throughout benchmarks requiring simultaneous reasoning over a number of enter varieties.
- The streamlined RL framework utilized in Kimi k1.5 averted the pitfalls of extra computationally demanding methods, reaching excessive efficiency with out extreme useful resource consumption.
In conclusion, the Kimi k1.5 addresses the restrictions of conventional pretraining strategies and implements progressive methods for context scaling and token effectivity; the analysis units a brand new benchmark for efficiency throughout reasoning and multimodal duties. The long-CoT and short-CoT fashions collectively showcase the adaptability of Kimi k1.5, from dealing with advanced, prolonged reasoning duties to reaching token-efficient options for shorter contexts.
Try the Paper and GitHub Page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 65k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.